| |
| chp2.數據資料視覺化1(Matplotlib模組) |
| 目錄 |
1.Matplotli介紹 |
Matplotlib常用繪圖的基本語法 |
範例2-1:畫出(y)串列數據scatter散佈圖 |
範例2-2:繪圖(x,y)串列數據 |
|
範例2-3:繪出紅色色虛線(x,y)圖 |
6.plt.plot參數> |
範例2-4:繪圖兩條線 |
範例2-5:繪柱狀圖:兩條線 |
|
範例2-6:圓餅圖(plt.pie) |
範例2-7:總共3個圖,上面一個,下面兩個分割圖 |
<範例2-8:結合numpy與matplotlib的繪圖,畫出三條線 |
範例2-9:結合pandas 與 matplotlib畫圖股票線圖 |
1.Matplotli介紹 |
1.Matplotli介紹:
(1)Python資料視覺化主要有四大套件:
Matplotlib
Seaborn
Plotly
Pandas
(2)Matplotli
Matplotlib 是 Python 的繪圖庫。 它可與 NumPy 一起使用,提供了一種有效的 MatLab 開源替代方案。
Matplotlib. 它能幫你畫出美麗的:
線圖;
散點圖(scatter散佈圖)(plt.plot)
等高線圖;
橫條圖;
柱狀圖;(plt.bar)
3D 圖形,
甚至是圖形動畫等等.
(3)優缺點
A).優點:
相較於其他視覺化套件,matplot算是最歷史悠久,因此有很多的教學文章或是範例可參考
畫圖功能最齊全,基本上沒什麼圖表畫不出來的
B).缺點:
圖表美觀度普通
畫圖指令複雜
|
matplotlib常用繪圖的基本語法 |
常用繪圖的基本語法:
(1)畫出一條紅色線條:
import matplotlib.pyplot as plt
x = [1,2,3,4,5]
y = [9,3,5,6,2]
plt.plot(x,y,'r-')
plt.show()
(2)畫出二條線,紅色藍色
第一種寫法:
import matplotlib.pyplot as plt
x = [1,2,3,4,5]
y1 = [9,3,5,6,2]
y2 = [8,2,8,5,1]
plt.plot(x,y1,'r-')
plt.plot(x,y2,'r-')
plt.show()
第二種寫法:
import matplotlib.pyplot as plt
x = [1,2,3,4,5]
y1 = [9,3,5,6,2]
y2 = [8,2,8,5,1]
plt.plot(x,y1,'color=red',linestyle='-',label='y1')
plt.plot(x,y2,'color=blue',linestyle='--',label='y2')
plt.show()
(3)顯示x軸,y軸名稱,顯示圖例legend,顯示軸刻度,線寬度
import matplotlib.pyplot as plt
x = [1,2,3,4,5]
y1 = [9,3,5,6,2]
y1 = [8,2,8,5,1]
plt.plot(x,y1,'color=red',linestyle='-',label='y1',linewidth=1)
plt.plot(x,y2,'color=blue',linestyle='--',label='y2',linewidth=3)
#標題
plt.title('Pocket Money')
plt.xlabel('Age')
plt.ylabel('Money')
#x軸,y軸範圍
plt.xlim(0,7)
plt.ylim(0,10)
#顯示圖例標籤
plt.legend()
plt.show()
(4)畫出左右兩個圖:
import matplotlib.pyplot as plt
x = [1,2,3,4]
y = [2,4,6,8]
#左半部,紅色,圓點圖
#上下1個,左右2個,在第1個位置:subplot(1,2,1)
plt.subplot(1,2,1)
plt.plot(x,y,'ro')
#右半部,實線,綠色圖
#上下1個,左右2個,在第2個位置:subplot(1,2,2)
plt.subplot(1,2,2)
plt.plot(x,y,'g-')
plt.show()
|
範例2-1:畫出(y)串列數據scatter散佈圖 |
2.散點圖,scatter散佈圖:plt.plot
基本指令
(1)範例2-1:畫出(y)串列數據scatter散佈圖
import matplotlib.pyplot as plt
plt.plot([1,2,3,4,5,6])
plt.show()
成果圖示: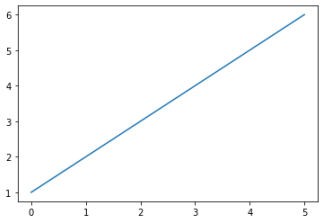
程式碼內容
#注意:繪圖不會顯示在console視窗,而是顯示在plots視窗
(2)說明
要先輸入matplotlib.pyplot as plt。
如果要畫折線圖使用 plt.plot,
一開始先只放一個串列參數[1,2,3,4],這樣只會有y的資料,x會是預設的0,1,2,3…。
顯示出圖片需要加上.show(),否則只會顯示出這樣的訊息[]
|
範例2-2:繪圖(x,y)串列數據 |
3.範例2-2:繪圖(x,y)串列數據
import matplotlib.pyplot as plt
listx = [1,3,4,6,8,11,13,15,17]
listy = [20,45,30,42,50,60,90,80,100]
plt.plot(listx,listy)
plt.show()
成果圖示: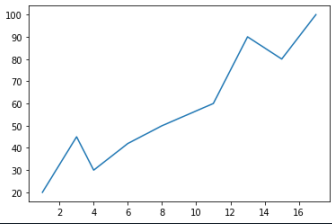
程式碼內容
|
範例2-3:繪出紅色色虛線(x,y)圖/p> |
4.範例2-3:繪出紅色色虛線(x,y)圖
import matplotlib.pyplot as plt
listx = [1,3,4,6,8,11,13,15,17]
listy = [20,45,30,42,50,60,90,80,100]
plt.plot(listx,listy,color='red',linestyle='--')
#plt.plot(listx,listy,'r--')
plot.show()
成果圖示: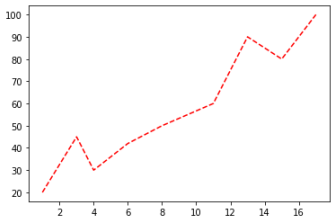
程式碼內容
|
6.plt.plot參數 |
6.plt.plot參數
(1)linewidth:lw:可以用來設定圖形中線條的粗細(例如:lw = 3)
(2)color:設定線的顏色:(例如:color=red)
olive(橄欖綠)
lime(萊姆綠)
teal(藍綠色)
indigo(深紫色)
plum(紫紅色)
lavender(薰衣草紫)
pink(粉紅色)
表示顏色的字元參數有:
字元 顏色
‘b’ 藍色,blue
‘g’ 綠色,green
‘r’ 紅色,red
‘c’ 青色,cyan
‘m’ 品紅,magenta
‘y’ 黃色,yellow
‘k’ 黑色,black
‘w’ 白色,white
(3)linestyle:ls:設定線條的style(例如:ls = '--'虛線)
表示類型的字元參數有:
字元 類型
'-' 實線
'--' 虛線
'-.' 虛點線
':' 點線
'.' 點
',' 圖元點
'o' 圓點
'v' 下三角點
'^' 上三角點
'<' 左三角點
'>' 右三角點
'1' 下三叉點
'2' 上三叉點
'3' 左三叉點
'4' 右三叉點
's' 正方點
'p' 五角點
'*' 星形點
'h' 六邊形點1
'H' 六邊形點2
'+' 加號點
'x' 乘號點
'D' 實心菱形點
'd' 瘦菱形點
'_' 橫線點
(4)顯示範圍
設定x軸範圍:plt.xlim(0,20)
設定y軸範圍:plt.ylim(0,100)
與 MATLAB 類似,這裡可以使用 axis 函數指定坐標軸顯示的範圍:
plt.axis([xmin, xmax, ymin, ymax])
(5)設定圖形標題(上方中央):plt.title('Pocket Money')
設定x軸標題(下方中央):plt.xlabel('Age')
設定y軸標題(左方中央):plt.ylabel('Money')
(6)顯示圖例標籤label名稱(例如:Male,Female)
plt.plot(listx,listy,'color=blue',linestyle='--',label='Female')
plt.legend()
|
範例2-4:繪圖兩條線,藍色實線寬5,紅色點線寬10 |
6.範例2-4:繪圖兩條線,藍色實線寬5,紅色點線寬10
import matplotlib.pyplot as plt
#第一組數據
listx = [1,3,4,6,8,11,13,15,17]
listy = [20,45,30,42,50,60,90,80,100]
plt.plot(listx,listy,color='blue',linestyle='-',linewidth=5,label='Male')
#第二組數據
listx = [1,2,4,6,9,11,13,14,17]
listy = [30,52,45,40,30,40,70,65,45]
plt.plot(listx,listy,color='red',linestyle=':',linewidth=10,label='Female')
#標題
plt.title('Pocket Money')
plt.xlabel('Age')
plt.ylabel('Money')
#x軸,y軸範圍
plt.xlim(0,20)
plt.ylim(0,100)
#圖例標籤
plt.legend()
#顯示
plt.show()
傳入 Numpy 陣列
之前我們傳給 plot 的參數都是列表,事實上,向 plot 中傳入 numpy 陣列是更常用的做法。事實上,如果傳入的是列表,matplotlib 會在內部將它轉化成陣列再進行處理:
成果圖示: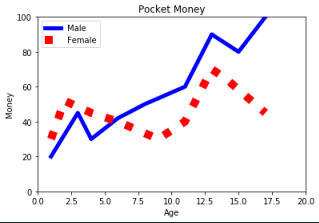
程式碼內容
|
範例2-5:繪柱狀圖:兩條線,藍色實線寬5,紅色點線寬10 |
7.柱狀圖(plt.bar)
範例2-5:繪柱狀圖:兩條線,藍色實線寬5,紅色點線寬10
import matplotlib.pyplot as plt
#第一組數據
listx = [1,3,5,7,9,11,13,15,17]
listy = [20,45,30,42,50,60,90,80,100]
plt.bar(listx,listy,color='blue',linestyle='-',linewidth=5,label='Male')
#第二組數據
listx = [2,4,6,8,10,12,14,16,18]
listy = [30,52,45,40,30,40,70,65,45]
plt.bar(listx,listy,color='red',linestyle=':',linewidth=10,label='Female')
#標題
plt.title('Pocket Money')
plt.xlabel('Age')
plt.ylabel('Money')
#x軸,y軸範圍
plt.xlim(0,20)
plt.ylim(0,100)
#圖例標籤
plt.legend()
#顯示
plt.show()
成果圖示: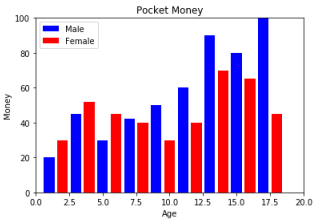
程式碼內容
|
範例2-6:圓餅圖(plt.pie)顯示春夏秋冬四季的業績% |
8.圓餅圖(plt.pie)
#範例2-6:圓餅圖(plt.pie)顯示春夏秋冬四季的業績%
import matplotlib.pyplot as plt
mydata = [25000,50000,35000,20000]
mylabel = ['spring','summer','fall','winter']
myexplode = [0, 0.1, 0, 0]
mycolor = ['green','red','yellow','lightblue']
plt.pie(mydata,explode=myexplode,labels=mylabel,colors=mycolor,autopct='%3.1f%%', pctdistance=0.6, shadow = True, labeldistance= 1.1)
plt.axis('equal')
plt.legend()
plt.show()
#說明:
# 指定圓餅圖的顏色:colors = mycolor,
# 分類的標記:labels = mylabels,
# 四捨五入至小數點後面位數:autopct = "%3.1f%%",
# 設定分隔的區塊項目是否凸出(不凸出為0):explode = myexplode,
# 數值顯示位置與圓餅圖的圓心距離:pctdistance = 0.6,
# 圓餅圖的半徑,預設是1:radius = 0.7,
# 圓餅圖的圓心座標:center = (-10,0),
# 是否使用陰影:shadow = True
#項目標題與圓心的距離是半徑的幾倍:labeldistance= 1.1
成果圖示: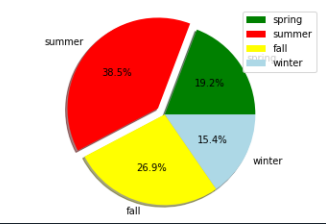
程式碼內容
|
範例2-7:總共3個圖,上面一個,下面兩個分割圖 |
9.切割圖
#範例2-7:總共3個圖,上面一個,下面兩個分割圖
import matplotlib.pyplot as plt
x = [1,2,3,4]
y = [2,4,6,8]
#上半部,紅色,圓點圖
plt.subplot(2,1,1,facecolor='y')
plt.plot(x,y,'ro')
#左下角,三角點,黑色圖
plt.subplot(2,2,3,facecolor='lightblue')
plt.plot(x,y,'k^')
#右下角,實線,綠色圖
plt.subplot(2,2,4)
plt.plot(x,y,'g-')
#說明:
#左右2個,上下1個,在第1個位置:subplot(2,1,1)
#左右2個,上下2個,在第3個位置:subplot(2,2,3)
#左右2個,上下2個,在第4個位置:subplot(2,2,4)
成果圖示: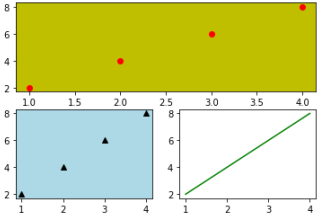
程式碼內容
|
範例2-8:結合numpy與matplotlib的繪圖,畫出三條線 |
10.結合numpy與matplotlib的繪圖,畫出三條線(y=x,y=x^2, y=x^3)
#範例2-8:結合numpy與matplotlib的繪圖,畫出三條線(y=x,y=x^2, y=x^3)
import matplotlib.pyplot as plt
import numpy as np
# 從0~5,每隔0.01取一個點當作x
x = np.arange(0,5,0.01)
# y = x
plt.plot(x,x,'r-')
# y = x^2
plt.plot(x,x*x,'b:')
# y = x^3
plt.plot(x,x*x*x,'g--')
plt.show()
成果圖示: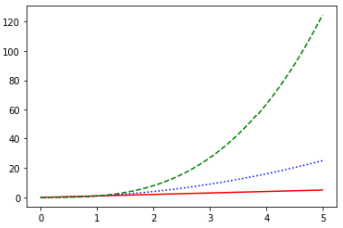
程式碼內容
|
範例2-9:結合pandas 與 matplotlib畫圖股票線圖(讀取AAPL.xlsx股票檔案) |
13.範例2-9:畫圖股票線圖(讀取AAPL.xlsx股票檔案)
#使用Matplotlib模組
#結合pandas 與 matplotlib = df.plot(x='..',y='..',color='red')
import pandas as pd
import matplotlib.pyplot as plt
#畫圖-line:Date vs Close (預設 kind= line)
df = pd.read_excel('AAPL.xlsx','AAPL')
#plt.plot([1,2,3,4,5,6])
df.plot(x='Date', y='Close',grid=True, color='red',label='Close')
#df.plot(x=df['Date'], y=df['Close'],grid=True, color='red')
plt.show()
#畫圖-bar:Date vs Close (kind= scatter)
#line線圖,bar柱狀圖,scatter散佈圖,bar水平柱狀圖,hist直方圖,box盒鬚圖
df.plot(x='Date', y='Close',grid=True, color='red',label='Close',kind='scatter')
plt.show()
#在同一圖fig,同一個軸ax,畫出三條線(Open,Close,High)
labels = ['Open','Close','High']
fig,ax = plt.subplots()
for name in labels:
df.plot(x='Date',y=name, ax=ax, label=name)
plt.show()
成果圖示: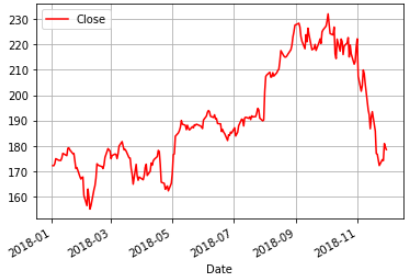
成果圖示: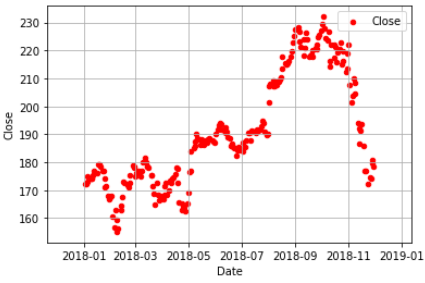
成果圖示: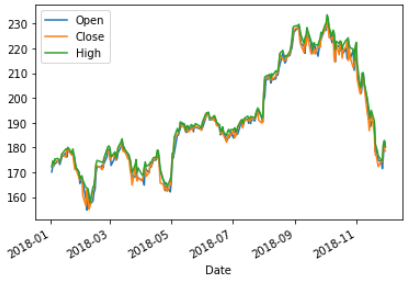
程式碼內容
| |
| |
| chp3.數據資料視覺化2(Pandas模組) |
| 範例3-1:繪圖(y=x^2)串列數據 |
範例3-2:繪圖(x,y)串列數據 |
3.pandas.DataFrame.plot( ) |
範例3-3:繪出紅色虛線,線寬4(x,y)圖 |
範例3-4:從DataFrame資料裡面取出num_children vs num_pets來繪圖 |
| 範例3-5:如何把兩組線條同時畫在同一張圖上 |
範例3-6:如何把圖形存檔成p3-6.png |
範例3-7:統計同一州的人數柱狀圖顯示 |
範例3-8:統計同一州人的性別柱狀堆疊圖顯示 |
範例3-9:印出四位學生的三科成績 |
範例3-1:繪圖(y=x^2)串列數據 |
1.範例3-1:繪圖(y=x^2)串列數據
#範例3-1:繪圖(y=x^2)串列數據
import pandas as pd
dataframe = pd.DataFrame([1,4,9,16,25,36])
dataframe.plot(kind='line',title='y=x^2')
成果圖示: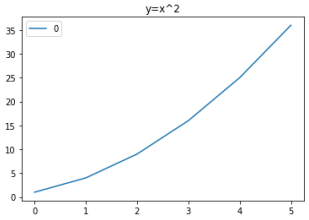
程式碼內容
|
範例3-2:繪圖(x,y)串列數據 |
2.範例3-2:繪圖(x,y)串列數據
import pandas as pd
listx = [1,3,4,6,8,11,13,15,17]
listy = [20,45,30,42,50,60,90,80,100]
df = pd.DataFrame(listx,listy)
df.plot(kind='line',title='drawing list(x,y)')
成果圖示: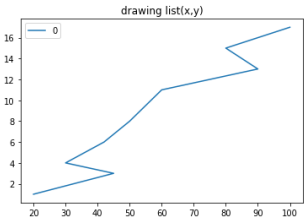
程式碼內容
|
3.pandas.DataFrame.plot( ) |
3.pandas.DataFrame.plot( )
(1)畫圖函數
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None,figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
xerr=None,secondary_y=False, sort_columns=False, **kwds)
(2)kind種類:
‘line’ : line plot (default)#折線圖
‘bar’ : vertical bar plot#橫條圖
‘barh’ : horizontal bar plot#橫向橫條圖
‘hist’ : histogram#柱狀圖
‘box’ : boxplot#箱線圖
‘kde’ : Kernel Density Estimation plot#Kernel 的密度估計圖,主要對柱狀圖添加Kernel 概率密度線
‘density’ : same as ‘kde’
‘area’ : area plot#不瞭解此圖
‘pie’ : pie plot#圓形圖
‘scatter’ : scatter plot#散點圖 需要傳入columns方向的索引
‘hexbin’ : hexbin plot#不瞭解此圖
|
範例3-3:繪出紅色虛線,線寬4(x,y)圖 |
3.範例3-3:繪出紅色虛線,線寬4(x,y)圖
import pandas as pd
listx = [1,3,4,6,8,11,13,15,17]
listy = [20,45,30,42,50,60,90,80,100]
df = pd.DataFrame(listy,listx)
df.plot(kind='line',title='red dash line',legend=False,color='red',linestyle='--',linewidth=4)
成果圖示: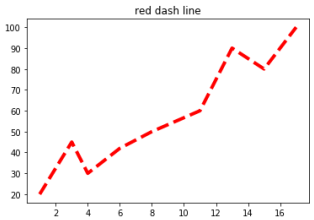
程式碼內容
|
範例3-4:從DataFrame資料裡面取出num_children vs num_pets來繪scatter圖,bar圖 |
4.範例3-4:從DataFrame資料裡面取出num_children vs num_pets來繪scatter圖,bar圖
#散佈圖scatter指令: df.plot(kind='scatter',x='...',y='..')
#柱狀圖bar指令: df.plot(kind='bar',x='...',y='..')
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','jeff','bill','lisa','jose'],
'age':[23,78,22,19,45,33,20],
'gender':['M','F','M','M','M','F','M'],
'state':['california','dc','california','dc','california','texas','texas'],
'num_children':[2,0,0,3,2,1,4],
'num_pets':[5,1,0,5,2,2,3]
})
#顯示每人寵物數量
df.plot(kind='scatter',x='name',y='num_pets',color='red')
#顯示年齡分佈
df.plot(kind='scatter', x='name', y='age',color='blue')
#顯示每人的小孩數量(scatter)
df.plot(kind='scatter',x='name', y='num_children',color='green')
#顯示每人的小孩數量(柱狀圖 bar)
df.plot(kind='bar',x='name',y='num_children',color='green')
成果圖示: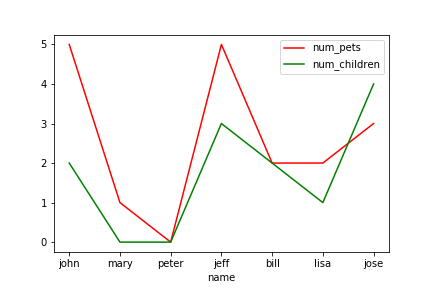
程式碼內容
|
範例3-5:如何把兩組線條同時畫在同一張圖上 |
5.範例3-5:如何把兩組線條同時畫在同一張圖上
#從DataFrame資料裡面取出num_children vs num_pets來繪圖
#原理:先取得目前顯示圖figure的座標軸 ax1 = plt.gca()
#注意:這個取得座標軸ax1的方法,是在matplotlib.pyplot函數庫裡面,必須先import
#然後圖1:df.plot(ax=ax1....)
#然後圖2:df.plot(ax=ax1....)
#最後用:matplotlib的plt.plot()繪出
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
'name':['john','mary','peter','jeff','bill','lisa','jose'],
'age':[23,78,22,19,45,33,20],
'gender':['M','F','M','M','M','F','M'],
'state':['california','dc','california','dc','california','texas','texas'],
'num_children':[2,0,0,3,2,1,4],
'num_pets':[5,1,0,5,2,2,3]
})
# gca 代表取得目figure前坐標軸 axis(gca = get current figure)
ax1 = plt.gca()
#顯示每人寵物數量(座標軸 = ax1)
df.plot(ax=ax1, kind='line',x='name',y='num_pets',color='red')
#顯示每人的小孩數量(座標軸 = ax1)
df.plot(ax=ax1, kind='line',x='name', y='num_children',color='green')
#兩個圖組,一起繪出
plt.show()
成果圖示: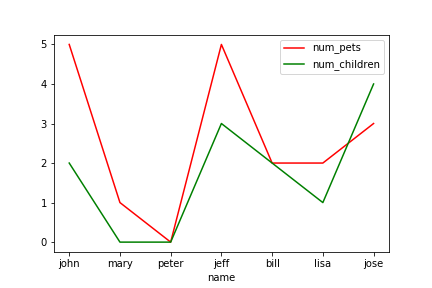
程式碼內容
|
範例3-6:如何把圖形存檔成p3-6.png |
6.範例3-6:如何把圖形存檔成p3-6.png
#指令:plt.savefig('p3-6.png')
#注意:這是matplotlib.pyplot函數庫指令,故必須先import
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
'name':['john','mary','peter','jeff','bill','lisa','jose'],
'age':[23,78,22,19,45,33,20],
'gender':['M','F','M','M','M','F','M'],
'state':['california','dc','california','dc','california','texas','texas'],
'num_children':[2,0,0,3,2,1,4],
'num_pets':[5,1,0,5,2,2,3]
})
# gca 代表取得目figure前坐標軸 axis(gca = get current figure)
ax1 = plt.gca()
#顯示每人寵物數量(座標軸 = ax1)
df.plot(ax=ax1, kind='line',x='name',y='num_pets',color='red')
#顯示每人的小孩數量(座標軸 = ax1)
df.plot(ax=ax1, kind='line',x='name', y='num_children',color='green')
#兩個圖組,一起存檔
#plt.show()
plt.savefig('p3-6.png')
成果圖示: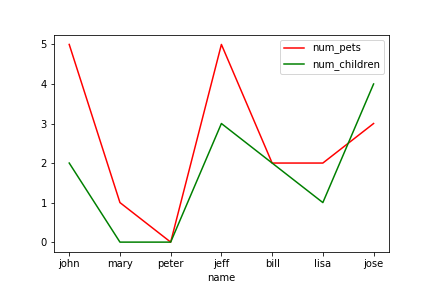
程式碼內容
|
範例3-7:統計同一州的人數柱狀圖顯示 |
6.範例3-7:統計同一州的人數柱狀圖顯示(state vs name)Bar plot with group by
#指令:df.groupby('state')['name'].nunique().plot(kind='bar')
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','jeff','bill','lisa','jose'],
'age':[23,78,22,19,45,33,20],
'gender':['M','F','M','M','M','F','M'],
'state':['california','dc','california','dc','california','texas','texas'],
'num_children':[2,0,0,3,2,1,4],
'num_pets':[5,1,0,5,2,2,3]
})
df.groupby('state')['name'].nunique().plot(kind='bar')
成果圖示: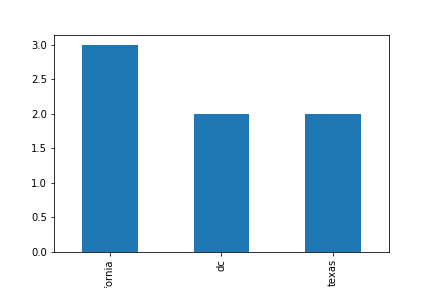
程式碼內容
|
範例3-8:統計同一州人的性別柱狀堆疊圖顯示 |
7.範例3-8:統計同一州人的性別柱狀堆疊圖顯示(Stacked堆疊 bar plot with two-level group by)
#指令:df.groupby(['state','gender']).size().unstack().plot(kind='bar',stacked=True)
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','jeff','bill','lisa','jose'],
'age':[23,78,22,19,45,33,20],
'gender':['M','F','M','M','M','F','M'],
'state':['california','dc','california','dc','california','texas','texas'],
'num_children':[2,0,0,3,2,1,4],
'num_pets':[5,1,0,5,2,2,3]
})
df.groupby(['state','gender']).size().unstack().plot(kind='bar',stacked=True)
成果圖示: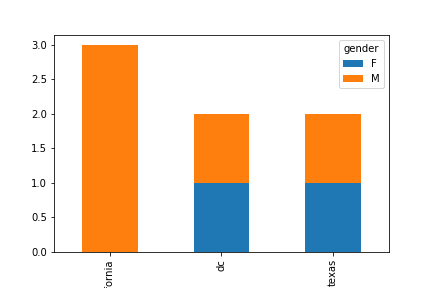
程式碼內容
|
範例3-9:印出四位學生的三科成績 |
8.範例3-9:印出四位學生的三科成績
import pandas as pd
#數據資料表,採用三個串列List(coulumn=course,record_name=name, record_data = score)
score = [[75,85,95],[90,90,90],[65,55,60],[95,65,90]]
name = ['tom','john','peter','jolin']
course = ['chinese','english','math']
#設定dataFrame設定資料結構
df = pd.DataFrame(score, index = name, columns = course)
#繪line線條圖
df.plot(kind='line',title='score of students')
#繪bar柱狀圖
df.plot(kind='bar',title='score of students')
成果圖示: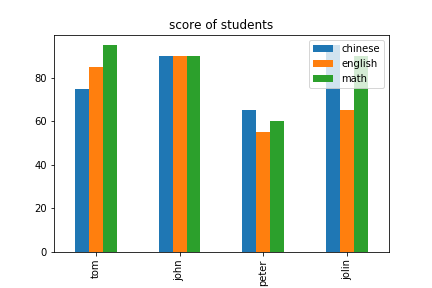
程式碼內容
|
| |
| |
| chp4.數據資料視覺化3(plotly,Plotly-Express模組)Containers |
| 1.Plotly,Plotly-Express簡介Containers |
2.Plotly,Plotly-Express功能 |
3.Python-Plotly 安裝 |
4.顯示結果的方法有兩種 |
範例4-1:Plotly-Express的結構與指令 |
| 範例4-2:(使用low-level plotly方法)使用Dictionary字典數據來畫圖 |
範例4-3:(使用top-level plotly方法:plotly.graph_objects)畫出y=[1,3,2]的bar圖 |
範例4-4:顯示兩個分割圖形 |
範例4-5:顯示兩個分割圖形(方法2 |
範例4-6:在分割圖形新增圖形 |
| 範例4-7:express顯示四位學生的總成績 |
範例4-8:express同時畫出三條圖 |
範例4-9:安德森鳶尾花卉數據集 |
例4-10:讀取蘋果股價csv檔為dataFrame |
範例4-11:讀取score.csv建立dataFrame,然後用express印出四位學生的三科成績 |
| 範例4-12:自行建立DataFrame資料集,然後用express印出四位學生的三科成績 |
範例4-21:3D表面圖:具有輪廓的曲面圖 |
範例4-22:使用滑動日期欄為Plotly地圖製作動畫 |
範例4-23:桑基圖 |
範例4-24:漏斗圖 |
| 範例4-25:動畫控制 |
|
|
|
|
| 1.Plotly,Plotly-Express簡介 |
1.Plotly,Plotly-Express簡介
(1)Plotly是一款使用JavaScript開發的製圖工具,提供了與主流資料分析語言互動的API(如:Python, R, MATLAB)。
(2)可以到官網 https://plot.ly/ 瞭解更多詳細的資訊。
Plotly能夠繪製具有使用者互動功能的精美圖表。
(3)Plotly Express簡介
plotly雖然功能強大, 卻一直沒有得到廣泛應用, 最主要的原因就是plotly的設置過於繁瑣。
因此, plotly 再度的推出簡化介面:Plotly Express, 簡稱 px。
px採用ROR等新一代 “約定優先" 程式設計模式, 內置了大量實用、現代的繪圖範本, 使用者只需調用簡單的api函數, 即可生成漂亮的互動畫面。
px 是 Plotly.py 的高度封裝, 它為複雜的圖表提供了一個簡單的語法. 且px與 Plotly 完全相容。
而px內置了的圖表組合, 已涵蓋了90%常用的繪圖需要。
|
2.Plotly,Plotly-Express功能: |
2.Plotly,Plotly-Express功能:
(1)使用 python-plotly 模組來進行圖形繪製,
(2)可以生成靜態 html 頁面結果。
(3)Plotly能夠繪製具有使用者互動功能的精美圖表。
(4)Plotly的功能
1).基本圖表:20種
2).統計和海運方式圖:12種
3).科學圖表:21種
4).財務圖表:2種
5).地圖:8種
6).3D圖表:19種
7).擬合工具:3種
8).流動圖表:4種
|
3.Python-Plotly 安裝 |
3.Python-Plotly 安裝
(1)在anaconda裡面並沒有安裝plotly,要再另外自行安裝
指令:pip install plotly==4.4.1
|
4.顯示結果的方法有兩種 |
4.顯示結果的方法有兩種
(1)方法1:使用Jupyter Notebook網頁編輯器來寫plotly的.py程式,就能顯示plotl圖形
注意:若是使用spider編輯器,預設是無法顯示的
(2)方法2:若是使用spider編輯器來寫plotly來顯示圖形,必須指定檔名.html就能打開網頁來顯示圖形。
|
範例4-1:Plotly-Express的結構與指令 |
5.範例4-1:Plotly-Express的結構與指令
(1)範例4-1:(使用速成express方法)簡單範例,畫出y=[1,3,2]的線性圖
import plotly.express as px
fig = px.line(x=["a","b","c"], y=[1,3,2], title="sample figure")
print(fig)
#fig.show()
fig.write_html('exp4-15.html', auto_open=True)
成果圖示: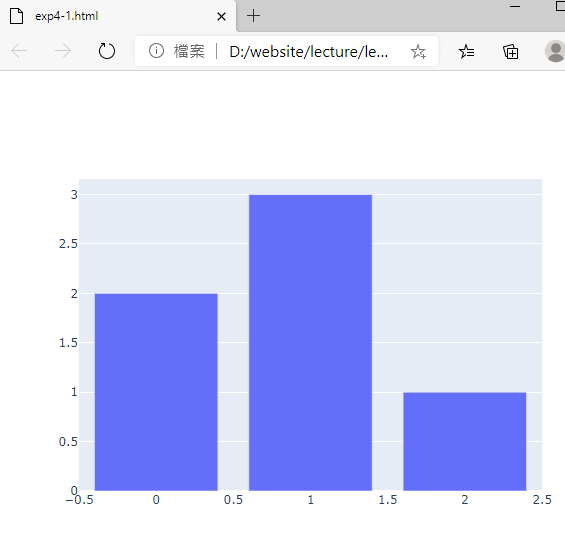
程式碼內容
(2)結構:
import plotly.express as px
#fig = px.line(x=數據, y=數據,title=標題)
fig = px.line(x=["a","b","c"], y=[1,3,2], title="sample figure")
#印出fig的結構
#print(fig)
#在jupiter網頁顯示
#fig.show()
#開啟一個exp4-1.html顯示圖形
fig.write_html('exp4-1.html', auto_open=True)
程式碼內容
|
範例4-2:(使用low-level plotly方法)使用Dictionary字典數據來畫圖 |
6.範例4-2:(使用low-level plotly方法)使用Dictionary字典數據來畫圖
#注意1:這個方法,必須在jupyter網頁來寫程式,無法在spiter編輯器\
#缺點:這個low-level 方法的數據較原始,不易使用
#設定fig = Dictionary字典數據
#結構:
"""
fig = dict({"data":[{"type":"bar","x":串列list,"y":串列list}]
import ploty.io as pio
pio.show(fig)
"""
#完整程式碼:
#格式:fig = dict({"data":[{"type":"bar","x":串列list,"y":串列list}]
fig = dict({
"data": [{"type": "bar",
"x": [1, 2, 3],
"y": [1, 3, 2]}],
"layout": {"title": {"text": "A Figure Specified By Python Dictionary"}}
})
#使用low-level plotly.io來顯示fig字典數據的圖形
import plotly.io as pio
pio.show(fig)
成果圖示: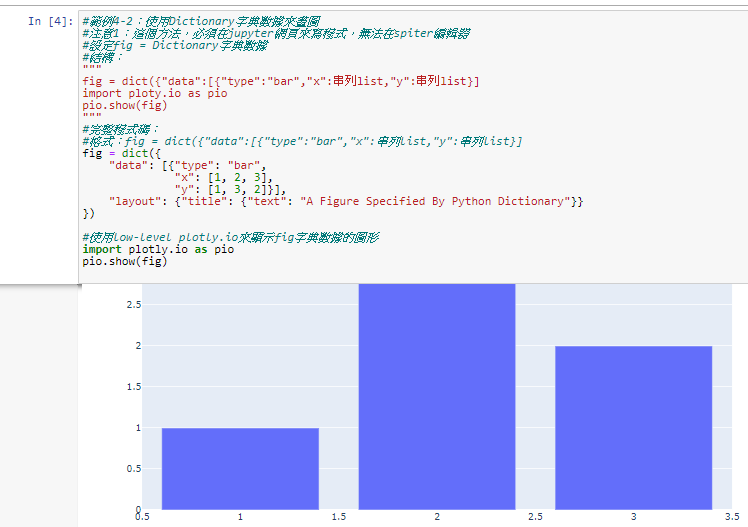
程式碼內容
|
範例4-3:(使用top-level plotly方法:plotly.graph_objects)畫出y=[1,3,2]的bar圖 |
7.範例4-3:(使用top-level plotly方法:plotly.graph_objects)畫出y=[1,3,2]的bar圖
#完整程式碼:
import plotly.graph_objects as go
#格式:
"""
fig = go.Figure
(
data=[go.Bar(x=串列list,y=串列list}],
layout=go.Layout(title=go.layout.Title(text=標題))
)
"""
fig = go.Figure(
data=[go.Bar(x=[1, 2, 3], y=[1, 3, 2])],
layout=go.Layout(
title=go.layout.Title(text="A Figure Specified By A Graph Object")
)
)
#在jupyter執行
#fig.show()
#在spider執行
fig.write_html('exp4-3.html', auto_open=True)
成果圖示: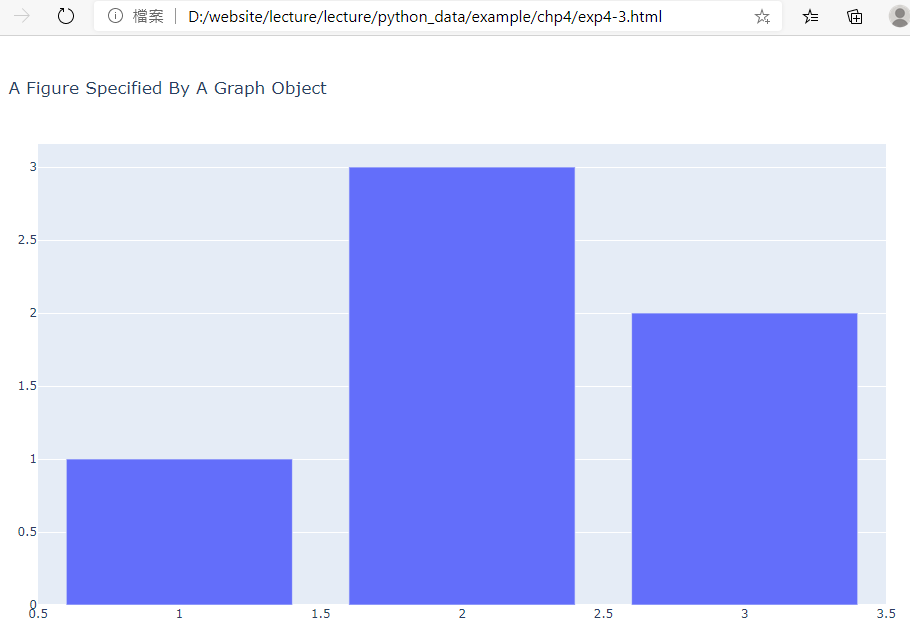
程式碼內容
|
範例4-4:顯示兩個分割圖形 |
8.範例4-4:顯示兩個分割圖形
import plotly.graph_objects as go
from plotly.subplots import make_subplots
#設定分割圖:一列,兩欄
fig = make_subplots(rows=1, cols=2)
#在第一列,第一欄顯示scatter
fig.add_trace(go.Scatter(y=[4, 2, 1], mode="lines"), row=1, col=1)
#在第一列,第二欄顯示bar圖
fig.add_trace(go.Bar(y=[2, 1, 3]), row=1, col=2)
#在jupyter執行
#fig.show()
#在spider執行
fig.write_html('exp4-4.html', auto_open=True)
成果圖示: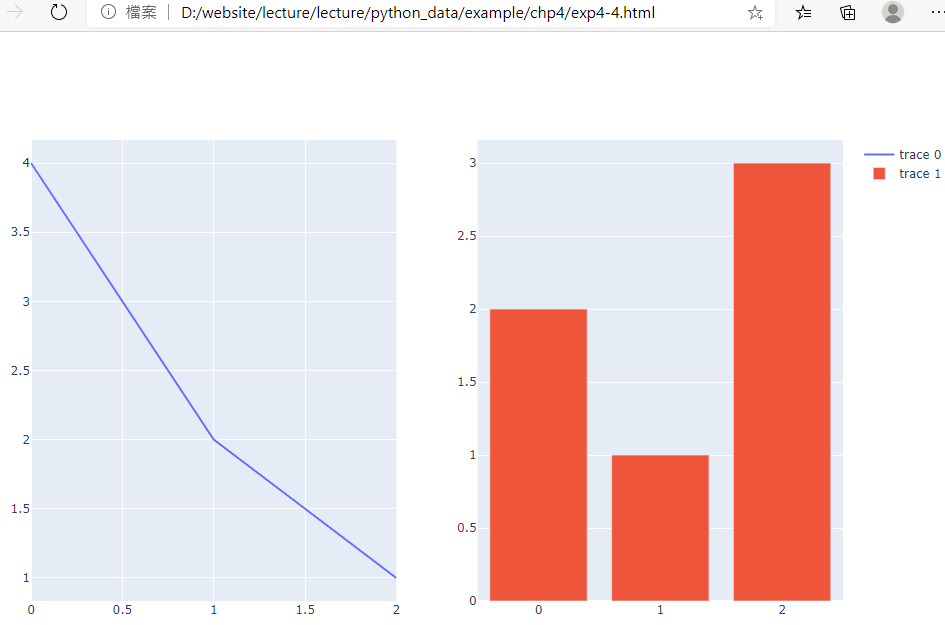
程式碼內容
|
範例4-5:顯示兩個分割圖形(方法2) |
9.範例4-5:顯示兩個分割圖形(方法2)
import plotly.graph_objects as go
from plotly.subplots import make_subplots
#設定分割圖:一列,兩欄
fig = make_subplots(rows=1, cols=2)
#在第一列,第一欄顯示scatter
#fig.add_trace(go.Scatter(y=[4, 2, 1], mode="lines"), row=1, col=1)
fig.add_scatter(y=[4, 2, 1], mode="lines", row=1, col=1)
#在第一列,第二欄顯示bar圖
#fig.add_trace(go.Bar(y=[2, 1, 3]), row=1, col=2)
fig.add_bar(y=[2, 1, 3], row=1, col=2)
#在jupyter執行
#fig.show()
#在spider執行
fig.write_html('exp4-5.html', auto_open=True)
成果圖示: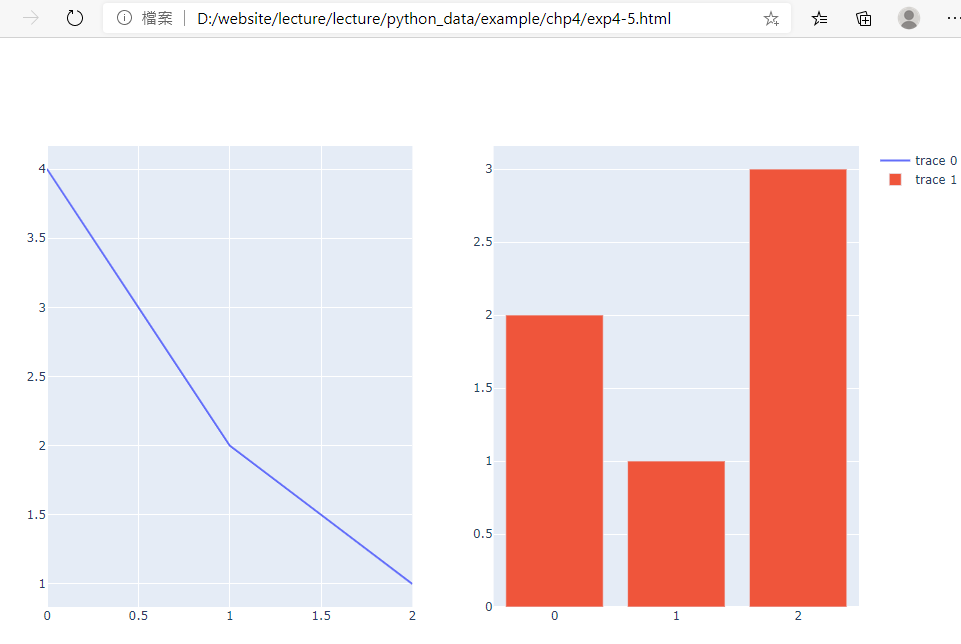
程式碼內容
|
範例4-6:在分割圖形新增圖形(scatte-marker,line) |
10.範例4-6:在分割圖形新增圖形(scatte-marker,line)
import plotly.graph_objects as go
from plotly.subplots import make_subplots
#設定分割圖:一列,兩欄
fig = make_subplots(rows=1, cols=2)
#在第一列,第一欄顯示bar圖
fig.add_bar(y=[4, 2, 1], row=1, col=1)
#新增scatte-marker
fig.add_scatter(y=[2, 3, 4], mode="markers",marker=dict(size=20, color="red"), row=1, col=1)
#在第一列,第二欄顯示bar圖
fig.add_bar(y=[2, 1, 3], row=1, col=2)
#新增line
fig.add_scatter(y=[3,2,4],row=1,col=2)
#在jupyter執行
#fig.show()
#在spider執行
fig.write_html('exp4-6.html', auto_open=True)
成果圖示: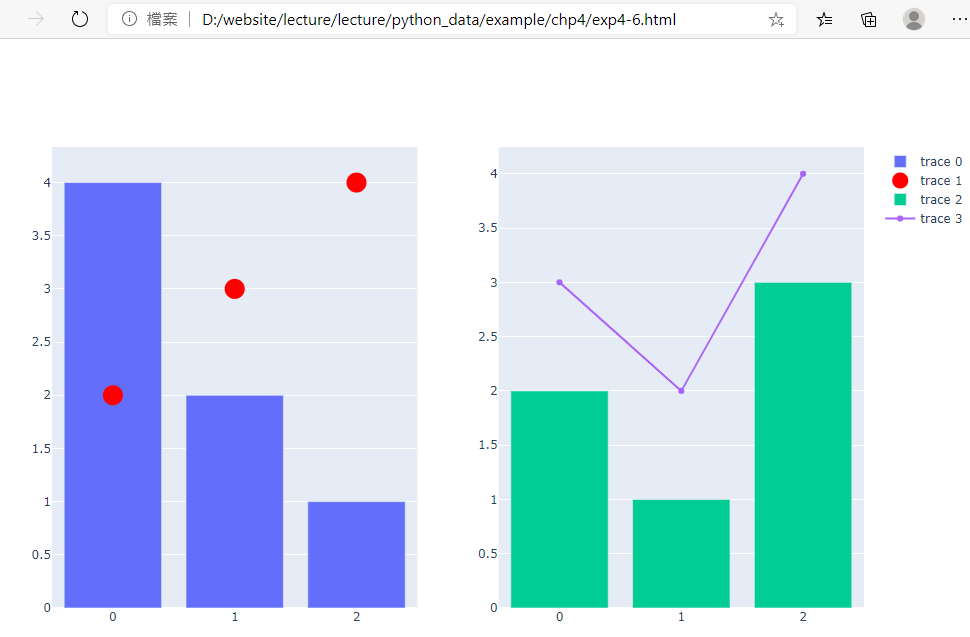
程式碼內容
|
範例4-7:express顯示四位學生的總成績 |
11.範例4-7:express顯示四位學生的總成績(畫lines+markers)
import plotly.express as px
#劃線
fig = px.line(x=['tom','john','peter','jolin'], y=[75,55,65,99],title='student score')
#新增marker
fig.update_traces(mode='markers+lines')
fig.write_html('exp4-7.html',auto_open=True)
成果圖示: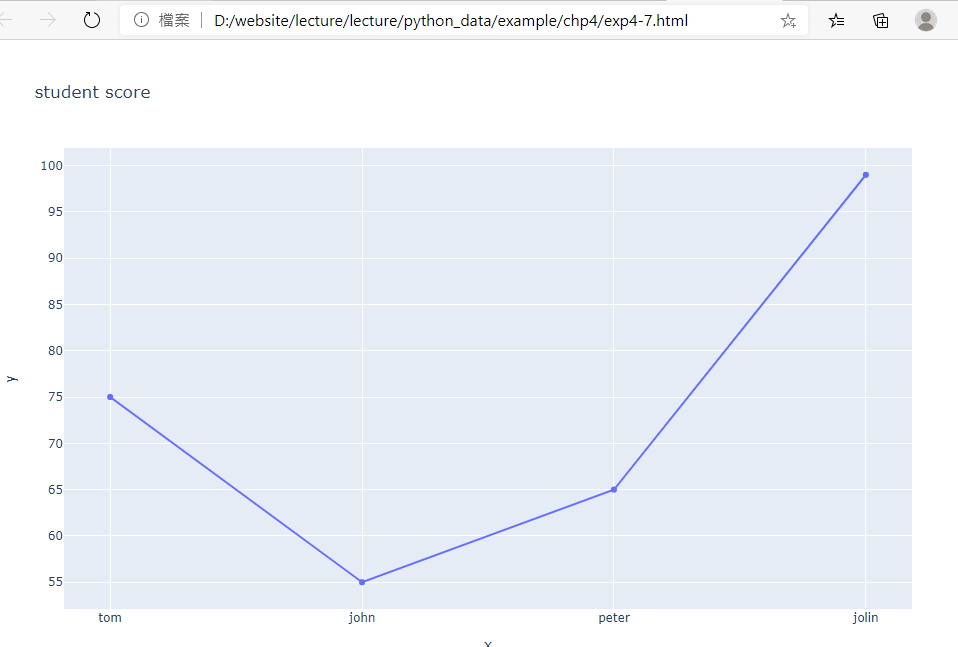
程式碼內容
|
範例4-8:express同時畫出三條圖 |
12.範例4-8:express同時畫出三條圖(四位學生,三科成績)
import plotly.express as px
#第一條線:國文
fig=px.line(x=['tom','john','peter','jolin'], y=[75,55,65,99],title='chinese')
#設定紅色線
fig.update_traces(line_color='red')
#第二條線:英文
fig2 = px.line(x=['tom','john','peter','jolin'], y=[85,90,55,65],title='enlish')
#設定紅色線
fig2.update_traces(line_color='green')
fig.add_trace(fig2.data[0])
#第三條線:數學
fig3 = px.line(x=['tom','john','peter','jolin'], y=[95,90,60,90],title='mah')
fig3.update_traces(line_color='blue')
fig.add_trace(fig3.data[0])
fig.write_html('exp4-8.html',auto_open=True)
成果圖示: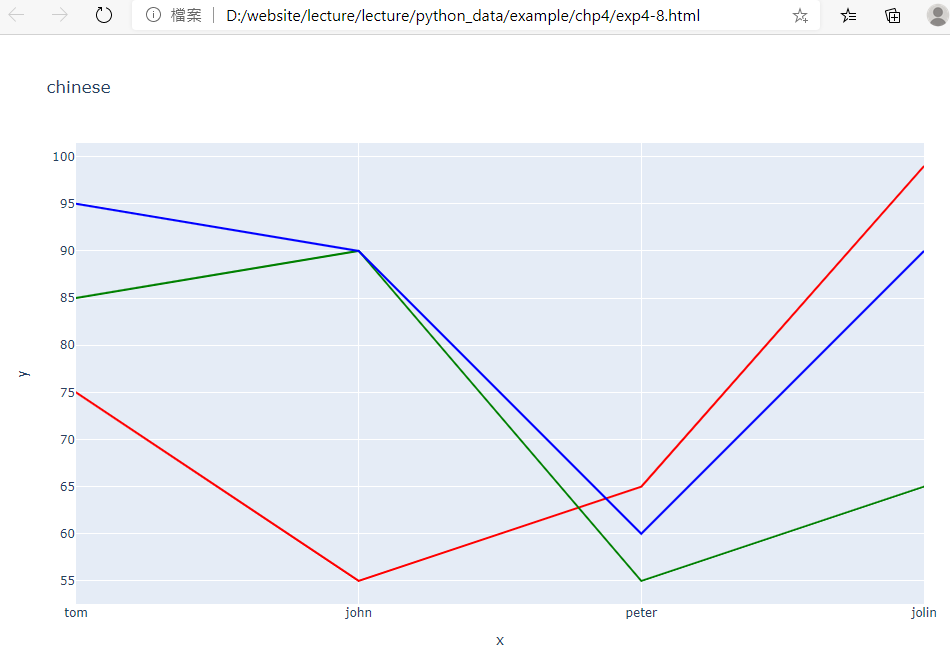
程式碼內容
|
範例4-9:安德森鳶尾花卉數據集 |
13.範例4-9:安德森鳶尾花卉數據集(Iris flower data set)
(1)生物統計:安德森鳶尾花卉數據集的散布圖
安德森鳶尾花卉數據集(英文:Anderson's Iris data set),也稱鳶尾花卉數據集(英文:Iris flower data set)或費雪鳶尾花卉數據集(英文:Fisher's Iris data set),是一類多重變量分析的數據集。
它最初是埃德加·安德森從加拿大加斯帕半島上的鳶尾屬花朵中提取的形態學變異數據,後由羅納德·費雪作為判別分析的一個例子[2],運用到統計學中。
其數據集包含了150個樣本,都屬於鳶尾屬下的三個亞屬,分別是山鳶尾、變色鳶尾和維吉尼亞鳶尾。
四個特徵被用作樣本的定量分析,它們分別是花萼和花瓣的長度和寬度。基於這四個特徵的集合,費雪發展了一個線性判別分析以確定其屬種。
成果圖示:
g
(2)直接使用express所提供的Iris flower data set
方法:dataframe = px.data.iris()
(3)範例4-9:安德森鳶尾花卉數據集(Iris flower data set)
import plotly.express as px
#dataframe = 讀取express所提供的Iris flower data set
df = px.data.iris()
#輸出這個dataframe的結構
print(df)
#x軸=sepal_width欄位,y軸=sepal_length欄位,線條顏色=species欄位
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species")
#在jupyter寫程式
#fig.show()
#在spider寫程式
fig.write_html('exp4-9.html',auto_open=True)
成果圖示: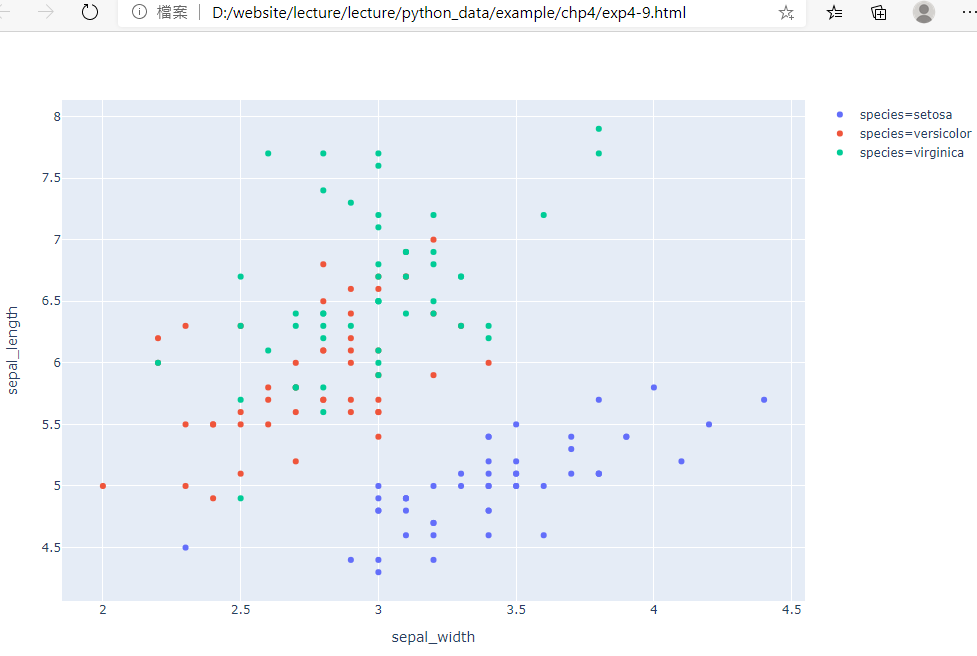
程式碼內容
|
例4-10:讀取蘋果股價csv檔為dataFrame,然後用express畫圖 |
14.例4-10:讀取蘋果股價csv檔為dataFrame,然後用express畫圖
#蘋果股價csv檔案:https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv
import pandas as pd
import plotly.express as px
#設定dataFrame設定資料結構(使用pandas讀入csv)
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
#用pandas畫圖,繪line線條圖
#df.plot(kind='line',title='score of students')
#用plotly.express畫圖(y="AAPL.Close")
fig = px.line(df, x="Date", y="AAPL.Close")
#增加另外一個欄位AAPL.Low
fig.add_scatter(x=df['Date'], y=df['AAPL.Low'])
#fig.show()
fig.write_html('exp4-10.html',auto_open=True)
成果圖示: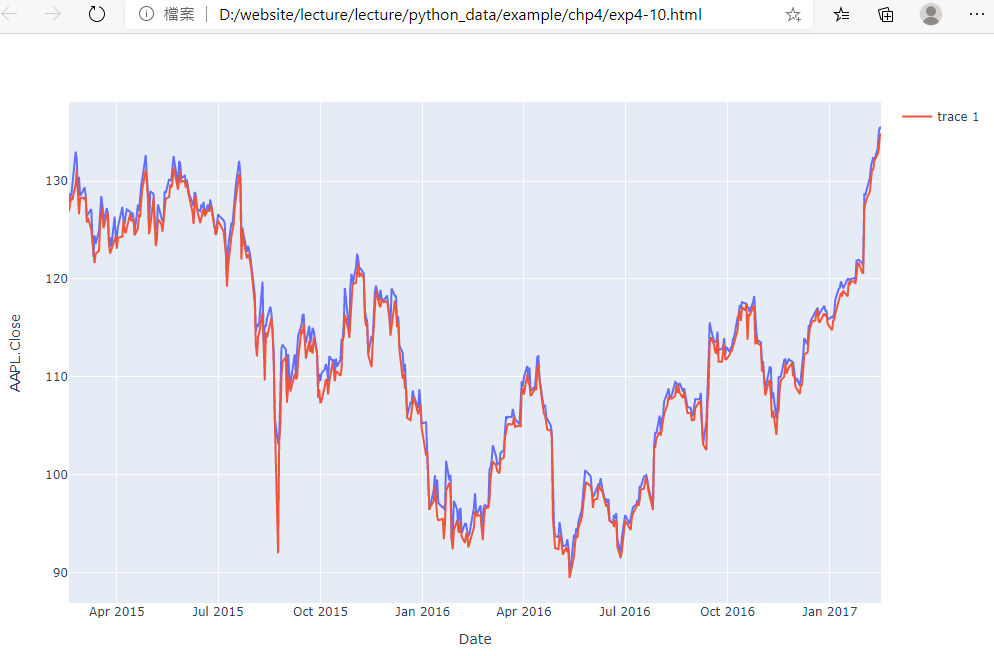
程式碼內容
|
範例4-11:讀取score.csv建立dataFrame,然後用express印出四位學生的三科成績 |
15-範例4-11:讀取score.csv建立dataFrame,然後用express印出四位學生的三科成績
# https://acupun.site/lecture/python_data/example/chp4/score2.csv
import pandas as pd
import plotly.express as px
# dataFrame = pandas 讀入csv檔案
df = pd.read_csv('https://acupun.site/lecture/python_data/example/chp4/score2.csv')
#設定空白 figure
fig = px.line(title='全班同學的國文英文數學分數')
#加上三條線(設定x=欄位,y=欄位,name=legend標例名稱,showlegend=True)
fig.add_bar(x=df['姓名'], y=df['國文'],name='國文', showlegend = True)
fig.add_scatter(x=df['姓名'], y=df['英文'],name='英文', showlegend = True)
fig.add_scatter(x=df['姓名'], y=df['數學'],name='數學', showlegend = True)
#fig.show()
fig.write_html('exp4-11.html',auto_open=True)
成果圖示: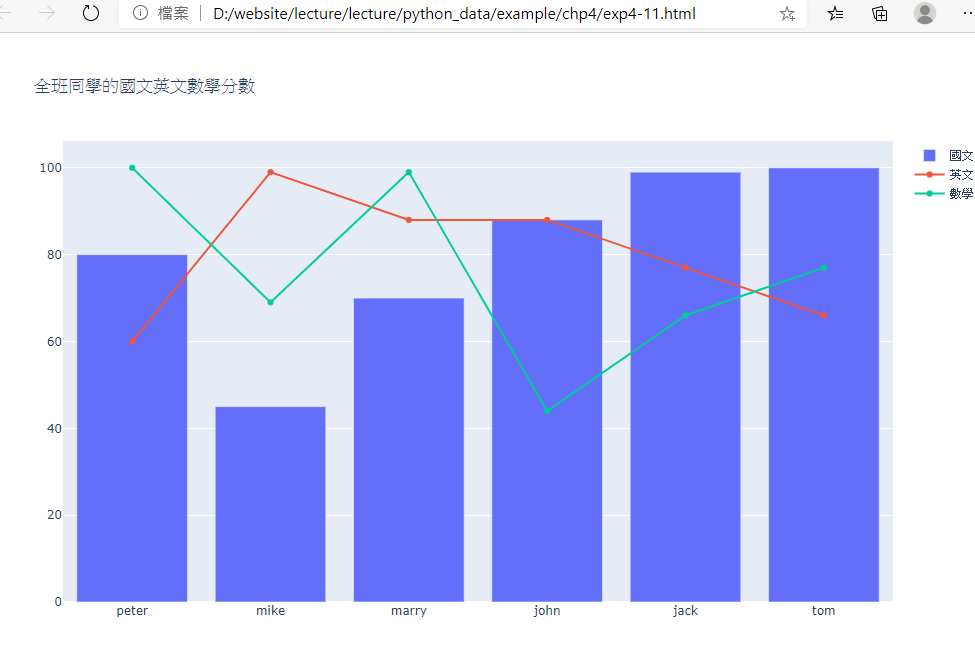
程式碼內容
|
範例4-12:自行建立DataFrame資料集,然後用express印出四位學生的三科成績 |
16.範例4-12:自行建立DataFrame資料集,然後用express印出四位學生的三科成績
import pandas as pd
import plotly.express as px
#數據資料表,採用三個串列List(coulumn=course,record_name=name, record_data = score)
df = pd.DataFrame({
'姓名':['john','mary','peter','jolin'],
'國文':[75,90,65,95],
'英文':[85,90,55,65],
'數學':[95,90,60,90]
})
#用plotly.express畫圖
fig = px.line(title='全班同學的國文英文數學分數')
fig.add_scatter(x=df["姓名"], y=df["國文"],name='國文',showlegend=True)
fig.add_scatter(x=df["姓名"], y=df["英文"],name='英文',showlegend=True)
fig.add_scatter(x=df["姓名"], y=df["數學"],name='數學',showlegend=True)
#fig.show()
fig.write_html('exp4-12.html',auto_open=True)
成果圖示: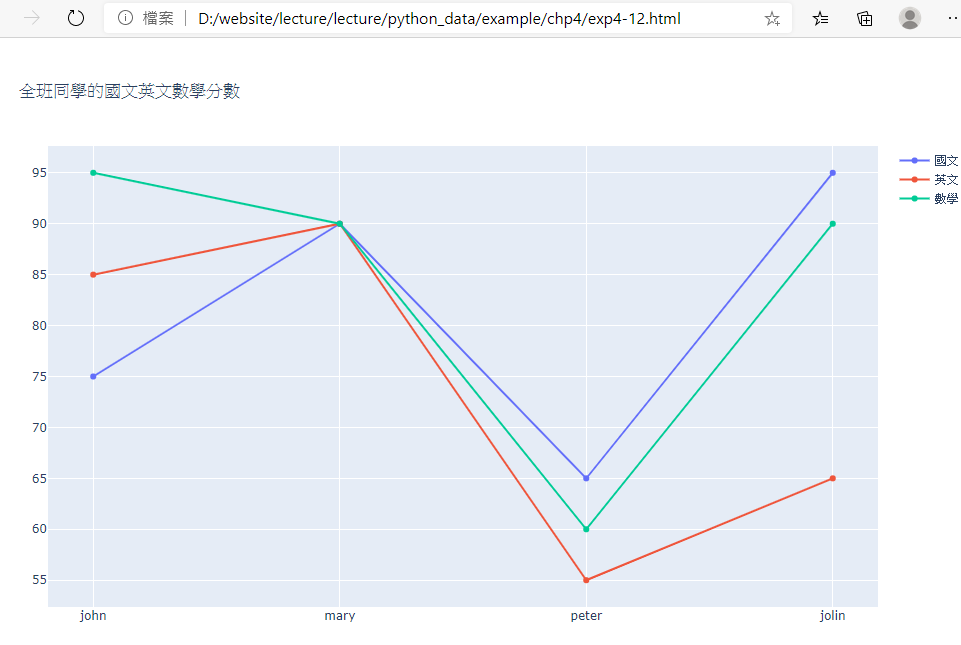
程式碼內容
|
範例4-21:3D表面圖:具有輪廓的曲面圖 |
21.範例4-21:3D表面圖:具有輪廓的曲面圖
#3D表面圖:具有輪廓的曲面圖,使用contours屬性顯示和自訂每個軸的輪廓資料
import plotly.graph_objects as go
import pandas as pd
# Read data from a csv
z_data = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/api_docs/mt_bruno_elevation.csv')
fig = go.Figure(data=[go.Surface(z=z_data.values)])
fig.update_traces(contours_z=dict(show=True, usecolormap=True,
highlightcolor="limegreen", project_z=True))
fig.update_layout(title='Mt Bruno Elevation', autosize=False,
scene_camera_eye=dict(x=1.87, y=0.88, z=-0.64),
width=500, height=500,
margin=dict(l=65, r=50, b=65, t=90)
)
#fig.show()
fig.write_html('exp4-21.html', auto_open=True)
成果圖示: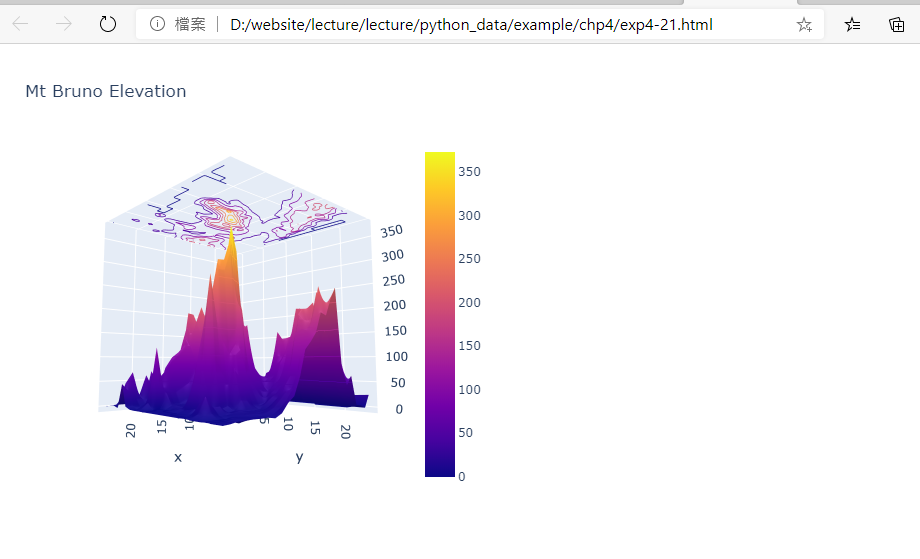
程式碼內容
|
範例4-22:使用滑動日期欄為Plotly地圖製作動畫 |
22.範例4-22:使用滑動日期欄為Plotly地圖製作動畫
#使用滑動日期欄為Plotly地圖製作動畫
import pandas as pd
import plotly.express as px
df = pd.DataFrame({'datetime': {0: '2018-09-29 00:00:00', 1: '2018-07-28 00:00:00', 2: '2018-07-29 00:00:00', 3: '2018-07-29 00:00:00', 4: '2018-08-01 00:00:00', 5: '2018-08-01 00:00:00', 6: '2018-08-01 00:00:00', 7: '2018-08-05 00:00:00', 8: '2018-09-06 00:00:00', 9: '2018-09-07 00:00:00', 10: '2018-09-07 00:00:00', 11: '2018-09-08 00:00:00', 12: '2018-09-08 00:00:00', 13: '2018-09-08 00:00:00', 14: '2018-10-08 00:00:00', 15: '2018-10-10 00:00:00', 16: '2018-10-10 00:00:00', 17: '2018-10-11 00:00:00', 18: '2018-10-11 00:00:00', 19: '2018-10-11 00:00:00'},
'lat': {0: 40.6908284, 1: 40.693601, 2: 40.6951317, 3: 40.6967261, 4: 40.697593, 5: 40.6987141, 6: 40.7186497, 7: 40.7187772, 8: 40.7196151, 9: 40.7196865, 10: 40.7187408, 11: 40.7189716, 12: 40.7214273, 13: 40.7226571, 14: 40.7236955, 15: 40.7247207, 16: 40.7221074, 17: 40.7445859, 18: 40.7476252, 19: 40.7476451},
'lon': {0: -73.9336094, 1: -73.9350917, 2: -73.9351778, 3: -73.9355315, 4: -73.9366737, 5: -73.9393797, 6: -74.0011939, 7: -74.0010918, 8: -73.9887851, 9: -74.0035125, 10: -74.0250842, 11: -74.0299202, 12: -74.029886, 13: -74.027542, 14: -74.0290157, 15: -74.0291541, 16: -74.0220728, 17: -73.9442636, 18: -73.9641326, 19: -73.9533039},
'count': {0: 1, 1: 2, 2: 5, 3: 1, 4: 6, 5: 1, 6: 3, 7: 2, 8: 1, 9: 7, 10: 3, 11: 3, 12: 1, 13: 2, 14: 1, 15: 1, 16: 2, 17: 1, 18: 1, 19: 1}})
fig = px.scatter_geo(df,
lat='lat',
lon='lon',
scope='usa',
color="count",
size='count',
projection="albers usa",
animation_frame="datetime",
title='Your title')
fig.update(layout_coloraxis_showscale=False)
#fig.show()
fig.write_html('exp4-22.html', auto_open=True)
成果圖示: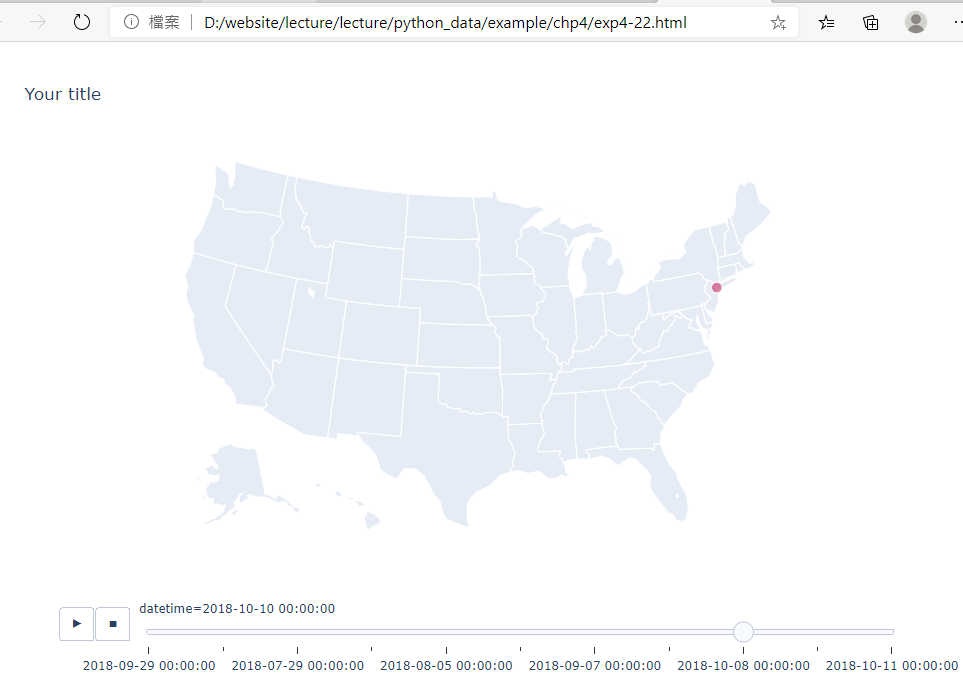
程式碼內容
|
範例4-23:桑基圖 |
23.範例4-23:桑基圖
#範例4-23:桑基圖:桑基圖通過定義視覺化到流動的貢獻源來表示源節點,目標為目標節點,數值以設置流volum,和標籤,顯示了節點名稱,在流量分析中常用
import plotly.graph_objects as go
import urllib, json
url = 'https://raw.githubusercontent.com/plotly/plotly.js/master/test/image/mocks/sankey_energy.json'
response = urllib.request.urlopen(url)
data = json.loads(response.read())
# override gray link colors with 'source' colors
opacity = 0.4
# change 'magenta' to its 'rgba' value to add opacity
data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']]
data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity))
for src in data['data'][0]['link']['source']]
fig = go.Figure(data=[go.Sankey(
valueformat = ".0f",
valuesuffix = "TWh",
# Define nodes
node = dict(
pad = 15,
thickness = 15,
line = dict(color = "black", width = 0.5),
label = data['data'][0]['node']['label'],
color = data['data'][0]['node']['color']
),
# Add links
link = dict(
source = data['data'][0]['link']['source'],
target = data['data'][0]['link']['target'],
value = data['data'][0]['link']['value'],
label = data['data'][0]['link']['label'],
color = data['data'][0]['link']['color']
))])
fig.update_layout(title_text="Energy forecast for 2050
Source: Department of Energy & Climate Change, Tom Counsell via Mike Bostock",
font_size=10)
fig.write_html('exp4-23.html', auto_open=True)
成果圖示: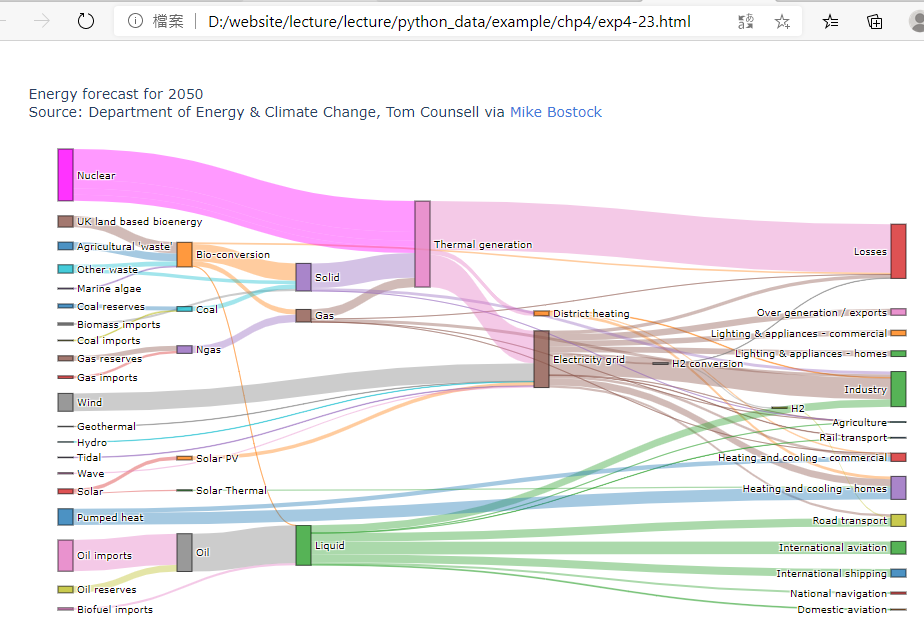
程式碼內容
|
範例4-24:漏斗圖 |
24.範例4-24:漏斗圖
#漏斗圖:漏斗圖通常用於表示業務流程不同階段的資料。在商業智慧中,這是識別流程潛在問題區域的重要機制。例如,它用於觀察銷售過程中每個階段的收入或損失,並顯示逐漸減小的值。每個階段均以占所有值的百分比表示。
from plotly import graph_objects as go
fig = go.Figure()
fig.add_trace(go.Funnel(
name = 'Montreal',
y = ["Website visit", "Downloads", "Potential customers", "Requested price"],
x = [120, 60, 30, 20],
textinfo = "value+percent initial"))
fig.add_trace(go.Funnel(
name = 'Toronto',
orientation = "h",
y = ["Website visit", "Downloads", "Potential customers", "Requested price", "invoice sent"],
x = [100, 60, 40, 30, 20],
textposition = "inside",
textinfo = "value+percent previous"))
fig.add_trace(go.Funnel(
name = 'Vancouver',
orientation = "h",
y = ["Website visit", "Downloads", "Potential customers", "Requested price", "invoice sent", "Finalized"],
x = [90, 70, 50, 30, 10, 5],
textposition = "outside",
textinfo = "value+percent total"))
fig.write_html('exp4-24.html', auto_open=True)
成果圖示: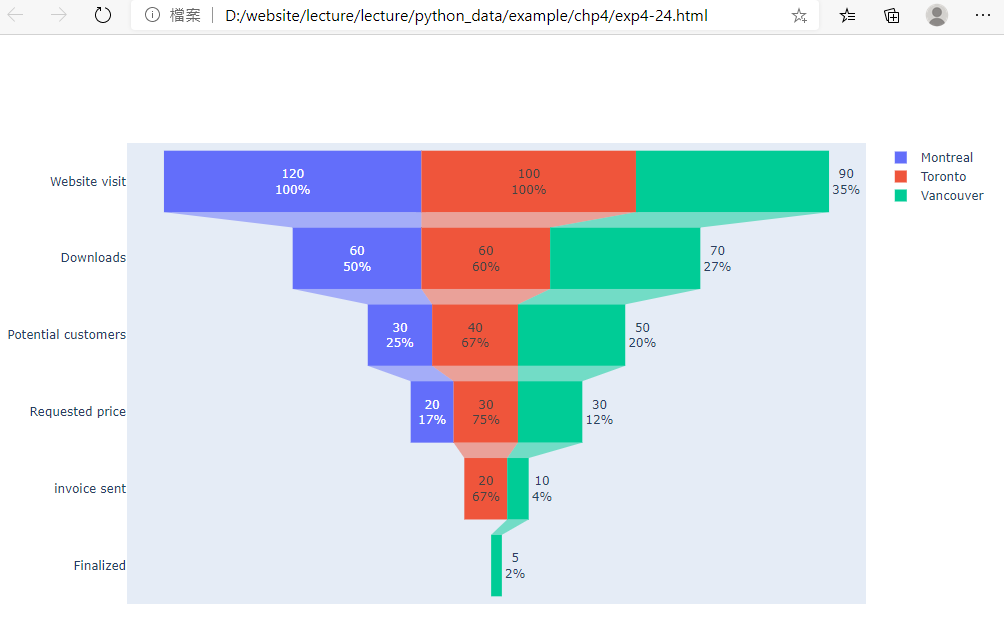
程式碼內容
|
範例4-25:動畫控制 |
25.範例4-25:動畫控制
#添加動畫控制(animation)
import plotly.express as px
gapminder = px.data.gapminder()
fig = px.scatter(gapminder, x="gdpPercap", y="lifeExp", animation_frame="year", animation_group="country",
size="pop", color="continent", hover_name="country", facet_col="continent",
log_x=True, size_max=45, range_x=[100,100000], range_y=[25,90])
fig.write_html('exp4-25.html', auto_open=True)
成果圖示: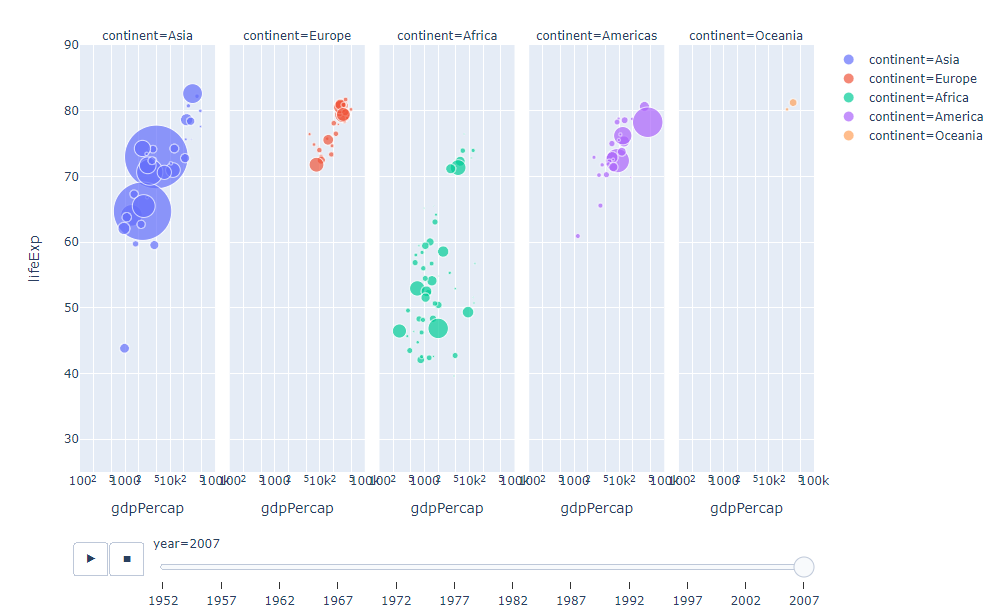
程式碼內容
|
| |
| |
| chp5.矩陣運算數學函數庫(Numpy) |
| 目錄 |
Python大數據分析最重要的四個模組 |
1.Numpy簡介與安裝 |
範例5-1:一維矩陣 |
範例5-2:二維矩陣 |
| 範例5-3:設定矩陣元素起始值 |
範例5-4:建立矩陣元素值:range,arange,linspace |
範例5-5:建立二維三維矩陣元素值:arange.reshape |
範例5-6:矩陣的切割,切片(slice) |
範例5-7:二維矩陣的部分區域的對應 |
| 範例5-8:使用另外一組矩陣數據來建立新的矩陣 |
範例5-9:查詢與設定矩陣的資料型態:dtype |
11.矩陣基礎 |
範例5-10:矩陣的加減乘除,dot運算 |
範例5-11:兩個平面向量的內積,外積 |
| 14.統計的『平均值,變異數,標準差 |
範例5-12:矩陣的數據函數與統計函數 |
範例5-13:在矩陣中挑選你要的元素矩陣 |
範例5-14:不同大小矩陣的相加 |
範例5-15:python裡面的張量tensor,向量vector,純量scalar |
| 張量tensor的幾何意義與坐標轉換 |
|
|
|
|
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組
Python資料分析最重要的四個模組:pandas、numpy、scipy、matplotlib。
(1)pandas:是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
pandas模組應該是python用來進行一般日常的大數據分析,最重要的模組了。
因為pandas的DataFrame資料結構,可以快速的互通於所有的二維結構資料,包括『excel,csv,json,xml,mysql,任何的資料庫,網頁的表格資料,字典dict,二維串列list』
也就是pandas的DataFrame資料結構,可以與它們之間互相簡易的存取。
然後再根據DataFrame來進行想要的大數據分析,它提供內建的演算法與資料結構,能夠用一個指令,就可以進行二維資料的『排序,篩選,關鍵字查詢,任意區間範圍查詢,統計學計算,平均值,變異數,標準差,字串檢索,字串取代,欄位樞紐分析、小記、欄位加總,把二維資料任意方式圖形視覺化顯示』
而建立pandas的DataFrame資料結構,有兩種方式,可以用column的方式來輸入資料,也可以用row的方式來輸入資料。
所以pandas是大數據分析,非常實用的利器工具,是python資料分析的首選。
(2)Numpy:
Numpy專門用來處理矩陣,它的運算效率比列表list串列更高效。
Numpy是Python進行專業的數值計算之重要模組,因為大多數提供科學計算的包都是用numPy的陣列作為構建基礎,因此在進行高等數學計算時,numpy就是大數據分析的最重要工具了,因為高等數學運算,都是以矩陣的方式來進行運算,例如人工智慧,機器學習,深度學習,類神經網路計算等。
(3)sscipy:是基於numpy的科學計算包,包括統計、線性代數等工具。
(4)matplotlib:是最流行的用於繪製資料圖表的 Python 庫
也可以結合pandas模組來繪圖。
|
1.Numpy簡介與安裝 |
1.Numpy簡介與安裝
(1)Numpy簡介
A).Python資料分析最重要的四個模組:numpy、scipy、pandas、matplotlib。
B).Numpy是Python數值計算最重要的模組,大多數提供科學計算的包都是用numPy的矩陣作為構建基礎。
C).Numpy專門用來處理矩陣,它的運算效率比列表list串列更高效。
scipy:是基於numpy的科學計算包,包括統計、線性代數等工具。
pandas:是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
matplotlib:是最流行的用於繪製資料圖表的 Python 庫
(2)Numpy安裝
如果已經安裝了anaconda,基本上就已經安裝Numpy了
|
範例5-1:一維矩陣 |
2.一維矩陣:範例5-1
import numpy as np
list1 = ['tom','john','peter','jolin']
name = np.array(list1)
#印出第2個人名
print('第2個人名=', name[1])
#印出全部人名
for item in name:
print(item)
#印出矩陣的維度,長度
print('矩陣的維度,長度=', name.shape,'個人')
print('矩陣的維度,長度=', len(name))
成果圖示:
程式碼內容
|
範例5-2:二維矩陣 |
3.範例5-2:二維矩陣
import numpy as np
list1 = [['tom','0912456789','tom@gamil.com'],['john','06-5718888','john@gamil.com']]
myarr = np.array(list1)
#印出john的電話
#二維矩陣的兩種表示方法:a[1,1] = a[1][1]
print(myarr[1][0],'電話=',myarr[1][1])
print(myarr[1,0],'電話=',myarr[1,1])
#印出二維矩陣的維度(長度)
print('二維矩陣的維度(長度)=', myarr.shape)
成果圖示: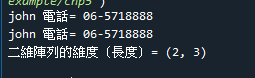
程式碼內容
|
範例5-3:設定矩陣元素起始值 |
4.範例5-3:設定矩陣元素起始值
import numpy as np
#設定一維矩陣元素都是0
a = np.zeros((3))
print('設定一維矩陣元素都是0=', a)
#設定二維矩陣元素都是0
b = np.zeros((3,3))
print('設定二維矩陣元素都是0=', b)
#設定二維矩陣元素都是1
c = np.ones((3,3))
print('設定二維矩陣元素都是1=', c)
#設定二維矩陣元素都是5
d = np.full((3,3),5)
print('設定二維矩陣元素都是5=', d)
#設定 5 x 5 矩陣的左手~右下元素都是1,其它為0
e = np.eye((5))
print('設定5 x 5 矩陣的左手~右下元素都是1,其它為0 =', e)
#設定3x3矩陣的元素都是亂數值
f = np.random.random((3,3))
print('設定3x3矩陣的元素都是亂數值 =', f)
成果圖示:
程式碼內容
|
範例5-4:建立矩陣元素值(自動遞增遞減的數組):range,arange,linspace |
5.範例5-4:建立矩陣元素值(自動遞增遞減的數組):range,arange,linspace
(1)說明:numpy.arange
公式:numpy.arange(start, stop, step, dtype)
參數說明:
start 起始值,默認為0
stop 終止值(不包含)
step 步長,默認為1
dtype 返回ndarray的資料類型,如果沒有提供,則會使用輸入資料的類型。
(2)說明:numpy.linspace
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
功能:指定在start到stop均分數值
參數說明:
start:不可省
stop:有時包含有時不包含,根據endpoint來選擇,默認包含
num:指定均分的數量,默認為50
endpoint:布爾值,可選,默認為True。包含stop就True,不包含就False
retstep : 布爾值,可選,默認為False。如果為True,返回值和步長
dtype : 輸出數據類型,可選。如果不指定,則根據前面參數的數據類型
例如:
np.linspace(1,10) #默認生成50個,包含stop:10
範例5-4:建立矩陣元素值(自動遞增遞減的數組):range,arange,linspace
#完整程式碼:
#range(1,5)
for i in range(1,5):
print('range(1,5)=', i)
#arange(1,5) = 1,2,3,4的矩陣
import numpy as np
a = np.arange(1,5)
print('arange(1,5)=', a)
#arange(5) = 0, 1,2,3,4的矩陣
a = np.arange(5)
print('arange(5)=', a)
#arange(1,5,0.5)
a = np.arange(1,5,0.5)
print('arange(1,5,0.5)=', a)
#linspace(1,3) = 在1~3之間,分割50等分
a = np.linspace(1,3)
print('linspace(1,3)=', a)
#linspace(1,3,4) = 在1~3之間,分割4等分
a = np.linspace(1,3,4)
print('linspace(1,3,4)=', a)
成果圖示: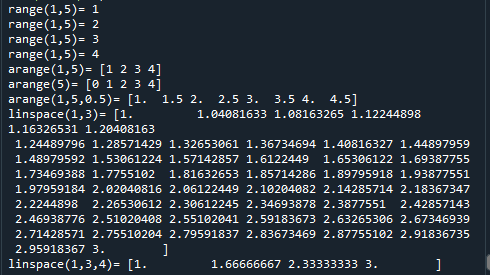
程式碼內容
|
範例5-5:建立二維三維矩陣元素值(自動遞增遞減的數組):arange.reshape |
6.範例5-5:建立二維三維矩陣元素值(自動遞增遞減的數組):arange.reshape
指令:np.arange(8).reshape((2, 4)))
說明:
arange()用於生成一維矩陣
reshape()將一維矩陣轉換為多維矩陣
範例5-5:完整程式碼:
#範例5-5:建立二維三維矩陣元素值(自動遞增遞減的數組):arange.reshape
import numpy as np
a = np.arange(0,12)
print('arange(0,12)=', a)
#將a(0,12)分割成二維矩陣reshape(2,6)
a = np.arange(0,12).reshape(2,6)
print('reshape(2,6)=\n', a)
#將a(0,12)分割成二維矩陣reshape(3,4)
a = np.arange(0,12).reshape(3,4)
print('reshape(3,4)=\n', a)
#將a(0,12)分割成三維矩陣reshape(2,2,3)
a = np.arange(0,12).reshape(2,2,3)
print('reshape(2,2,3)=\n', a)
成果圖示: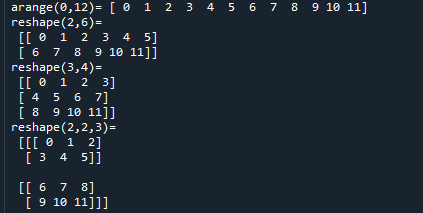
程式碼內容
|
範例5-6:矩陣的切割,切片(slice) |
7.範例5-6:矩陣的切割,切片(slice)
(1)Numpy 中多维数组的切片操作与 Python 中 list 的切片操作一样,同样由 start, stop, step 三个部分组成
(2)功能:矩陣的切割,在應用於『統計,科學計算』等,非常常用。
(3)完整程式碼:
#範例5-6:矩陣的切割,切片(slice)
import numpy as np
#一維矩陣的切片,切割
a = np.arange(0,11)
print(a)
#切割(2:5:1) = 從index=2開始,到index=5-1=4, step=1
s1 = a[2:5:1]
print('切割(2:5:1)=',s1)
#切割(2:4) = 從index=2開始,到index=4-1=3
s1 = a[2:4]
print('切割(2:4)=',s1)
#切割(:4) = 從index=0開始,到index=4-1=3
s1 = a[:4]
print('切割(:4)=',s1)
#切割(2:9:2) = 從index=2開始,到index=9-1=8, step=2
s1 = a[2:9:2]
print('切割(2:9:2)=',s1)
#二維矩陣的切片,切割
a2 = np.arange(0,12).reshape(3,4)
print('reshape(3,4)=', a2)
#把a2切片 = a2[1:3,1:3]
s2 = a2[1:3,1:3]
print('a2[1:3,1:3]=',s2)
#把a2切片 = a2[:,::2] = [第一維全部顯示,第二維step2]
s2 = a2[:,::2]
print('a2[:,::2]=',s2)
成果圖示: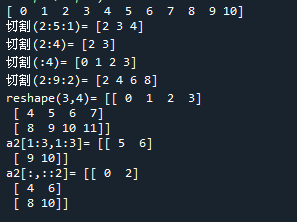
程式碼內容
|
範例5-7:二維矩陣的部分區域的對應 |
8.範例5-7:二維矩陣的部分區域的對應
import numpy as np
#建立一個二維矩陣
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
print('二維矩陣a=\n', a)
#矩陣b = 矩陣a的部分區域(x=0:2=0,1)(y=1:3=1,2)
b = a[0:2, 1:3]
print('矩陣a的部分區域a[0:2, 1:3] \n=',b)
#修改b的值
b[0,0] = 99
print('修改b的值 =\n', b)
#修改b,會連動都應到修改到a
print('修改b,會連動都應到修改到 a =\n', a)
#如果修改c,不想連動到a,方法 = .copy()
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
c = a[0:2, 1:3].copy()
c[0,0] = 333
print('修改c 的值 =\n', c)
print('修改c,會連動都應到修改到 a (沒有被連動)=\n', a)
成果圖示:
程式碼內容
|
範例5-8:使用另外一組矩陣數據來建立新的矩陣 |
9.範例5-8:使用另外一組矩陣數據來建立新的矩陣
import numpy as np
#建立一個二維矩陣
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
print('二維矩陣a=\n', a)
#新矩陣b = [a[1,1],a[0,2]]
b = [a[1,1],a[0,2]]
print('b = [a[1,1],a[0,2]]=', b)
#新矩陣c = a[[0,1,2],[0,1,0]] = [a[0,0],a[1,1],a[2,0]]
c = a[[0,1,2],[0,1,0]]
print('a[0,0],a[1,1],a[2,0]=', a[0,0],a[1,1],a[2,0])
print('c = a[[0,1,2],[0,1,0]] = [a[0,0],a[1,1],a[2,0]] = ', c)
成果圖示: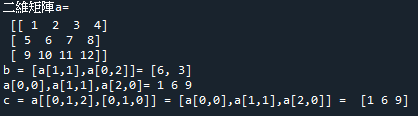
程式碼內容
|
範例5-9:查詢與設定矩陣的資料型態:dtype |
10.範例5-9:查詢與設定矩陣的資料型態:dtype
import numpy as np
a = np.arange(0,11)
print('a=',a)
#顯示矩陣a的資料型態
print('a.dtype資料型態=', a.dtype)
#顯示矩陣b的資料型態
b = np.linspace(1,3)
print('b =', b)
print('b.dtype資料型態=', b.dtype)
#設定矩陣 c 的資料型態為 int64
c = np.array([[3,2],[3,5]], dtype = np.int64)
#顯示矩陣c 的資料型態
print('c.dtype資料型態=', c.dtype)
成果圖示: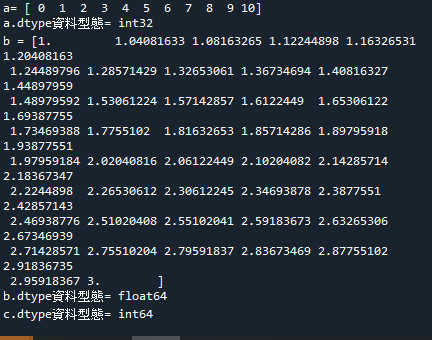
程式碼內容
|
11.矩陣基礎 |
11.矩陣基礎
矩陣基礎:矩陣基本運算pdf
|
範例5-10:矩陣的加減乘除,dot運算 |
12.範例5-10:矩陣的加減乘除,dot運算
import numpy as np
a = np.array([[1,2],[3,4]])
b = np.array([[5,6],[7,8]])
print('矩陣 a =\n', a)
print('矩陣 b =\n', b)
#加法
print('\n#三種矩陣的相加:')
print('(1).a + b = \n', a + b)
print('(2).np.add(a + b) = \n', np.add(a,b))
print('(3).a + [1,1] = \n', a+[1,1])
#減法
print('\n#三種矩陣的相減:')
print('(1).a - b = \n', a - b)
print('(2).np.subttact(a + b) = \n', np.subtract(a,b))
print('(3).a - [1,1] = \n', a-[1,1])
#乘法
print('\n#三種矩陣的乘法:')
print('(1).a * b = \n', a * b)
print('(2).np.multiply(a, b) = \n', np.multiply(a,b))
print('(3).a * [2,2] = \n', a*[2,2])
#除法
print('\n#三種矩陣的相除:')
print('(1).a / b = \n', a / b)
print('(2).np.divide(a, b) = \n', np.divide(a,b))
print('(3).a / [2,2] = \n', a/[2,2])
#平方
print('\n#二種矩陣的平方:')
print('(1).a**2 = \n', a**2)
print('(2).np.square(a) = \n', np.square(a))
#平方根
print('\n#一種矩陣的平方根:')
print('(2).np.sqrt(a) = \n', np.sqrt(a))
#點積 = dot
print('\n#二種矩陣的點積相乘:')
print('(1).a.dot(b) = \n', a.dot(b))
print('(2).np.dot(a, b) = \n', np.dot(a,b))
測試結果:
矩陣 a =
[[1 2]
[3 4]]
矩陣 b =
[[5 6]
[7 8]]
#三種矩陣的相加:
(1).a + b =
[[ 6 8]
[10 12]]
(2).np.add(a + b) =
[[ 6 8]
[10 12]]
(3).a + [1,1] =
[[2 3]
[4 5]]
#三種矩陣的相減:
(1).a - b =
[[-4 -4]
[-4 -4]]
(2).np.subttact(a + b) =
[[-4 -4]
[-4 -4]]
(3).a - [1,1] =
[[0 1]
[2 3]]
#三種矩陣的乘法:
(1).a * b =
[[ 5 12]
[21 32]]
(2).np.multiply(a, b) =
[[ 5 12]
[21 32]]
(3).a * [2,2] =
[[2 4]
[6 8]]
#三種矩陣的相除:
(1).a / b =
[[0.2 0.33333333]
[0.42857143 0.5 ]]
(2).np.divide(a, b) =
[[0.2 0.33333333]
[0.42857143 0.5 ]]
(3).a / [2,2] =
[[0.5 1. ]
[1.5 2. ]]
#二種矩陣的平方:
(1).a**2 =
[[ 1 4]
[ 9 16]]
(2).np.square(a) =
[[ 1 4]
[ 9 16]]
#一種矩陣的平方根:
(2).np.sqrt(a) =
[[1. 1.41421356]
[1.73205081 2. ]]
#二種矩陣的點積相乘:
(1).a.dot(b) =
[[19 22]
[43 50]]
(2).np.dot(a, b) =
[[19 22]
[43 50]]
成果圖示:
程式碼內容
|
範例5-11:兩個平面向量的內積,外積 |
13.範例5-11:兩個平面向量的內積,外積
(1)定義:兩個平面向量的內積,外積
內積=a.b = a在b方向的投影長度 × b長度 = 長度值
外積=axb = 與a,b都垂直的法向量 = 一維向量

(2)範例5-11:兩個平面向量的內積,外積
import numpy as np
a = np.array([1,2,2])
print('a= row vector=',a)
b = np.array([2,-1,3])
#b = np.array([[2,-1,3]]).
T
print('b=column vector=\n', b)
#(1).內積=a.b = a在b方向的投影長度 × b長度 = 長度值
#numpy 的內積函數 = a.b = np.dot(a,b) = a.dot(b)
c = np.dot(a,b)
print('內積=axb=a.dot(b)=np.dot(a,b)=',c)
#外積=axb = 與a,b都垂直的法向量 = 一維向量 = (8,1,-5)
#這個外積的長度 = axb圍起來的平行四邊形面積
#numpy 的外積函數 = np.cross(a,b) = a.cross(b)
d = np.cross(a,b)
print('外積=axb=a.cross(b)=np.cross(a,b)=',d)
成果圖示: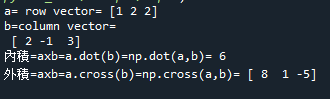
程式碼內容
|
14.統計的『平均值,變異數,標準差』 |
14.統計的『平均值,變異數,標準差』
(1)變異數
設有n 個資料,
則此資料的變異數σ^2:是所有資料的離差平方之平均,
其中,μ是母體平均數


(2)標準差
此資料的標準差σ= SD = 是變異數的開方

|
範例5-12:矩陣的數據函數與統計函數 |
15.範例5-12:矩陣的數據函數與統計函數
import numpy as np
a = np.array([[1,2,6],[9,-1,3]])
#a = np.array([[-1,2,3],[13,14,15]])
print('a= row vector=\n',a, a.shape)
#顯示矩陣 a的轉置矩陣 Transpose = a.T
print('a的轉置矩陣 = a.T=\n', a.T)
#找出矩陣裡面的最大值
print('出矩陣裡面的最大值=', np.max(a))
print('出矩陣裡面的最小值=', np.min(a))
#顯示矩陣裡面所有元素的總和
print('顯示矩陣裡面所有元素的總和=', np.sum(a))
#把二維矩陣疊加後,轉成一維矩陣
print('把二維矩陣疊加後,轉成一維矩陣=', np.sum(a, axis=0))
#把二維矩陣,先轉成轉置矩陣T,再疊加後,轉成一維矩陣
print('把二維矩陣疊加後,轉成一維矩陣=', np.sum(a, axis=1))
#計算矩陣裡面所有元素的平均值(mean)
print('計算矩陣裡面所有元素的平均值(mean)=', np.mean(a))
#計算矩陣裡面所有元素的中位數,中間值(median)
print('計算矩陣裡面所有元素的中位數,中間值(median)=', np.median(a))
#計算矩陣裡面所有元素的方差σ^2= 是變異數 = np.var(a)
# 變異數 = σ^2 = = mean(abs(x-mean(x)))**2
#print('方差 = 變異數 = σ^2 = = meant(a-mean(a))=',np.mean(abs(a-np.mean(a)))**2)
print('方差 = 變異數 var = σ^2 = = mean(a-mean(a))=',np.var(a))
#計算矩陣裡面所有元素的標準差σ= std = 是變異數的開方 = std(a)
# 標準差σ= SD = sqrt(mean(abs(x-mean(x)))**2)
print('標準差σ= std = 是變異數的開方 = std(a)=',np.std(a))
成果圖示: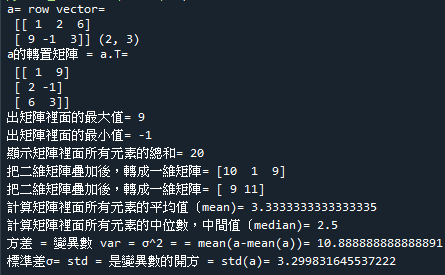
程式碼內容
|
範例5-13:在矩陣中挑選你要的元素矩陣 |
16.範例5-13:在矩陣中挑選你要的元素矩陣
import numpy as np
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
print('a =\n', a)
#印出全部大於5的數值
print('印出全部大於5的數值 =',a[a>5])
#印出全部的偶數
print('印出全部大於5的數值 =',a[a%2==0])
成果圖示:
程式碼內容
|
範例5-14:不同大小矩陣的相加 |
16.範例5-14:不同大小矩陣的相加
import numpy as np
a = np.array([[1,2,3,],[5,6,7]])
b = np.array([1,1,1])
print('a=\n', a)
print('b=\n', b)
#方法1:直接相加
print('方法1:直接相加=\n', a+b)
#方法2:把b複製擴展,成a一樣的大小 = np.tile(b,(2,1)) = 複製成2列1欄
c = np.tile(b,(2,1))
print('方法2:把b複製擴展,成a一樣的大小=\n', c)
print('再a+c=\n', a+c)
成果圖示:
程式碼內容
|
範例5-15:python裡面的張量tensor,向量vector,純量scalar |
17.範例5-15:python裡面的張量tensor,向量vector,純量scalar
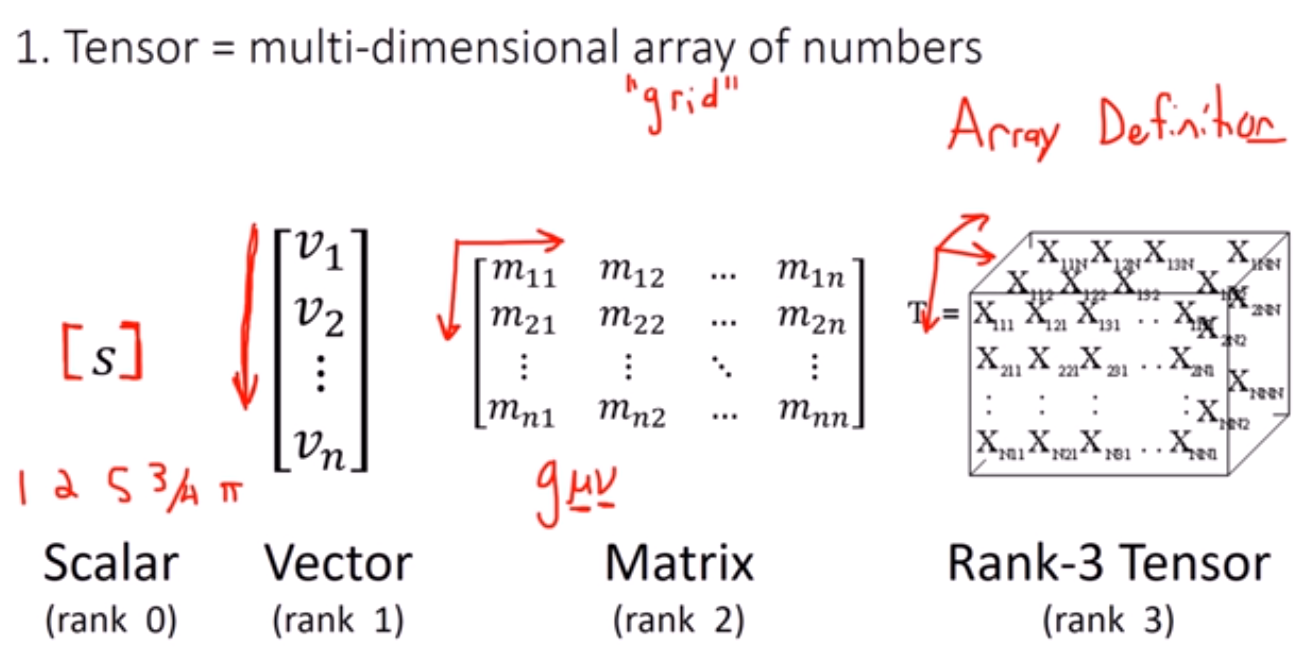
(1).定義:python裡面的張量tensor,向量vector,純量scalar,是根據多維陣列的數組型態來定義的。
這些定義只是方便python的計算方便,但並不是張量的原始物理意義。
張量的原始物理意義:乃是在線性代數(linear algebra)描述不同坐標系統的某個幾何物體的方式,
(2)從陣列的數組角度來定義
(3)#範例5-15:python裡面的張量tensor,向量vector,純量scalar
import numpy as np
#1- 純量scalar (rank=0)
a1 = 5
print('純量scalar=', a1)
#2-python 向量vector(rank=1)
a2 = [1,5,7]
print('python向量vector(不適合做矩陣運算)=', a2)
#3-numpy向量vector(rank=1)
a3 = np.array([5,6,7])
print('numpy向量vector(適合做矩陣運算)=', a3)
#4-nump矩陣Matrix(rank=2)
a4 = np.array([[5,6,7],[2,8,9]])
print('nump矩陣Matrix=\n', a4)
#5-nump張量tensor(rank=3)
a5 = np.array([[[5,6,7],[2,8,9]],[[15,16,17],[12,18,19]]])
print('nump張量tensor=\n', a5)
成果圖示:
程式碼內容
|
張量tensor的幾何意義與坐標轉換 |
(1).張量tensor的幾何意義與坐標轉換
影片:兩個2D坐標系統,如何轉換,以張量表示(Forward 正向轉換,Backward反向轉換)
Forward 正向坐標轉換(F):
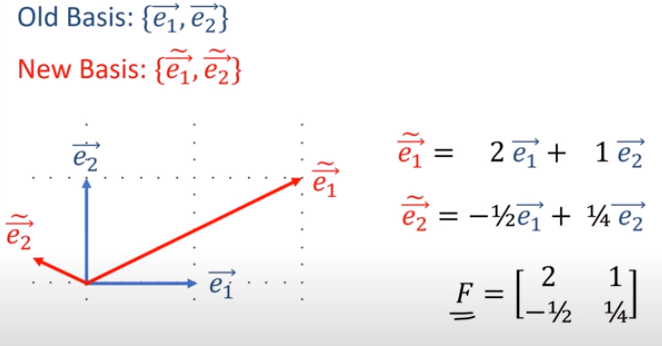
Backward逆向坐標轉換(B):
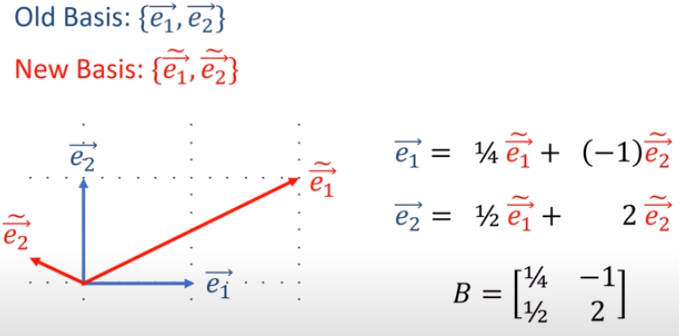
正向轉換矩陣vs反向轉換矩陣關係:反矩陣
B = F-1
F.B = 

n維空間的坐標轉換
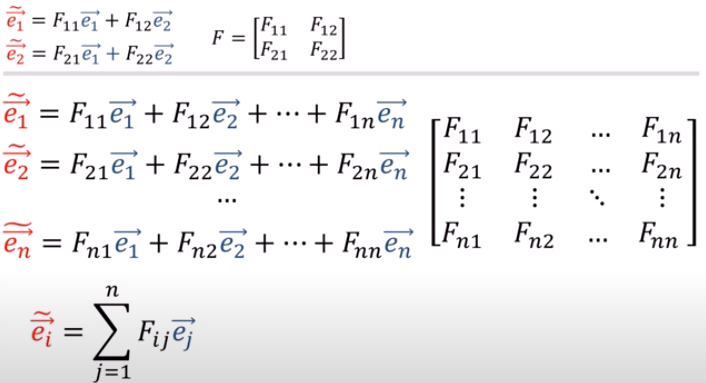
n維空間的坐標轉換
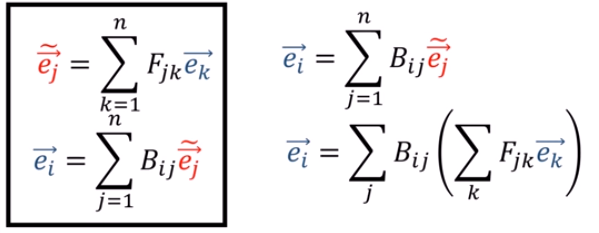
(2).向量Vector用張量表示:
影片:向量Vector用張量表示
向量的數組與運算:

向量的坐標轉換:
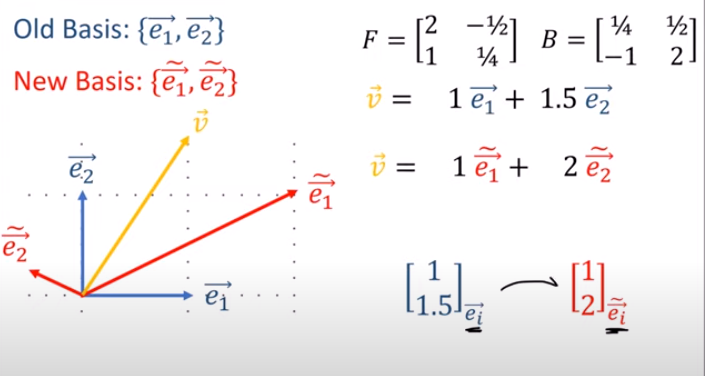
向量用正向轉換矩陣F轉換後,答案不對:

向量用正向轉,其轉換矩陣是contravariant逆變的:

向量坐標轉換,其轉換矩陣是contravariant逆變的:F,B矩陣逆變

(3).證明:向量坐標轉換的轉換矩陣是contravariant逆變的:F,B矩陣逆變
影片:證明向量坐標轉換的轉換矩陣是contravariant逆變的:F,B矩陣逆變
(4).各種正交坐標轉換:直角座標,圓柱座標,球座標
From:各種正交坐標轉換:直角座標,圓柱座標,球座標
座標系統中的向量表示式: 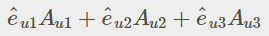
直角座標,圓柱座標,球座標
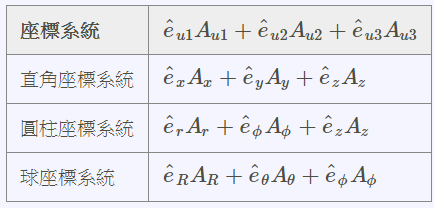
正交座標系統的基底轉換
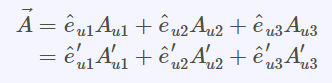
坐標基底轉換的聯立方程式
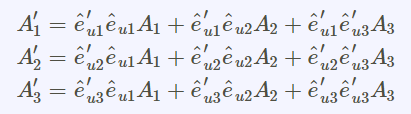
坐標基底轉換的張量矩陣關係式
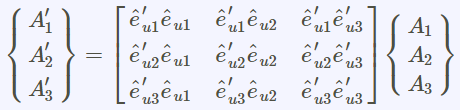
圓柱座標與直角座標系統之轉換
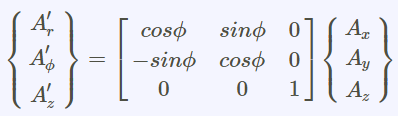
球座標與直角座標系統之轉換
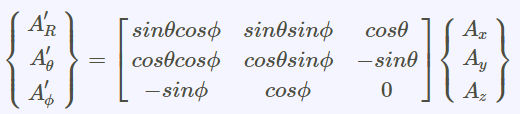
|
|
|
| |
| chp6.資料儲存與讀取1(txt,CSV、Excel、Google試算表) |
|
Python大數據分析最重要的四個模組 |
1.python讀取excel,csv有兩種方法 |
範例6-3:讀取excel檔案score.xlsx,存檔score2.xlsx |
範例6-4:讀取csv檔案score.csv,存檔scorecsv.csv |
|
範例6-5:讀取html的表格table(2020 世界大學排名) |
範例6-6:讀取cost.csv,計算總共花費多少錢 |
範例6-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量) |
範例6-8:讀取AAPL.xlsx股票檔案 |
|
範例6-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案) |
|
|
|
|
3.存取文字檔 |
範例6-6:讀取exp6-1.py的所有內容 |
範例6-7:使用迴圈,一行一行讀取exp6-1.py的所有內容 |
範例6-8:讀取目前目錄下所有檔案的文字內容 |
|
範例6-9:存入exp6-10.py,印出新年快樂 |
範例6-11:存入exp6-10.py,印出新年快樂,但是用try...except |
範例6-12:把exp112-10.py,複製到copy.py檔案 |
4.存取csv:範例6-13:讀入一個已經存在的csv檔案 |
|
範例6-14:把第一行的標題結合資料數據,形成字典格式dict |
範例6-15:新增一個新檔案,加入一筆標題,加入一筆記錄 |
範例6-16:開啟一個舊檔,加入一筆標題,加入一筆記錄 |
範例6-17:已知字典變數數據,要寫入檔案 |
|
5.存取二進位檔案:範例6-18:把對聯文字,存入二進位檔案 |
|
|
|
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組
Python資料分析最重要的四個模組:pandas、numpy、scipy、matplotlib。
(1)pandas:是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
pandas模組應該是python用來進行一般日常的大數據分析,最重要的模組了。
因為pandas的DataFrame資料結構,可以快速的互通於所有的二維結構資料,包括『excel,csv,json,xml,mysql,任何的資料庫,網頁的表格資料,字典dict,二維串列list』
也就是pandas的DataFrame資料結構,可以與它們之間互相簡易的存取。
然後再根據DataFrame來進行想要的大數據分析,它提供內建的演算法與資料結構,能夠用一個指令,就可以進行二維資料的『排序,篩選,關鍵字查詢,任意區間範圍查詢,統計學計算,平均值,變異數,標準差,字串檢索,字串取代,欄位樞紐分析、小記、欄位加總,把二維資料任意方式圖形視覺化顯示』
而建立pandas的DataFrame資料結構,有兩種方式,可以用column的方式來輸入資料,也可以用row的方式來輸入資料。
所以pandas是大數據分析,非常實用的利器工具,是python資料分析的首選。
(2)Numpy:
Numpy專門用來處理矩陣,它的運算效率比列表list串列更高效。
Numpy是Python進行專業的數值計算之重要模組,因為大多數提供科學計算的包都是用numPy的矩陣作為構建基礎,因此在進行高等數學計算時,numpy就是大數據分析的最重要工具了,因為高等數學運算,都是以矩陣的方式來進行運算,例如人工智慧,機器學習,深度學習,類神經網路計算等。
(3)sscipy:是基於numpy的科學計算包,包括統計、線性代數等工具。
(4)matplotlib:是最流行的用於繪製資料圖表的 Python 庫
也可以結合pandas模組來繪圖。
|
1.python讀取excel,csv有兩種方法 |
1.python讀取excel,csv有兩種方法:
(1)方法1:傳統python的方法:
open('customer.csv','rt',encoding='utf-8')as fin:
import csv
with open('customer.csv','rt',encoding='utf-8')as fin:
rows = csv.reader(fin,delimiter=',')
缺點:必須一列一列讀取資料,無法直接轉成DataFrame的二維結構資料
(2)方法2:pandas讀取excel,csv的方法:
import pandas as pd
df = pd.read_excel('score.xlsx','score')
#df = pd.read_excel('score.csv')
print('df['math'])
print('算出數學math的平均分數 = ', df.mean()['math'])
print('依照數學分數排序 = ', df.sort_values(by='math'))
print('計算數學math分數的標準差 = ', df.std()['math'])
優點:可以把excel資料,直接轉成DataFarme,可以直接進行排序,統計計算,篩選
|
範例6-3:讀取excel檔案score.xlsx,存檔score2.xlsx |
7.範例6-3:讀取excel檔案score.xlsx,存檔score2.xlsx
download score.xlsx
import pandas as pd
df = pd.read_excel('score.xlsx','mad3a')
print(df)
## code 1 ############################
#算出數學math的平均分數:mean:(two method)
print(df['chi'])
print('avg of math =', df['math'].mean())
print('avg of math =', df.mean()['math'])
print(df.mean()['math'])
#排序 sorting
print(df.sort_values(by='eng'))
print(df.sort_values(by='eng', ascending=False))
print(df.head(3))
print(df.sort_values(by='eng', ascending=False).head(3))
#取得某一筆get one record
print(df.iloc[3])
print(df.iloc[3,2:5].mean())
## code 2 ############################
#算出數學math的平均分數 =
print('算出數學math的平均分數 = ', df.mean()['math'])
#計算數學math分數的標準差 =
print('計算數學math分數的標準差 = ', df.std()['math'])
#印出數學math分數 > 70 =
#s70 = df['math']>70
#print('計算數學math分數的標準差 =', df(s70))
#計算mike的平均分數
mikeScore = df.iloc[1,2:5]
print('計算mike的平均分數=', mikeScore.mean())
#印出全部的人名
allname = df.iloc[:,1]
print('印出全部的人名=\n', allname)
#存檔到score2.xlsx
from pandas import ExcelWriter
writer = ExcelWriter('score2.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='score')
writer.save()
成果圖示: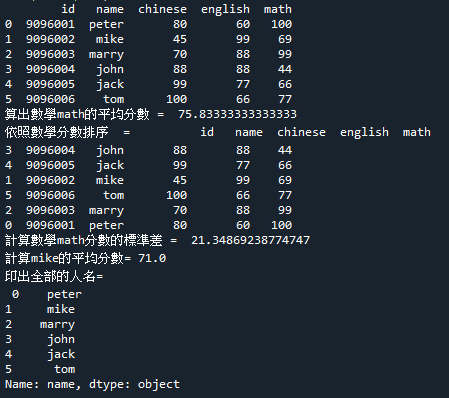
程式碼內容
|
範例6-4:讀取csv檔案score.csv,存檔scorecsv.csv |
8.範例6-4:讀取csv檔案score.csv,存檔scorecsv.csv
download score.csv
import pandas as pd
df = pd.read_csv('score.csv')
print(df)
## code 1 ############################
#算出數學math的平均分數:mean:(two method)
print(df['chi'])
print('avg of math =', df['math'].mean())
print('avg of math =', df.mean()['math'])
print(df.mean()['math'])
#排序 sorting
print(df.sort_values(by='eng'))
print(df.sort_values(by='eng', ascending=False))
print(df.head(3))
print(df.sort_values(by='eng', ascending=False).head(3))
#取得某一筆get one record
print(df.iloc[3])
print(df.iloc[3,2:5].mean())
#save to csv file
df.to_csv('score3.csv')
print('算出數學math的平均分數 = ', df.mean()['math'])
#save to excel file
df.to_excel("score4.xlsx","mad3a")
## code 2 ############################
#計算數學math分數的標準差 =
print('計算數學math分數的標準差 = ', df.std()['math'])
#印出數學math分數 > 70 =
s70 = df['math']>70
print('計算數學math分數的標準差 =', df[s70])
#計算mike的平均分數
mikeScore = df.iloc[1,2:5]
print('計算mike的平均分數=', mikeScore.mean())
#印出前面5筆
print('印出前面5筆=\n',df.head(5))
#印出全部的人名
allname = df.iloc[:,1]
print('印出全部的人名=\n', allname)
#存檔到scorecsv.csv
df.to_csv('scorecsv.csv')
成果圖示: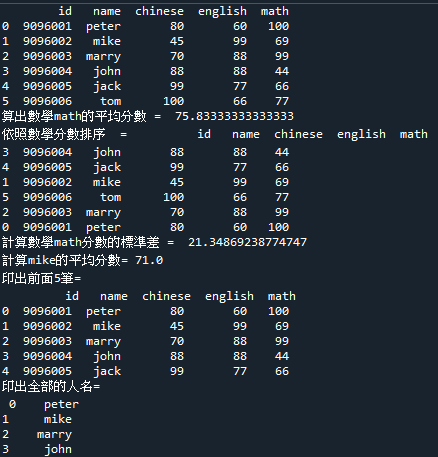
程式碼內容
|
範例6-5:讀取html的表格table(2020 世界大學排名) |
9.範例6-5:讀取html的表格table(2020 世界大學排名)
#url:https://www.idp.com/taiwan/ranking/ranking-world/
import pandas as pd
df = pd.read_html('https://www.idp.com/taiwan/ranking/ranking-world/')
#第一個表格放在df[0],第二個表格放在df[1]
#印出前5筆
print('印出前5筆=\n', df[0].head(5))
#印出排名第一名的學校名稱
print('印出排名第一名的學校名稱=',df[0].iloc[1,3])
#印出排名第三名的學校英文+中文名稱
print('印出排名第三名的學校名稱=\n',df[0].iloc[3,2:4])
#印出第二個表格:2021 QS世界大學排名(更新時間:2020/6)
#印出前5筆
print('印出前5筆=\n', df[1].head(5))
#印出排名第一名的學校名稱
print('印出排名第一名的學校名稱=',df[1].iloc[1,3])
成果圖示: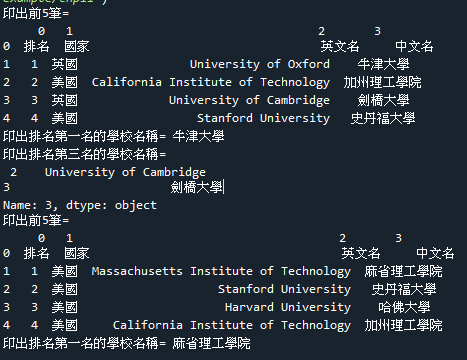
程式碼內容
|
範例6-6:讀取cost.csv,計算總共花費多少錢 |
10.範例6-6:讀取cost.csv,計算總共花費多少錢
download cost.csv
import pandas as pd
#df = pd.read_csv('cost.csv',encoding='utf-8-sig')
df = pd.read_csv('cost2.csv',encoding='utf-8')
#印出:說明,支出金額,兩個欄位
print('印出:說明,支出金額,兩個欄位=\n',df[['說明','支出金額']].head(5))
print('印出:說明個欄位=\n',df['說明'].head(5))
#計算總金額
print('花費總金額=', df.sum()['支出金額'])
print('花費總金額=', df['支出金額'].sum())
#依照金額排序
print('依照金額排序=\n',df['支出金額'].sort_values().head(5))
print('依照金額排序=\n',df.sort_values(by='支出金額').head(5))
成果圖示: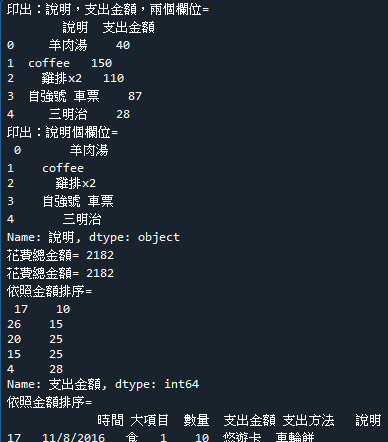
程式碼內容
|
範例6-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量) |
11.範例6-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量)
download cost.xlsx
import pandas as pd
df = pd.read_excel('cost.xlsx','sheet')
print(df)
#新增一個欄位=單價
df['單價'] = df['支出金額']/df['數量']
#印出表格:[說明,單價]
print('印出表格:[說明,單價]=\n',df[['說明','單價']])
成果圖示: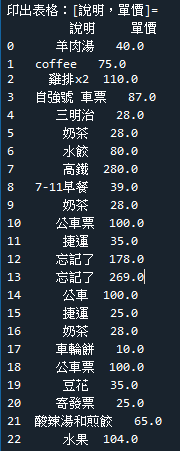
程式碼內容
|
範例6-8:讀取AAPL.xlsx股票檔案 |
12.範例6-8:畫圖股票線圖(讀取AAPL.xlsx股票檔案)
import pandas as pd
df = pd.read_excel('AAPL.xlsx','AAPL')
print('df=\n',df['Close'].head(8))
#找出收盤價高於227的記錄
find1 = df['Close'] > 227
print('找出收盤價高於194的記錄=\n', df[find1])
#找出Date=2018-02-01的記錄
print('找出Date=2018-02-01的記錄=\n',df[df['Date']=='2018-02-01'])
#找出Date= 2018-02-01~2018-02-08的記錄
find1 = (df['Date']>='2018-02-01') & (df['Date']<='2018-02-08')
#注意:要用() & (),否則會出現錯誤
print('找出Date= 2018-02-01~2018-02-08的記錄=\n', df[find1])
#顯示前5筆,顯示Date,Close
#兩種方法都可以
#print('顯示前5筆,顯示Date,Close=\n',df[['Date','Close']].head(5))
print('顯示前5筆,顯示Date,Close=\n',df[['Date','Close']][:5])
#依照交易量Volume排序,找出最低的前5筆
#兩種方法都可以
print('依照交易量Volume排序,找出最低的前5筆=\n',df.sort_values(by='Volume')[:5])
#print('依照交易量Volume排序,找出最低的前5筆=\n',df.sort_values(by=['Volume'])[:5])
#依照交易量Volume排序,找出最高的前5筆
print('依照交易量Volume排序,找出最低的前5筆=\n',df.sort_values(by='Volume', ascending=False)[:5])
#轉換2018/1/2 12:00:00 AM,抓出年月日
#取出前5筆的年
df['year'] = pd.DatetimeIndex(df['Date']).year
print('取出前5筆的年',df['year'][:5])
#計算2018年5月的成交量Volume的總和
df['month'] = pd.DatetimeIndex(df['Date']).month
#三種方法都可以
print('2018年5月的成交量Volume的總和=', df[(df['year']==2018) & (df['month']==4)]['Volume'].sum())
#print(df[df['month']==4]['Volume'].sum())
#print(df['Volume'][df['month']==4].sum())
成果圖示:
程式碼內容
成果:
df=
0 172.259995
1 172.229996
2 173.029999
3 175.000000
4 174.350006
5 174.330002
6 174.289993
7 175.279999
Name: Close, dtype: float64
找出收盤價高於194的記錄=
Date Open High ... Close Adj Close Volume
168 2018-08-31 226.509995 228.869995 ... 227.630005 225.869812 43340100
169 2018-09-04 228.410004 229.179993 ... 228.360001 226.594162 27390100
188 2018-10-01 227.949997 229.419998 ... 227.259995 225.502670 23600800
189 2018-10-02 227.250000 230.000000 ... 229.279999 227.507050 24788200
190 2018-10-03 230.050003 233.470001 ... 232.070007 230.275482 28654800
191 2018-10-04 230.779999 232.350006 ... 227.990005 226.227036 32042000
[6 rows x 7 columns]
找出Date=2018-02-01的記錄=
Date Open High ... Close Adj Close Volume
21 2018-02-01 167.169998 168.619995 ... 167.779999 164.592438 47230800
[1 rows x 7 columns]
找出Date= 2018-02-01~2018-02-08的記錄=
Date Open High ... Close Adj Close Volume
21 2018-02-01 167.169998 168.619995 ... 167.779999 164.592438 47230800
22 2018-02-02 166.000000 166.800003 ... 160.500000 157.450745 86593800
23 2018-02-05 159.100006 163.880005 ... 156.490005 153.516953 72738500
24 2018-02-06 154.830002 163.720001 ... 163.029999 159.932663 68243800
25 2018-02-07 163.089996 163.399994 ... 159.539993 156.508972 51608600
26 2018-02-08 160.289993 161.000000 ... 155.149994 152.202393 54390500
[6 rows x 7 columns]
顯示前5筆,顯示Date,Close=
Date Close
0 2018-01-02 172.259995
1 2018-01-03 172.229996
2 2018-01-04 173.029999
3 2018-01-05 175.000000
4 2018-01-08 174.350006
依照交易量Volume排序,找出最低的前5筆=
Date Open High ... Close Adj Close Volume
133 2018-07-13 191.080002 191.839996 ... 191.330002 189.187012 12513900
126 2018-07-03 187.789993 187.949997 ... 183.919998 181.859985 13954800
134 2018-07-16 191.520004 192.649994 ... 190.910004 188.771713 15043100
97 2018-05-22 188.380005 188.880005 ... 187.160004 185.063721 15240700
135 2018-07-17 189.750000 191.869995 ... 191.449997 189.305664 15534500
[5 rows x 7 columns]
依照交易量Volume排序,找出最低的前5筆=
Date Open High ... Close Adj Close Volume
182 2018-09-21 220.779999 221.360001 ... 217.660004 215.976913 96246700
212 2018-11-02 209.550003 213.649994 ... 207.479996 205.875610 91328700
22 2018-02-02 166.000000 166.800003 ... 160.500000 157.450745 86593800
23 2018-02-05 159.100006 163.880005 ... 156.490005 153.516953 72738500
27 2018-02-09 157.070007 157.889999 ... 156.410004 154.064056 70672600
[5 rows x 7 columns]
取出前5筆的年 0 2018
1 2018
2 2018
3 2018
4 2018
Name: year, dtype: int64
2018年5月的成交量Volume的總和= 666057900
|
範例6-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案) |
13.範例6-9:畫圖股票線圖(讀取AAPL.xlsx股票檔案)
#使用Matplotlib模組
#結合pandas 與 matplotlib = df.plot(x='..',y='..',color='red')
import pandas as pd
import matplotlib.pyplot as plt
#畫圖-line:Date vs Close (預設 kind= line)
df = pd.read_excel('AAPL.xlsx','AAPL')
#plt.plot([1,2,3,4,5,6])
df.plot(x='Date', y='Close',grid=True, color='red',label='Close')
#df.plot(x=df['Date'], y=df['Close'],grid=True, color='red')
plt.show()
#畫圖-bar:Date vs Close (kind= scatter)
#line線圖,bar柱狀圖,scatter散佈圖,bar水平柱狀圖,hist直方圖,box盒鬚圖
df.plot(x='Date', y='Close',grid=True, color='red',label='Close',kind='scatter')
plt.show()
#在同一圖fig,同一個軸ax,畫出三條線(Open,Close,High)
labels = ['Open','Close','High']
fig,ax = plt.subplots()
for name in labels:
df.plot(x='Date',y=name, ax=ax, label=name)
plt.show()
成果圖示:
成果圖示:
成果圖示:
程式碼內容
|
3.存取文字檔 |
3.存取文字檔
(1).常用指令
#☎開啟檔案:a1 = open(檔名,模式mode,文字子編碼)
a1 = open('exp11_01.py','rt',encoding='utf-8')
#☎模式mode種類:
r:只能讀取
w:可以寫入(會先刪除原先的檔案)
x:可以寫入(但是檔案不能已經存在,避免覆蓋)
a:可以寫入(把寫入資料,寫在檔案最後加入)
t:純文子檔
b:二進位檔
+:可以讀取,可以寫入
#☎讀取全部檔案:a1.read()
#☎讀取檔案裡面的一行:a1.readline()
#☎讀取檔案裡面的每一行,並把它們變成串列:a1.readlines()
#☎把字串寫入檔案:a1.write(字串)
#☎把字串寫入檔案:print(字串,file=檔案物件)
檔案物件 = open('exp11_01.py','rt',encoding='utf-8')
|
範例6-6:讀取exp6-1.py的所有內容 |
(1).範例6-6.py
目的:讀取exp6-1.py的所有內容
下載:exp6-1.py
f1 = 'exp6-1.py'
a1 = open(f1,'rt',encoding='utf-8')
print(a1.read())
a1.close()
成果圖示:
程式碼內容
|
範例6-7:使用迴圈,一行一行讀取exp6-1.py的所有內容 |
(2).範例6-7.py
目的:使用迴圈,一行一行讀取exp6-1.py的所有內容
下載:exp6-1.py
f1 = 'exp6-1.py'
a1 = open(f1,'rt',encoding='utf-8')
for i in a1:
print(i)
a1.close()
成果圖示:
程式碼內容
|
範例6-8:讀取目前目錄下所有檔案的文字內容 |
(3).範例6-8.py
目的:讀取目前目錄下所有檔案的文字內容
import os
a1 = os.listdir()
for i in a1:
if os.path.isfile(i)==True:
print('檔案名稱=',i)
f1 = open(i,'rt',encoding='utf-8')
print(f1.read())
f1.close()
程式碼內容
|
範例6-9:存入exp6-10.py,印出新年快樂 |
(4).範例6-9.py
目的:寫一個程式,存入exp6-10.py,印出『新年快樂』
f1 = 'exp6-10.py'
txt ="""
s1 = input('輸入您的姓名=')
print(s1,'新年快樂')
"""
#將程式寫入檔案內
a1 = open(f1,'wt',encoding='utf-8')
a1.write(txt)
a1.close()
程式碼內容
|
範例6-11:存入exp6-10.py,印出新年快樂,但是用try...except |
(5).範例6-11.py
目的:寫一個程式,存入exp6-10.py,印出『新年快樂』,但是用try...except
測試寫入程式是否發生問題?
f1 = 'exp6-10.py'
txt ="""
s1 = input('輸入您的姓名=')
print(s1,'新年快樂')
"""
#將程式寫入檔案內
try:
a1 = open(f1,'twt',encoding='utf-8')
a1.write(txt)
a1.close()
except:
print('無法寫入檔案')
程式碼內容
|
範例6-12:把exp112-10.py,複製到copy.py檔案 |
6).範例6-12.py
目的:複製檔案,把exp6-10.py,複製到copy.py檔案
f1 = 'exp6-10.py'
f2 = 'copy.py'
a1 = open(f1,'rt',encoding='utf-8')
a2 = open(f2,'wt',encoding='utf-8')
txt = a1.read()
a2.write(txt)
a1.close()
a2.close()
程式碼內容
|
4.存取csv:範例6-13:讀入一個已經存在的csv檔案 |
4.存取csv檔
(1).範例6-13.py
讀入一個已經存在的csv檔案
(下載檔案: customer.csv到exp6-11.py同一個目錄)
#讀入一個已經存在的csv檔案: customer.csv
#方法1:缺點,無法指定印出:第二筆記錄的公司名稱(因為都是純文字,不是陣列或串列list)
a1 = open('customer.csv','rt',encoding='utf-8')
txt = a1.read()
print(txt)
a1.close()
#方法2:import csv模組,然後用with open('customer.csv','rt',encoding='utf-8')as fin:
import csv
with open('customer.csv','rt',encoding='utf-8')as fin:
rows = csv.reader(fin,delimiter=',')
#指定印出:第二筆記錄的公司名稱
listrow = list(rows)
print(listrow[1][1])
for i in listrow:
print(i)
結果:包括第一行的標題
[['客戶編號', '公司名稱', '連絡人', '連絡人職稱'], ['ALFKI', '三川實業有限公司', '陳小姐', '業務'], ['ANATR', '東南實業', '黃小姐', '董事長'], ['ANTON', '坦森行貿易', '胡先
生', '董事長']]
若是希望把第一行當作是標題,而不是資料列的做法
而且希望顯示字典(dictionary),顯示把{標題欄位1:數據},{標題欄位2:數據}....
程式碼內容
|
範例6-14:把第一行的標題結合資料數據,形成字典格式dict |
(2).範例6-14.py
#目的:把第一行的標題結合資料數據,形成字典格式dict
#☎重點:rows = csv.DictReader(fin,delimiter=',')
不是rows = csv.Reader(fin,delimiter=',')
#把customer.csv第一行的標題結合資料數據,形成字典格式dict
import csv
with open('customer.csv','r',encoding='utf-8')as fin:
rows = csv.DictReader(fin,delimiter=',')
for row in rows:
print(row)
print(row['公司名稱'])
結果:
OrderedDict([('\ufeff客戶編號', 'ALFKI'), ('公司名稱', '三川實業有限公司'), ('連絡人', '陳小姐'), ('連絡人職稱', '業務')])
三川實業有限公司
OrderedDict([('\ufeff客戶編號', 'ANATR'), ('公司名稱', '東南實業'), ('連絡人', '黃小姐'), ('連絡人職稱', '董事長')])
東南實業
OrderedDict([('\ufeff客戶編號', 'ANTON'), ('公司名稱', '坦森行貿易'), ('連絡人', '胡先生'), ('連絡人職稱', '董事長')])
坦森行貿易
程式碼內容
|
範例6-15:新增一個新檔案,加入一筆標題,加入一筆記錄 |
(3).範例6-15.py
#目的:新增一個新檔案,加入一筆標題,加入一筆記錄
#☎重點:wt = csv.writer(fout,delimiter=',')
wt.writerow(['AL001','全聯有限公司','張三','司機'])
#新增一個新檔案test.csv,加入一筆標題,加入一筆記錄:['AL001','全聯有限公司','張三','司機']
import csv
with open('test1.csv','w',encoding='utf-8',newline='')as fout:
#若不設定換行字元 = newline='',則會造成間隔一行(多一行空白行)
wt = csv.writer(fout,delimiter=',')
wt.writerow(['客戶編號', '公司名稱', '連絡人', '連絡人職稱'])
wt.writerow(['AL001','全聯有限公司','張三','司機'])
print('已經成功加入test.csv檔案')
程式碼內容
|
範例6-16:開啟一個舊檔,加入一筆標題,加入一筆記錄 |
(4).範例6-16.py
#目的:開啟一個舊檔test1.csv,加入一筆標題,加入一筆記錄
#☎重點:with open('test1.csv','a',newline='')as fout:
#☎其中的'a' = 寫入,若是原本的檔案已經存在,保留原本資料,在最後新增
import csv
with open('test1.csv','a',encoding='utf-8',newline='')as fout:
wt = csv.writer(fout,delimiter=',')
wt.writerow(['客戶編號', '公司名稱', '連絡人', '連絡人職稱'])
wt.writerow(['AL005','7-11有限公司','李四','經理'])
print('已經成功加入test.csv檔案')
程式碼內容
|
範例6-17:已知字典變數數據,要寫入檔案 |
(5).範例6-17.py
#目的:已知字典變數數據,要寫入檔案(以字典方式寫入,但是卻顯示第一行標題,第二行資料數據)
#☎重點:wt = csv.DictWriter(fout,atitle)
wt.writeheader()
wt.writerow(adata)
import csv
atitle = ['客戶編號', '公司名稱', '連絡人', '連絡人職稱']
with open('test2.csv','w',newline='')as fout:
wt = csv.DictWriter(fout,atitle)
wt.writeheader()
wt.writerow({'客戶編號':'AL005', '公司名稱':'7-11有限公司', '連絡人':'李四', '連絡人職稱':'主任'})
wt.writerow({'客戶編號':'AL006', '公司名稱':'麥當勞公司', '連絡人':'王五', '連絡人職稱':'經理'})
結果:
客戶編號,公司名稱,連絡人,連絡人職稱
AL005,7-11有限公司,李四,主任
AL006,麥當勞公司,王五,經理
程式碼內容
|
範例6-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案) |
13.範例11-9:畫圖股票線圖(讀取AAPL.xlsx股票檔案)
#使用Matplotlib模組
#結合pandas 與 matplotlib = df.plot(x='..',y='..',color='red')
import pandas as pd
import matplotlib.pyplot as plt
#畫圖-line:Date vs Close (預設 kind= line)
df = pd.read_excel('AAPL.xlsx','AAPL')
#plt.plot([1,2,3,4,5,6])
df.plot(x='Date', y='Close',grid=True, color='red',label='Close')
#df.plot(x=df['Date'], y=df['Close'],grid=True, color='red')
plt.show()
#畫圖-bar:Date vs Close (kind= scatter)
#line線圖,bar柱狀圖,scatter散佈圖,bar水平柱狀圖,hist直方圖,box盒鬚圖
df.plot(x='Date', y='Close',grid=True, color='red',label='Close',kind='scatter')
plt.show()
#在同一圖fig,同一個軸ax,畫出三條線(Open,Close,High)
labels = ['Open','Close','High']
fig,ax = plt.subplots()
for name in labels:
df.plot(x='Date',y=name, ax=ax, label=name)
plt.show()
成果圖示:
成果圖示:
成果圖示:
程式碼內容
|
| |
| |
| chp8.資料儲存與讀取3(存取xml,json) |
| 上課範例 |
範例8-1:讀取json檔案有兩種方法 |
範例8-2:pandas讀取同一目錄的json檔案 |
範例8-3:pandas讀 取URL json檔案 |
|
| 觀摩範例 |
1.存取xml:模組:xml.etree.ElementTree |
範例8-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料 |
範例8-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信 |
範例8-3:修改並存入xml |
|
線上XML/JSON互相轉換工具 |
2.讀取網頁:request(url) |
範例8-4:讀取網頁:web = request.urlopen(網址) |
3.存取 json(模組:json) |
|
範例8-5:轉成json:jumps。轉成dict:loads |
範例8-6:讀取網絡上的json檔案 |
範例8-7:讀取電腦上的json檔案 |
|
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組
Python資料分析最重要的四個模組:pandas、numpy、scipy、matplotlib。
(1)pandas:是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
pandas模組應該是python用來進行一般日常的大數據分析,最重要的模組了。
因為pandas的DataFrame資料結構,可以快速的互通於所有的二維結構資料,包括『excel,csv,json,xml,mysql,任何的資料庫,網頁的表格資料,字典dict,二維串列list』
也就是pandas的DataFrame資料結構,可以與它們之間互相簡易的存取。
然後再根據DataFrame來進行想要的大數據分析,它提供內建的演算法與資料結構,能夠用一個指令,就可以進行二維資料的『排序,篩選,關鍵字查詢,任意區間範圍查詢,統計學計算,平均值,變異數,標準差,字串檢索,字串取代,欄位樞紐分析、小記、欄位加總,把二維資料任意方式圖形視覺化顯示』
而建立pandas的DataFrame資料結構,有兩種方式,可以用column的方式來輸入資料,也可以用row的方式來輸入資料。
所以pandas是大數據分析,非常實用的利器工具,是python資料分析的首選。
(2)Numpy:
Numpy專門用來處理矩陣,它的運算效率比列表list串列更高效。
Numpy是Python進行專業的數值計算之重要模組,因為大多數提供科學計算的包都是用numPy的陣列作為構建基礎,因此在進行高等數學計算時,numpy就是大數據分析的最重要工具了,因為高等數學運算,都是以矩陣的方式來進行運算,例如人工智慧,機器學習,深度學習,類神經網路計算等。
(3)sscipy:是基於numpy的科學計算包,包括統計、線性代數等工具。
(4)matplotlib:是最流行的用於繪製資料圖表的 Python 庫
也可以結合pandas模組來繪圖。
|
範例8-1:讀取json檔案有兩種方法: |
1.讀取json檔案有兩種方法:
(1)方法1:傳統python的方法:
f1 = open('school.json','rt',encoding='utf-8-sig')
txt = f1.read()
#json轉成字典
d1 = json.loads(txt)
print('第一個學校 = ',d1[0]['name'], d1[0]['address'])
print('全部學校 =')
for elem in d1:
print(elem['name'],elem['address'])
缺點:必須一列一列讀取資料,無法直接轉成DataFrame的二維結構資料
(2)方法2:pandas讀取json的方法:
import pandas as pd
df = pd.read_json(txt,encoding='utf-8-sig')
print(df[['說明','支出金額']][:5])
注意1:若是json檔案有中文字,必須加上encoding='utf-8-sig'或是encoding='utf-8'
注意2:若是json檔案的格式是utf-8,必須加上encoding='utf-8'
注意3:若是json檔案的格式是具有BOM格式的utf-8,必須加上encoding='utf-8-sig'
優點:可以把json直接轉成DataFarme,可以直接進行排序,統計計算,篩選,畫圖
☎下載json資料庫:下載cost.json
☎成果圖示: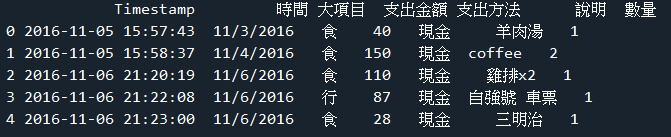
☎程式碼檔案:程式碼內容(a)
|
範例8-2:pandas讀取同一目錄的json檔案 |
14.範例8-2:pandas讀取同一目錄的json檔案
import pandas as pd
#讀取同目錄的cost.json
f1 = open('cost.json','rt',encoding='utf-8-sig')
txt = f1.read()
df = pd.read_json(txt)
print(df[['說明','支出金額']][:5])
#計算總金額
print('計算支出總金額=',df['支出金額'].sum())
#找出支出金額最高的前5個
print('找出支出金額最高的前5個=\n', df.sort_values(by='支出金額',ascending=False)[:5])
#找出支出金額超過200的記錄
cost200 = df['支出金額'] > 200
print('找出支出金額超過200的記錄=\n',df[['說明','大項目','支出金額']][cost200])
#找出大項目是『行』的記錄
itemRide = df['大項目'] == '行'
print('找出大項目是『行』的記錄=\n',df[['說明','大項目','支出金額']][itemRide])
#計算『行』的總金額
print('計算『行』的總金額=',df['支出金額'][itemRide].sum())
itemRide = df['大項目'] == '食'
print('計算『食』的總金額=',df['支出金額'][itemRide].sum())
#畫出每天的花費圖
import matplotlib.pyplot as plt
df.plot(x='時間', y='支出金額',grid=True, color='red',label='cost')
plt.show()
#找出『行,食』兩類的總金額
df.groupby('大項目')['支出金額'].sum().plot(kind='bar',stacked=True)
plt.show()
#畫出每天的花費(要先累計每天金額)
df.groupby('時間')['支出金額'].sum().plot(kind='bar')
(1)練習範例exp8-2(a)
☎下載json資料庫:下載cost.json
☎成果圖示: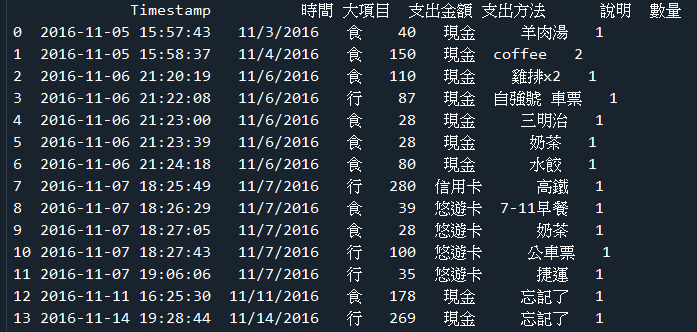
☎程式碼檔案:程式碼內容(a)
(2)練習範例exp8-2(b)
成果圖示: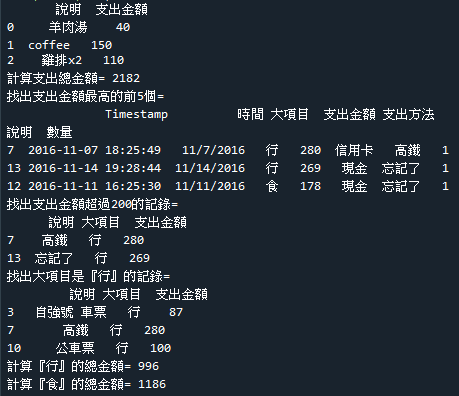
成果圖示: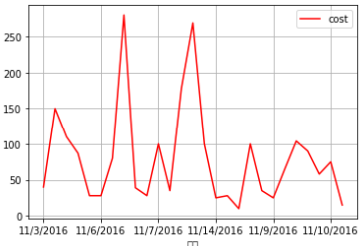
成果圖示: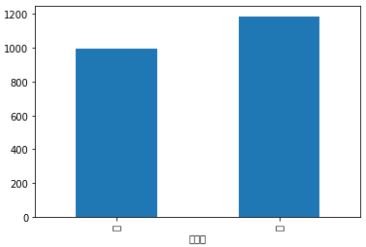
成果圖示: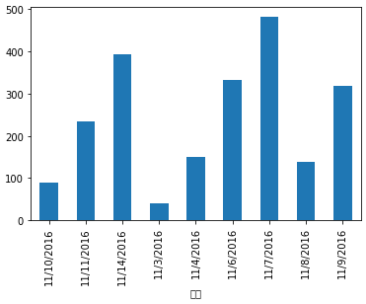
下載cost.json
程式碼內容
|
範例8-3:pandas讀 取URL json檔案 |
15.範例8-3:pandas讀 取URL json檔案
# Load JSON from URL
import pandas as pd
import urllib.request as request
#全國役政單位資料
url = 'https://od.moi.gov.tw/od/data/api/EA28418E-8956-4790-BAF4-C2D3988266CC?$format=json'
web = request.urlopen(url)
txt = web.read()
#print(txt)
#印出前5筆記錄
df = pd.read_json(txt)
print(df[:5])
#找出役政單位的名稱(前6筆)
print('找出役政單位的名稱(前6筆)=\n',df['unit'][:6])
#找出金門役政單位的地址,電話
find1 = df['address'].str.contains('金門')
print('找出金門役政單位的地址,電話=\n',df[['unit','address','telephon']][find1])
(1)練習範例exp8-3(a)
☎json資料庫:https://od.moi.gov.tw/od/data/api/EA28418E-8956-4790-BAF4-C2D3988266CC?$format=json
☎成果圖示: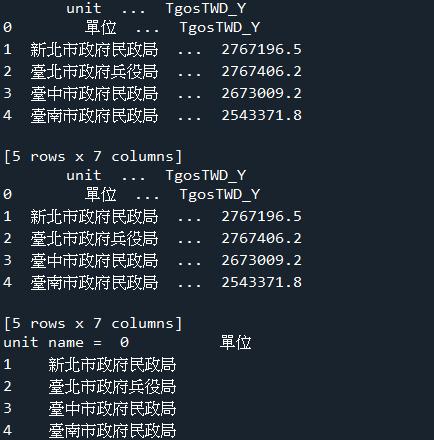
☎成果圖示: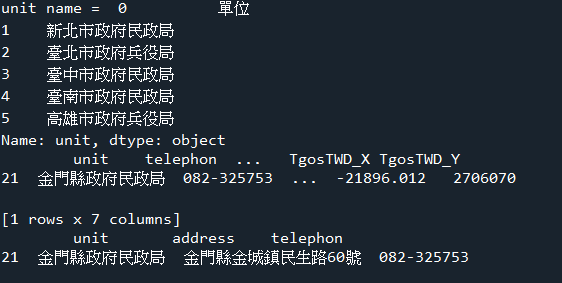
☎程式碼檔案:程式碼內容(a)
(2)練習範例exp8-3(b)
成果圖示: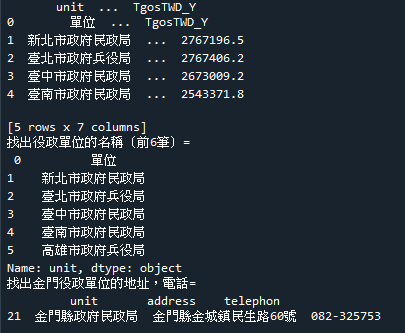
程式碼內容
|
1.存取xml:模組:xml.etree.ElementTree |
1.存取xml
(1).模組:xml.etree.ElementTree
import xml.etree.ElementTree as xml
(2).讀取整個xml結構的兩種方法:
☎方法1:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
root = tree.getroot()
for child in root:
...................
☎方法2:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
for elem in tree.iter():
............
(3).存取xml方法
1、ElementTree例項代表整個XML樹,可以使用getroot()來獲取根節點。Element表示樹上的單個節點,它是iterable的。操作整個XML文件時使用ElementTree類,比如讀寫XML檔案。操作XML元素及其子元素時使用Element類。
2、xml.etree.cElementTree是用C語言實現的模組,介面上與xml.etree.ElementTree完全相同,然而處理效率更快,但並不是所有平臺均支援,因為我們可以嘗試匯入,若沒有就匯入ElementTree
3、每個元素包含如下屬性:
tag:string物件,表示資料代表的種類。
attrib:dictionary物件,表示附有的屬性。
text:string物件,表示element的內容。
tail:string物件,表示element閉合之後的尾跡。
若干子元素(child elements)
4、查詢方法:
Element.findall(match)方法通過tag名字或xpath匹配第一層子元素,按照子元素順序以列表形式返回所有匹配的元素。
Element.find(match)方法通過tag名字或xpath在第一層子元素中查詢第一個匹配的元素,返回匹配的元素或None。
Element.get(key, default=None)返回元素名字為key的屬性值,如果沒有找到,返回None或設定的預設值。
5、通過Element物件的方法修改Element物件
Element.text=value可以直接修改其text屬性。
Element.tail=value可以直接修改其tail屬性。
Element.set(key, vlaue)可以新增新的attrib。
Element.append(subelement)可以新增新的子元素。
Element.extend(subelements)新增子元素的列表(引數型別是序列)。
Element.remove(subelement)可以刪除子元素
6、使用ET.SubElement(parent, tag_name)可以快速建立子元素關係,使用ET.dump(elem)可以輸出elem的內容到標準輸出(elem可以是一個Element物件或ElementTree物件)
7、ET.parse(filename)一次性將整個XML檔案載入到記憶體,ET.iterparse(filename)採用增量形式載入XML資料,佔據更小的記憶體空間。
|
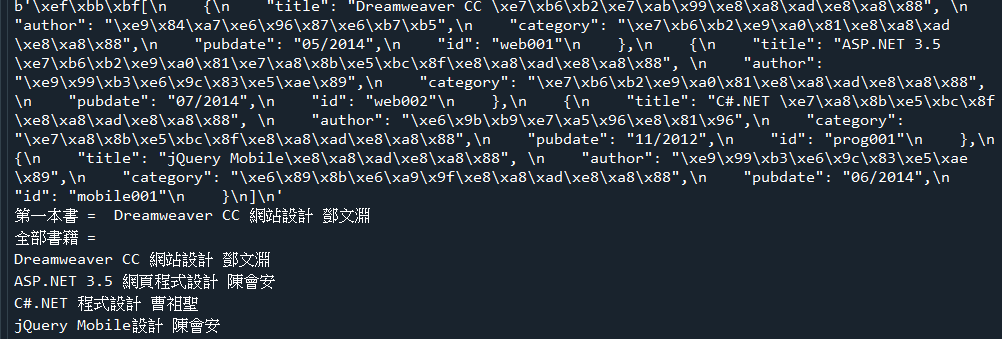
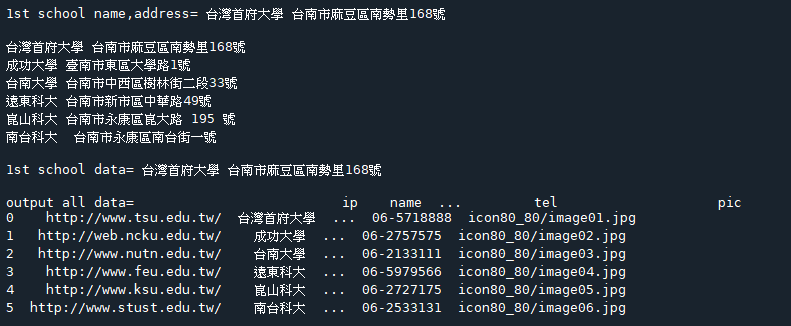
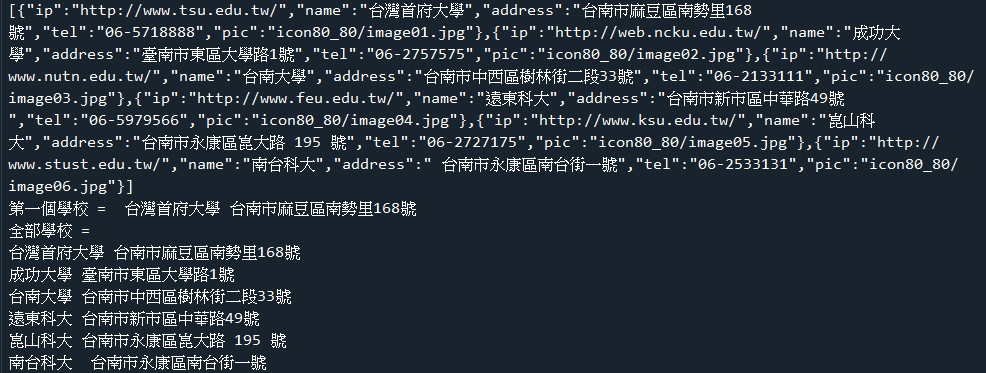
範例8-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料 |
☎方法1:範例8-1.py
下載person.xml
#目的讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信的個人所有資料
程式碼:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
root = tree.getroot()
print('根目錄的標籤名稱',root.tag)
# root.tag 讀取 tag 名
# root.attrib 讀取 attributes
# root[0][1].rank 讀取文本值
#輸出根節點元素的tag名:person
print(root.tag)
#輸出根節點元素的attributes(空值):{}
print(root.attrib)
#輸出第一個的三個子元素的值:
print(root[0][0].text)
print(root[0][1].text)
print(root[0][2].text)
#查找所有子孫元素:tag標籤 = name
for elem in root.iter('name'):
print(elem.tag, elem.attrib, elem.text)
#比較find() 和 findall()
#查找第一個子元素:find()
print(list(root.find('student')))
#查找所有子元素:findall()
print(list(root.findall('student')))
#查找所有子元素:findall()
#tree.findall('student/*') //查詢孫子節點元素
for elem in root.findall('student/*'):
print(elem.tag, elem.text)
#tree.findall('.//name') //查詢任意層次元素
for elem in root.findall('.//tel'):
print(elem.tag, elem.text)
#查詢 包含name屬性的student
#查詢tree.findall('student[@name]')
for elem in root.findall('student[@name]'):
print(elem.tag, elem[1].text)
#查詢 name屬性為卓水信的student
#tree.findall('student[name="卓水信"]')
for elem in root.findall('student[name="卓水信"]'):
print('id=',elem[0].text)
print('name=',elem[1].text)
print('tel=',elem[2].text)
#顯示 第一個student
for elem in tree.findall('student[1]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示 第二個student
for elem in tree.findall('student[2]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示最後一個student
#tree.findall('student[last()]')
for elem in tree.findall('student[last()]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示倒數第二個country
#tree.findall('country[last()-1]')
for elem in tree.findall('student[last()-1]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示第1階層所有階層的標籤名稱,屬性
print('顯示第1階層所有階層的標籤名稱,屬性:')
for child in root:
print(child.tag, child.attrib, child.text)
#顯示第2階層的標籤名稱,文字值
print('顯示第2階層的標籤名稱,文字值:')
for i,child1 in enumerate(root):
print(child1.tag,i)
for child2 in child1:
print(child2.tag, '=', child2.text)
#查詢某個tag標籤名稱
print('查詢某個tag標籤名稱:')
for elem in root.iterfind('student/mail'):
print(elem.tag,'=',elem.text)
#查詢某個tag標籤tel的所有文字
print('查詢某個tag標籤的所有文字:')
for elem in root:
print(elem.find('tel').text)
#查詢卓水信是否存在
print('查詢卓水信是否存在:方法1')
#方法1
for elem in root.findall('student[name="卓水信"]'):
if elem[1].text=='卓水信':
print(elem[1].text,'存在')
print('查詢卓水信是否存在:方法2')
#方法2
for elem in tree.iter():
if elem.text=='卓水信':
print(elem.tag,'=',elem.text,'存在')
#查詢卓水信的個人所有資料
#方法1
print('\n查詢卓水信的個人所有資料:方法1')
for elem in root.findall('student[name="卓水信"]'):
print(elem[0].text, elem[1].text,elem[2].text)
#方法2
print('\n查詢卓水信的個人所有資料:方法2')
for elem1 in tree.iter():
for elem2 in elem1:
if elem2.text=='卓水信':
print('name =',elem1.find('name').text)
print('tel =',elem1.find('tel').text)
print('mail =',elem1.find('mail').text)
程式碼內容
|
範例8-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信 |
☎方法2範例8-2.py
#目的讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信的個人所有資料
程式碼:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
root = tree.getroot()
print(root.tag)
#1.顯示所有的tag name
print('1.顯示所有的tag name')
for elem in tree.iter():
print(elem.tag, elem.attrib,elem.text)
#2.尋找某個tag name的資料 = tree.iterfind('tag name')
print("2.尋找某個tag name的資料 = tree.iterfind('tag name')")
for elem in tree.iterfind('student/tel'):
print(elem.tag, elem.attrib,elem.text)
#3.尋找某個tag attribute的資料 = tree.iterfind('tag name[@attribute]')
print('3.尋找某個tag attribute的資料 ')
for elem in tree.iterfind('student[@hash="1cdf045c1"]'):
print(elem.tag,'=',elem.attrib)
#4.#查詢卓水信的個人所有資料
for elem1 in tree.iter():
for elem2 in elem1:
if elem2.text=='卓水信':
print('name =',elem1.find('name').text)
print('tel =',elem1.find('tel').text)
print('mail =',elem1.find('mail').text)
程式碼內容
|
範例8-3:修改並存入xml |
(3).修改並存入xml文檔
☎範例8-3.py
#修改卓水信的個人id_no = 999999
程式碼:
#修改並存入xml文檔
#修改卓水信的個人id_no = 999999
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
root = tree.getroot()
#顯示卓水信的資料
for elem in root.findall('student[name]'):
if elem[1].text == '卓水信':
print(elem[0].text,elem[1].text,elem[2].text)
#修改卓水信的電話
elem[2].text = "0912456789"
print(elem[0].text,elem[1].text,elem[2].text)
#存檔person2.xml
tree.write('person2.xml')
#重新讀入,#顯示卓水信的資料
tree = xml.ElementTree(file='person2.xml')
root = tree.getroot()
for elem in root.findall('student[name]'):
if elem[1].text == '卓水信':
print(elem[0].text,elem[1].text,elem[2].text)
程式碼內容
|
線上XML/JSON互相轉換工具 |
線上XML/JSON互相轉換工具:
http://tools.itread01.com/code/xmljson
線上格式化XML/線上壓縮XML:
http://tools.itread01.com/code/xmlformat
XML線上壓縮/格式化工具:
http://tools.itread01.com/code/xml_format_compress
XML程式碼線上格式化美化工具:
http://tools.itread01.com/code/xmlcodeformat
更多關於Python相關內容感興趣的讀者可檢視:
《Python操作xml資料技巧總結》、《Python資料結構與演算法教程》、《Python Socket程式設計技巧總結》、《Python函式使用技巧總結》、《Python字串操作技巧彙總》、《Python入門與進階經典教程》及《Python檔案與目錄操作技巧彙總》
https://www.itread01.com/article/1535600015.html
|
2.讀取網頁:request(url) |
2.讀取網頁:request(url)
☎模組:import urllib.request as request
☎讀取網頁:web = request.urlopen(網址)
☎讀取網頁內容並解碼 = web.read().decode()
|
範例8-4:讀取網頁:web = request.urlopen(網址) |
☎範例8-4.py
程式碼:
#網路爬蟲:讀取網頁:web = request.urlopen(網址)
import urllib.request as request
url = "http://web.tsu.edu.tw/bin/home.php"
web = request.urlopen(url)
print('網址=',web.url)
print('狀態(200表示OK)=',web.status)
print('取得網頁標頭=',web.getheader)
txt = web.read()
#print('取得網頁內容(byte格式)=',txt)
print('取得網頁內容(解碼byte格式)=',txt.decode())
程式碼內容
|
3.存取 json(模組:json) |
3.存取 json
(1).模組:json
import json
(2).把字典dict轉換成json
公式:json = json.dumps(字典)
(3).把json轉換成字典
公式:字典 = json.loads(json)
|
範例8-5:轉成json:jumps。轉成dict:loads |
(4).☎範例8-5.py
程式碼:
#dict轉成json:dumps
#json轉成dict:loads
import json
#把字典dict轉成json:dumps
a1 = {'tom':'0912456789','mike':'0965258741','peter':'0965789365'}
j1 = json.dumps(a1)
print(j1)
#把串列list轉成json:dumps
a2 = [['tom','湯姆'],['mike','麥克'],['peter','彼德']]
j2 = json.dumps(dict(a2))
print(j2)
#把json(j1)轉成字典dict:loads
d1 = json.loads(j1)
print('tom tel =',d1['tom'])
#把json(j2)轉成字典dict:loads
d2 = json.loads(j2)
print('tom name=',d2['tom'])
程式碼內容
|
範例8-6:讀取網絡上的json檔案 |
(5).讀取網絡上的json檔案
☎範例8-6.py
#目的:讀取網路上一個json檔案:http://acupun.site/lecture/jquery_phoneGap/json/book.json
程式碼:
#讀取網路上一個json檔案:http://acupun.site/lecture/jquery_phoneGap/json/book.json
import json
import urllib.request as request
url = "http://acupun.site/lecture/jquery_phoneGap/json/book.json"
web = request.urlopen(url)
txt = web.read()
#txt = web.read().decode()
print(txt)
#json轉成字典
d1 = json.loads(txt)
print('第一本書 = ',d1[0]['title'], d1[0]['author'])
print('全部書籍 =')
for elem in d1:
print(elem['title'],elem['author'])
程式碼內容
|
範例8-7:讀取電腦上的json檔案 |
(6).讀取電腦上的json檔案
☎範例8-7.py
程式碼:
#讀取本機電腦上的json檔案:school.json
import json
#Python中utf-8與utf-8-sig兩種編碼格式的區別:
#(1).UTF-8以位元組為編碼單元,它的位元組順序在所有系統中都是一様的,沒有位元組序的問題,也因此它實際上並不需要BOM(“ByteOrder Mark”)。
#(2).但是UTF-8 with BOM,即utf-8-sig,則需要提供BOM。
#(3).json檔案必須獲取content再用utf-8-sig decode
f1 = open('school.json','rt',encoding='utf-8-sig')
txt = f1.read()
print(txt)
#json轉成字典
d1 = json.loads(txt)
print('第一個學校 = ',d1[0]['name'], d1[0]['address'])
print('全部學校 =')
for elem in d1:
print(elem['name'],elem['address'])
程式碼內容
|
| |
| |
| chp11.網絡大數據爬取與分析3(Pandas數據分析與資料存取) |
|
1.大數據分析的工具 |
Python大數據分析最重要的四個模組 |
3.Pandas基礎功能: |
4.Pandas的資料結構 |
|
範例11-1:建立一維陣列資料Series |
範例11-1:用pandas建立DataFrame的三種方法 |
範例11-2:把二維字典(dict)資料,轉成DataFrame,找出分數>80 |
範例11-3:讀取excel檔案score.xlsx,存檔 |
|
範例11-4:讀取csv檔案score.csv,存檔 |
範例11-5:讀取html的表格table |
範例11-6:讀取cost.csv,計算總共花費多少錢 |
範例11-7:讀取cost.xlsx,計算新欄位=單價 |
|
範例11-8:讀取AAPL.xlsx股票檔案 |
範例11-9:結合pandas 與 matplotlib 畫圖股票線圖 |
範例11-10:pandas讀取同一目錄的json檔案 |
範例11-11:pandas讀 取URL json檔案 |
|
範例11-12:用pandas直接查詢讀取mySQL |
範例11-13:用pandas把dataframe儲存成json檔案 |
|
|
1.大數據分析的工具 |
1.大數據分析的工具:
(1)有很多專為資料分析與量化研究所設計的商業軟體,例如:SPSS、SAS和Stata等,都能進行這項任務,但共通問題是價格不便宜。
(2)免費的資料分析開源軟體,包括:「R」,Python+Pandas。
A).Python:由Guido van Rossum創建,於1991年首次發布,設計哲學為「優雅」、「明確」、「簡單」,其直譯式、易擴充和跨平台的特性,加上豐富多元的第三方函式庫和社群,使其在各種程式應用上都能看見它的身影,
例如:網頁開發、系統管理、資料處理、科學計算,以及近年熱門的機器學習和深度學習。
|
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組
Python資料分析最重要的四個模組:pandas、numpy、scipy、matplotlib。
(1)pandas:是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
pandas模組應該是python用來進行一般日常的大數據分析,最重要的模組了。
因為pandas的DataFrame資料結構,可以快速的互通於所有的二維結構資料,包括『excel,csv,json,xml,mysql,任何的資料庫,網頁的表格資料,字典dict,二維串列list』
也就是pandas的DataFrame資料結構,可以與它們之間互相簡易的存取。
然後再根據DataFrame來進行想要的大數據分析,它提供內建的演算法與資料結構,能夠用一個指令,就可以進行二維資料的『排序,篩選,關鍵字查詢,任意區間範圍查詢,統計學計算,平均值,變異數,標準差,字串檢索,字串取代,欄位樞紐分析、小記、欄位加總,把二維資料任意方式圖形視覺化顯示』
而建立pandas的DataFrame資料結構,有兩種方式,可以用column的方式來輸入資料,也可以用row的方式來輸入資料。
所以pandas是大數據分析,非常實用的利器工具,是python資料分析的首選。
(2)Numpy:
Numpy專門用來處理矩陣,它的運算效率比列表list串列更高效。
Numpy是Python進行專業的數值計算之重要模組,因為大多數提供科學計算的包都是用numPy的陣列作為構建基礎,因此在進行高等數學計算時,numpy就是大數據分析的最重要工具了,因為高等數學運算,都是以矩陣的方式來進行運算,例如人工智慧,機器學習,深度學習,類神經網路計算等。
(3)sscipy:是基於numpy的科學計算包,包括統計、線性代數等工具。
(4)matplotlib:是最流行的用於繪製資料圖表的 Python 庫
也可以結合pandas模組來繪圖。
|
3.Pandas基礎功能: |
2.Pandas介紹
(1)Pandas:是Python的資料分析函式庫,從2009年底開放原始碼,提供簡易使用的資料結構和分析工具,讓分析人員可以快速方便的處理結構化資料。
(2)pandas:是 Python 的一個資料分析函式庫,提供如 DataFrame 等十分容易操作的資料結構,是近年做數據分析時不可或需的工具之一。
(3)Pandas:有了Pandas可以讓Python很容易做到幾乎所有Excel的功能了,像是樞紐分析表、小記、欄位加總、篩選
(4)pandas:是基於numpy的資料分析工具,能夠快速的處理結構化資料的大量資料結構和函數。
3.Pandas基礎功能:
(1)可以抓取Html網頁上的Table資料
(2)可以存取csv, excel檔案的資料
(3)資料型態為DataFrame,可以輕易轉換成index(row)或colunmn資料
(4)官方網站:https://pandas.pydata.org/,上面提供很多範例,
|
4.Pandas的資料結構 |
4.Pandas的資料結構
要使用Pandas之前,先瞭解兩個主要資料結構:
(1)Series:是一維標籤陣列(array),能夠保存任何資料類型(整數、字符串、浮點數等)。
(2)DataFrame:是一個二維標籤資料結構,可以具有不同類型的行(column),類似Excel的資料表。對於有使用過統計軟體的分析人員應該不陌生。
簡單來說:
(1)Series可以想像為一行多列(row)的資料,
(2)DataFrame是多行多列的資料,藉由選擇索引(列標籤row)和行(行標籤column)的參數來操作資料,
就像使用統計軟體透過樣本編號或變項名稱來操作資料。
|
範例11-1:建立一維陣列資料Series |
5.範例11-1:建立一維陣列資料Series
import pandas as pd
a = pd.Series(['tom','john','peter','jolin'])
print('Series a=\n', a)
#印出值 = a.values
print('印出Series a的值 =', a.values)
#印出編號 = a.index
print('印出Series a的編號 =', a.index)
#如何印出peter = a[n]
print('如何印出peter=', a[2])
#印出第2筆資料的編號index = a.index(1)
print(a.index[1])
#印出第2筆資料的值values = a.values(1)
print(a.values[1])
#自訂編號index
b = pd.Series(['tom','john','peter','jolin'],index=['b1','b2','b3','b4'])
#印出 index編號='b3'
print('b["b3"]=', b['b3'])
#印出 index編號='b3'
print('b.index[2]=', b.index[2])
print('b.values[2]=', b.values[2])
#把字典dict轉成Series
dic = {'name':'李欣欣','birthday':'1996-1-1','tel':'0912456789' }
c = pd.Series(dic)
print('c=\n', c)
print('tel=', c['tel'])
print('birthday=', c.index[1])
成果圖示: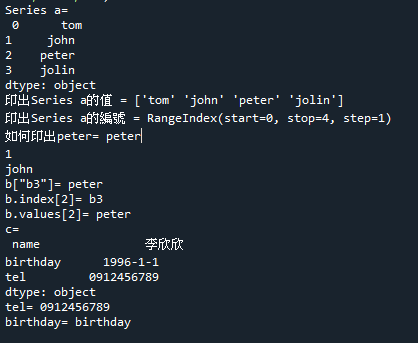
程式碼內容
|
範例11-1:用pandas建立DataFrame的三種方法 |
17.範例11-1:用pandas建立DataFrame的三種方法
重點:dataframe輸入二維資料的方法有兩種路徑:
(1)由欄位column路徑來輸入(例如方法一,方法二:'age':[22,25,20,18])
(2)由每一筆row路徑來輸入(例如方法三:data=[['tom',22],['john',25],[row3]]
範例:
import pandas as pd
#第一種方法(根據column,輸入該column的全部資料)
df1 = pd.DataFrame({
'name':['john','mary','tom','jolin'],
'age':[23,25,20,18]
})
df1.to_json('test01.json')
#第二種方法(根據column,輸入該column的全部資料)
df2 = pd.DataFrame()
df2["fruit"] = ['apple','grape']
df2["price"] = [33,50]
df2.to_json('test02.json')
#第三種方法(根據row,輸入每一筆的各種欄位資料)
#輸入row資料:輸入每一筆的各種欄位資料
data = [['john',32], ['mary', 26], ['tom', 45]]
#要指定欄位名稱columns
df3 = pd.DataFrame(data,columns=['Name','Age'])
df3.to_json('test03.json')
成果圖示:
程式碼內容
|
範例11-2:把二維字典(dict)資料,轉成DataFrame,找出某位個人資料,找出分數>80,依照字母排序 |
6.範例11-2:把二維字典(dict)資料,轉成DataFrame,找出某位個人資料,找出分數>80,依照字母排序
import pandas as pd
data = {'name':['tom','john','peter','jolin'],
'tel':['0922-556789','06-5718888','0977-888999','02-2347859'],
'score':[95,100,50,75]
}
a = pd.DataFrame(data, columns=['name','tel','score'])
print('DataFrame a=\n', a)
#透過 iloc 屬性篩選 data frame
## 選擇欄位
#印出 name column
print('用iloc顯示name欄位column=\n', a.iloc[:,0] )
print('用iloc顯示john姓名,電話,score=', a.iloc[1,0], a.iloc[1,1], a.iloc[1,2] )
print('用iloc顯示john的姓名,電話,score=\n', a.iloc[1,:])
#找出成績高於80的
s80 = a['score'] > 80
print('成績高於80分 =\n', a[s80])
#依照姓名排序
namesort = a.sort_values(by ='name')
print('依照姓名排序=\n',namesort)
#依照分數排序
scoresort = a.sort_values(by='score')
print('依照分數排序=\n', scoresort)
#統計
#計算平均值 = a.mean()
scoremean = a.mean()
print('計算平均值=', scoremean)
print('計算平均值=', scoremean['score'])
#計算分數總和 = a.sum()
scoresum = a.sum()
print('計算總和=', scoresum)
print('計算總和=', scoresum['score'])
#計算分數中位數 = a.median()
print('計算分數中位數=',a.median()['score'])
#計算分數變異數 = 方差 = std**2
print('計算分數變異數=',a.var()['score'])
#計算分數標準差= std
print('計算分數標準差= std=',a.std()['score'])
成果圖示:
程式碼內容
結果:
DataFrame a=
name tel score
0 tom 0922-556789 95
1 john 06-5718888 100
2 peter 0977-888999 50
3 jolin 02-2347859 75
用iloc顯示name欄位column=
0 tom
1 john
2 peter
3 jolin
Name: name, dtype: object
用iloc顯示john姓名,電話,score= john 06-5718888 100
用iloc顯示john的姓名,電話,score=
name john
tel 06-5718888
score 100
Name: 1, dtype: object
成績高於80分 =
name tel score
0 tom 0922-556789 95
1 john 06-5718888 100
依照姓名排序=
name tel score
1 john 06-5718888 100
3 jolin 02-2347859 75
2 peter 0977-888999 50
0 tom 0922-556789 95
依照分數排序=
name tel score
2 peter 0977-888999 50
3 jolin 02-2347859 75
0 tom 0922-556789 95
1 john 06-5718888 100
計算平均值= score 80.0
dtype: float64
計算平均值= 80.0
計算總和= name tomjohnpeterjolin
tel 0922-55678906-57188880977-88899902-2347859
score 320
dtype: object
計算總和= 320
計算分數中位數= 85.0
計算分數變異數= 516.6666666666666
計算分數標準差= std= 22.73030282830976
|
範例11-3:讀取excel檔案score.xlsx,存檔score2.xlsx |
7.範例11-3:讀取excel檔案score.xlsx,存檔score2.xlsx
import pandas as pd
df = pd.read_excel('score.xlsx','score')
print(df)
#算出數學math的平均分數 =
print('算出數學math的平均分數 = ', df.mean()['math'])
#依照數學math分數排序 =
print('依照數學分數排序 = ', df.sort_values(by='math'))
#計算數學math分數的標準差 =
print('計算數學math分數的標準差 = ', df.std()['math'])
#印出數學math分數 > 70 =
#s70 = df['math']>70
#print('計算數學math分數的標準差 =', df(s70))
#計算mike的平均分數
mikeScore = df.iloc[1,2:5]
print('計算mike的平均分數=', mikeScore.mean())
#印出全部的人名
allname = df.iloc[:,1]
print('印出全部的人名=\n', allname)
#存檔到score2.xlsx
from pandas import ExcelWriter
writer = ExcelWriter('score2.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='score')
writer.save()
成果圖示:
程式碼內容
|
範例11-4:讀取csv檔案score.csv,存檔scorecsv.csv |
8.範例11-4:讀取csv檔案score.csv,存檔scorecsv.csv
import pandas as pd
df = pd.read_csv('score.csv')
print(df)
#算出數學math的平均分數 =
print('算出數學math的平均分數 = ', df.mean()['math'])
#依照數學math分數排序 =
print('依照數學分數排序 = ', df.sort_values(by='math'))
#計算數學math分數的標準差 =
print('計算數學math分數的標準差 = ', df.std()['math'])
#印出數學math分數 > 70 =
s70 = df['math']>70
print('計算數學math分數的標準差 =', df[s70])
#計算mike的平均分數
mikeScore = df.iloc[1,2:5]
print('計算mike的平均分數=', mikeScore.mean())
#印出前面5筆
print('印出前面5筆=\n',df.head(5))
#印出全部的人名
allname = df.iloc[:,1]
print('印出全部的人名=\n', allname)
#存檔到scorecsv.csv
df.to_csv('scorecsv.csv')
成果圖示:
程式碼內容
|
範例11-5:讀取html的表格table(2020 世界大學排名) |
9.範例11-5:讀取html的表格table(2020 世界大學排名)
#url:https://www.idp.com/taiwan/ranking/ranking-world/
import pandas as pd
df = pd.read_html('https://www.idp.com/taiwan/ranking/ranking-world/')
#第一個表格放在df[0],第二個表格放在df[1]
#印出前5筆
print('印出前5筆=\n', df[0].head(5))
#印出排名第一名的學校名稱
print('印出排名第一名的學校名稱=',df[0].iloc[1,3])
#印出排名第三名的學校英文+中文名稱
print('印出排名第三名的學校名稱=\n',df[0].iloc[3,2:4])
#印出第二個表格:2021 QS世界大學排名(更新時間:2020/6)
#印出前5筆
print('印出前5筆=\n', df[1].head(5))
#印出排名第一名的學校名稱
print('印出排名第一名的學校名稱=',df[1].iloc[1,3])
成果圖示:
程式碼內容
|
範例11-6:讀取cost.csv,計算總共花費多少錢 |
10.範例11-6:讀取cost.csv,計算總共花費多少錢
import pandas as pd
#df = pd.read_csv('cost.csv',encoding='utf-8-sig')
df = pd.read_csv('cost2.csv',encoding='utf-8')
#印出:說明,支出金額,兩個欄位
print('印出:說明,支出金額,兩個欄位=\n',df[['說明','支出金額']].head(5))
print('印出:說明個欄位=\n',df['說明'].head(5))
#計算總金額
print('花費總金額=', df.sum()['支出金額'])
print('花費總金額=', df['支出金額'].sum())
#依照金額排序
print('依照金額排序=\n',df['支出金額'].sort_values().head(5))
print('依照金額排序=\n',df.sort_values(by='支出金額').head(5))
成果圖示:
程式碼內容
|
範例11-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量) |
11.範例11-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量)
import pandas as pd
df = pd.read_excel('cost.xlsx','sheet')
print(df)
#新增一個欄位=單價
df['單價'] = df['支出金額']/df['數量']
#印出表格:[說明,單價]
print('印出表格:[說明,單價]=\n',df[['說明','單價']])
成果圖示:
程式碼內容
|
範例11-8:讀取AAPL.xlsx股票檔案 |
12.範例11-8:畫圖股票線圖(讀取AAPL.xlsx股票檔案)
import pandas as pd
df = pd.read_excel('AAPL.xlsx','AAPL')
print('df=\n',df['Close'].head(8))
#找出收盤價高於227的記錄
find1 = df['Close'] > 227
print('找出收盤價高於194的記錄=\n', df[find1])
#找出Date=2018-02-01的記錄
print('找出Date=2018-02-01的記錄=\n',df[df['Date']=='2018-02-01'])
#找出Date= 2018-02-01~2018-02-08的記錄
find1 = (df['Date']>='2018-02-01') & (df['Date']<='2018-02-08')
#注意:要用() & (),否則會出現錯誤
print('找出Date= 2018-02-01~2018-02-08的記錄=\n', df[find1])
#顯示前5筆,顯示Date,Close
#兩種方法都可以
#print('顯示前5筆,顯示Date,Close=\n',df[['Date','Close']].head(5))
print('顯示前5筆,顯示Date,Close=\n',df[['Date','Close']][:5])
#依照交易量Volume排序,找出最低的前5筆
#兩種方法都可以
print('依照交易量Volume排序,找出最低的前5筆=\n',df.sort_values(by='Volume')[:5])
#print('依照交易量Volume排序,找出最低的前5筆=\n',df.sort_values(by=['Volume'])[:5])
#依照交易量Volume排序,找出最高的前5筆
print('依照交易量Volume排序,找出最低的前5筆=\n',df.sort_values(by='Volume', ascending=False)[:5])
#轉換2018/1/2 12:00:00 AM,抓出年月日
#取出前5筆的年
df['year'] = pd.DatetimeIndex(df['Date']).year
print('取出前5筆的年',df['year'][:5])
#計算2018年5月的成交量Volume的總和
df['month'] = pd.DatetimeIndex(df['Date']).month
#三種方法都可以
print('2018年5月的成交量Volume的總和=', df[(df['year']==2018) & (df['month']==4)]['Volume'].sum())
#print(df[df['month']==4]['Volume'].sum())
#print(df['Volume'][df['month']==4].sum())
成果圖示:
程式碼內容
成果:
df=
0 172.259995
1 172.229996
2 173.029999
3 175.000000
4 174.350006
5 174.330002
6 174.289993
7 175.279999
Name: Close, dtype: float64
找出收盤價高於194的記錄=
Date Open High ... Close Adj Close Volume
168 2018-08-31 226.509995 228.869995 ... 227.630005 225.869812 43340100
169 2018-09-04 228.410004 229.179993 ... 228.360001 226.594162 27390100
188 2018-10-01 227.949997 229.419998 ... 227.259995 225.502670 23600800
189 2018-10-02 227.250000 230.000000 ... 229.279999 227.507050 24788200
190 2018-10-03 230.050003 233.470001 ... 232.070007 230.275482 28654800
191 2018-10-04 230.779999 232.350006 ... 227.990005 226.227036 32042000
[6 rows x 7 columns]
找出Date=2018-02-01的記錄=
Date Open High ... Close Adj Close Volume
21 2018-02-01 167.169998 168.619995 ... 167.779999 164.592438 47230800
[1 rows x 7 columns]
找出Date= 2018-02-01~2018-02-08的記錄=
Date Open High ... Close Adj Close Volume
21 2018-02-01 167.169998 168.619995 ... 167.779999 164.592438 47230800
22 2018-02-02 166.000000 166.800003 ... 160.500000 157.450745 86593800
23 2018-02-05 159.100006 163.880005 ... 156.490005 153.516953 72738500
24 2018-02-06 154.830002 163.720001 ... 163.029999 159.932663 68243800
25 2018-02-07 163.089996 163.399994 ... 159.539993 156.508972 51608600
26 2018-02-08 160.289993 161.000000 ... 155.149994 152.202393 54390500
[6 rows x 7 columns]
顯示前5筆,顯示Date,Close=
Date Close
0 2018-01-02 172.259995
1 2018-01-03 172.229996
2 2018-01-04 173.029999
3 2018-01-05 175.000000
4 2018-01-08 174.350006
依照交易量Volume排序,找出最低的前5筆=
Date Open High ... Close Adj Close Volume
133 2018-07-13 191.080002 191.839996 ... 191.330002 189.187012 12513900
126 2018-07-03 187.789993 187.949997 ... 183.919998 181.859985 13954800
134 2018-07-16 191.520004 192.649994 ... 190.910004 188.771713 15043100
97 2018-05-22 188.380005 188.880005 ... 187.160004 185.063721 15240700
135 2018-07-17 189.750000 191.869995 ... 191.449997 189.305664 15534500
[5 rows x 7 columns]
依照交易量Volume排序,找出最低的前5筆=
Date Open High ... Close Adj Close Volume
182 2018-09-21 220.779999 221.360001 ... 217.660004 215.976913 96246700
212 2018-11-02 209.550003 213.649994 ... 207.479996 205.875610 91328700
22 2018-02-02 166.000000 166.800003 ... 160.500000 157.450745 86593800
23 2018-02-05 159.100006 163.880005 ... 156.490005 153.516953 72738500
27 2018-02-09 157.070007 157.889999 ... 156.410004 154.064056 70672600
[5 rows x 7 columns]
取出前5筆的年 0 2018
1 2018
2 2018
3 2018
4 2018
Name: year, dtype: int64
2018年5月的成交量Volume的總和= 666057900
|
範例11-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案) |
13.範例11-9:畫圖股票線圖(讀取AAPL.xlsx股票檔案)
#使用Matplotlib模組
#結合pandas 與 matplotlib = df.plot(x='..',y='..',color='red')
import pandas as pd
import matplotlib.pyplot as plt
#畫圖-line:Date vs Close (預設 kind= line)
df = pd.read_excel('AAPL.xlsx','AAPL')
#plt.plot([1,2,3,4,5,6])
df.plot(x='Date', y='Close',grid=True, color='red',label='Close')
#df.plot(x=df['Date'], y=df['Close'],grid=True, color='red')
plt.show()
#畫圖-bar:Date vs Close (kind= scatter)
#line線圖,bar柱狀圖,scatter散佈圖,bar水平柱狀圖,hist直方圖,box盒鬚圖
df.plot(x='Date', y='Close',grid=True, color='red',label='Close',kind='scatter')
plt.show()
#在同一圖fig,同一個軸ax,畫出三條線(Open,Close,High)
labels = ['Open','Close','High']
fig,ax = plt.subplots()
for name in labels:
df.plot(x='Date',y=name, ax=ax, label=name)
plt.show()
成果圖示:
成果圖示:
成果圖示:
程式碼內容
|
範例11-10:pandas讀取同一目錄的json檔案 |
14.範例11-10:pandas讀取同一目錄的json檔案
import pandas as pd
#讀取同目錄的cost.json
f1 = open('cost.json','rt',encoding='utf-8-sig')
txt = f1.read()
df = pd.read_json(txt)
print(df[['說明','支出金額']][:5])
#計算總金額
print('計算支出總金額=',df['支出金額'].sum())
#找出支出金額最高的前5個
print('找出支出金額最高的前5個=\n', df.sort_values(by='支出金額',ascending=False)[:5])
#找出支出金額超過200的記錄
cost200 = df['支出金額'] > 200
print('找出支出金額超過200的記錄=\n',df[['說明','大項目','支出金額']][cost200])
#找出大項目是『行』的記錄
itemRide = df['大項目'] == '行'
print('找出大項目是『行』的記錄=\n',df[['說明','大項目','支出金額']][itemRide])
#計算『行』的總金額
print('計算『行』的總金額=',df['支出金額'][itemRide].sum())
itemRide = df['大項目'] == '食'
print('計算『食』的總金額=',df['支出金額'][itemRide].sum())
#畫出每天的花費圖
import matplotlib.pyplot as plt
df.plot(x='時間', y='支出金額',grid=True, color='red',label='cost')
plt.show()
#找出『行,食』兩類的總金額
df.groupby('大項目')['支出金額'].sum().plot(kind='bar',stacked=True)
plt.show()
#畫出每天的花費(要先累計每天金額)
df.groupby('時間')['支出金額'].sum().plot(kind='bar')
成果圖示:
成果圖示:
成果圖示:
成果圖示:
程式碼內容
|
範例11-11:pandas讀 取URL json檔案 |
15.範例11-11:pandas讀 取URL json檔案
# Load JSON from URL
import pandas as pd
import urllib.request as request
#全國役政單位資料
url = 'https://od.moi.gov.tw/od/data/api/EA28418E-8956-4790-BAF4-C2D3988266CC?$format=json'
web = request.urlopen(url)
txt = web.read()
#print(txt)
#印出前5筆記錄
df = pd.read_json(txt)
print(df[:5])
#找出役政單位的名稱(前6筆)
print('找出役政單位的名稱(前6筆)=\n',df['unit'][:6])
#找出金門役政單位的地址,電話
find1 = df['address'].str.contains('金門')
print('找出金門役政單位的地址,電話=\n',df[['unit','address','telephon']][find1])
成果圖示:
程式碼內容
|
範例11-12:用pandas直接查詢讀取mySQL |
16.範例11-12:用pandas直接查詢讀取mySQL
(1)Pandas讀寫MySQL資料庫的三個模組:
pandas
sqlalchemy模組:可以了與不同資料庫的連線
pymysql模組:讓Python能夠操作MySQL資料庫
read_sql_query():可以讓pandas對資料庫的查詢,
to_sql():可以讓pandas對資料庫的寫入
(2)範例11-12:用pandas直接查詢讀取mySQL
#先安裝mysql(可以用Php-mysql套件)
#登入mysql,安裝資料庫:ch09.sql(帳號root,密碼root)(資料庫:ch09)(資料表:books)
#查詢ch09資料庫的books資料表,列出所有書名,與價格
import pandas as pd
try:
import MySQLdb
except:
import pymysql as MySQLdb #anaconda python 3
#連線資料庫
conn = MySQLdb.connect(host='localhost',user='root',password='root',db='ch09',charset='utf8')
#查詢stu
df = pd.read_sql_query('select * from books',con = conn)
#印出前面5筆
print(df[['書籍名稱','價格']][:5])
#找出最貴的前面5筆
print('找出最貴的前面5筆=\n', df[['書籍名稱','價格']].sort_values(by='價格',ascending=False)[:5])
#找出有『程式』的書籍
find1 = df['書籍名稱'].str.contains('程式')
print('找出有程式的書籍=\n',df[['書籍名稱','價格']][find1])
#關閉連線資料庫
conn.close()
成果圖示: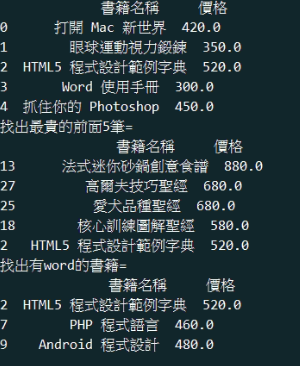
程式碼內容
|
範例11-13:用pandas把dataframe儲存成json檔案:df.to_json(filename) |
17.範例11-13:用pandas把dataframe儲存成json檔案:df.to_json(filename)
import pandas as pd
#第一種方法(根據column,輸入該column的全部資料)
df1 = pd.DataFrame({
'name':['john','mary','tom','jolin'],
'age':[23,25,20,18]
})
df1.to_json('test01.json')
#第二種方法(根據column,輸入該column的全部資料)
df2 = pd.DataFrame()
df2["fruit"] = ['apple','grape']
df2["price"] = [33,50]
df2.to_json('test02.json')
#第三種方法(根據row,輸入每一筆的各種欄位資料)
#輸入row資料:輸入每一筆的各種欄位資料
data = [['john',32], ['mary', 26], ['tom', 45]]
#要指定欄位名稱columns
df3 = pd.DataFrame(data,columns=['Name','Age'])
df3.to_json('test03.json')
成果圖示:
程式碼內容
|
| |
| |
| chp12.網絡大數據爬取與分析4(用正規式搜尋網頁的email,jpg訊息) |
|
1.資料夾模組:os |
範例12-1:建立目錄,刪除目錄,顯示檔案 |
範例12-2:把該目錄下方的資料夾以串列顯示 |
範例12-3:到某個目錄查詢指定檔案名稱 |
|
範例12-4:顯示目前目錄下的完整路徑(目錄+檔案名稱) |
範例12-5:更有效率的顯示目前目錄下的完整路徑 |
3.存取文字檔 |
範例12-6:讀取exp12-1.py的所有內容 |
|
範例12-7:使用迴圈,一行一行讀取exp12-1.py的所有內容 |
範例12-8:讀取目前目錄下所有檔案的文字內容 |
範例12-9:存入exp12-10.py,印出新年快樂 |
範例12-11:存入exp12-10.py,印出新年快樂,但是用try...except |
|
範例12-12:把exp112-10.py,複製到copy.py檔案 |
範例12-13:4.存取csv:讀入一個已經存在的csv檔案 |
範例12-14:把第一行的標題結合資料數據,形成字典格式dict |
範例12-15:新增一個新檔案,加入一筆標題,加入一筆記錄 |
|
範例12-16:開啟一個舊檔,加入一筆標題,加入一筆記錄 |
範例12-17:已知字典變數數據,要寫入檔案 |
5.存取二進位檔案:範例12-18:把對聯文字,存入二進位檔案 |
|
1.資料夾模組:os |
1.功能:刪除資料夾(檔案),儲存資料夾(檔案),修改資料夾(檔案),查詢資料夾(檔案)
2.模組:os
(1).常用指令:
import os
#☎到指定目錄:os.chdir(目錄)
#☎回傳目前目錄的所有資料夾與檔案:os.listdir(目錄)
#☎判別目前是資料夾嗎?:os.path.isdir(目錄)
#☎判別目前是檔案嗎?:os.path.isfile(目錄)
#☎回傳目前檔案大小:os.path.getsize(目錄)
#☎回傳目前資料夾名稱:os.getcwd()
#☎建立資料夾名稱:os.mkdir(目錄,dir_fd=None)
dir_fd=None 表示是絕對路徑
#☎刪除資料夾名稱:os.rmdir(目錄,dir_fd=None)
#☎刪除檔案名稱:os.remove(目錄,dir_fd=None)
#☎顯示目錄與檔案名稱:os.path.join(目錄名稱,檔案名稱)
|
範例12-1:建立目錄,刪除目錄,顯示檔案 |
(2).範例12-1.py
import os
#顯示目前目錄
a1 = os.getcwd()
print('目前目錄=',a1)
#到c:\\目錄
os.chdir('c:\\')
a1 = os.getcwd()
print('目前目錄=',a1)
#顯示所有目錄與檔案
a2= os.listdir(a1)
print('所有目錄與檔案=',a2)
#只顯示目錄
for i in a2:
if os.path.isdir(i)==True:
print('這個是目錄=',i)
elif os.path.isfile(i)==True:
print('這個是檔案=',i)
print('檔案大小=',os.path.getsize(i))
#建立一個目錄
os.mkdir('test')
#刪除一個目錄
os.rmdir("test")
程式碼內容
|
範例12-2:把該目錄下方的資料夾以串列顯示 |
(3).範例12-2.py
目的:類似上個範例,用一行的for迴圈,把該目錄下方的資料夾以串列顯示
import os
#到c:\\目錄
os.chdir('c:\\')
a1 = os.getcwd()
print('目前目錄=',a1)
#顯示所有目錄與檔案
a2= os.listdir(a1)
#只顯示目錄
print('這個是目錄=',[i for i in a2 if os.path.isdir(i)==True])
print('這個是檔案=',[i for i in a2 if os.path.isfile(i)==True])
程式碼內容
|
範例12-3:到某個目錄查詢指定檔案名稱 |
2.模組:glob
(1).常用指令:
import glob
#☎到某個目錄查詢指定檔案名稱:os.glob.glob(指定檔名)
(4).範例12-3.py
目的:到某個目錄查詢指定檔案名稱(*.jpg):os.glob.glob(指定檔名)
import os, glob
os.chdir('c:\\')
folder1 = os.getcwd()
file1 = '*.jpg'
a1 = glob.glob(file1)
print(a1)
程式碼內容
|
範例12-4:顯示目前目錄下的完整路徑(目錄+檔案名稱) |
(5).範例12-4.py
目的:顯示目前目錄下的完整路徑(目錄+檔案名稱)
#☎顯示目錄與檔案名稱:os.path.join(目錄名稱,檔案名稱)
#☎注意:如果用手動連接,會出現錯誤:print(d1+'\'+i)
import os
a1 = os.listdir()
#print(a1)
#目前目錄名稱
d1 = os.getcwd()
#每個檔案都顯示完整路徑
for i in a1:
#注意用手動連接,會出現錯誤:print(d1+'\'+i)
print(os.path.join(d1,i))
程式碼內容
|
範例12-5:更有效率的顯示目前目錄下的完整路徑 |
(6).範例12-5.py
目的:更有效率的顯示目前目錄下的完整路徑(目錄+檔案名稱):os.walk
(path)
#☎快速的完整顯示目錄與檔案名稱:for root,dirs,files in os.walk(path)
#☎顯示目錄與檔案名稱:os.path.join(目錄名稱,檔案名稱)
#☎注意:如果用手動連接,會出現錯誤:print(d1+'\'+i)
import os
#目前目錄名稱
d1 = os.getcwd()
#快速吸收每個檔案都顯示完整路徑
for root,dirs,files in os.walk(d1):
for file in files:
#注意用手動連接,會出現錯誤:print(d1+'\'+i)
print(os.path.join(root, file))
程式碼內容
|
3.存取文字檔 |
3.存取文字檔
(1).常用指令
#☎開啟檔案:a1 = open(檔名,模式mode,文字子編碼)
a1 = open('exp11_01.py','rt',encoding='utf-8')
#☎模式mode種類:
r:只能讀取
w:可以寫入(會先刪除原先的檔案)
x:可以寫入(但是檔案不能已經存在,避免覆蓋)
a:可以寫入(把寫入資料,寫在檔案最後加入)
t:純文子檔
b:二進位檔
+:可以讀取,可以寫入
#☎讀取全部檔案:a1.read()
#☎讀取檔案裡面的一行:a1.readline()
#☎讀取檔案裡面的每一行,並把它們變成串列:a1.readlines()
#☎把字串寫入檔案:a1.write(字串)
#☎把字串寫入檔案:print(字串,file=檔案物件)
檔案物件 = open('exp11_01.py','rt',encoding='utf-8')
|
範例12-6:讀取exp12-1.py的所有內容 |
(1).範例12-6.py
目的:讀取exp12-1.py的所有內容
f1 = 'exp12-1.py'
a1 = open(f1,'rt',encoding='utf-8')
print(a1.read())
a1.close()
程式碼內容
|
範例12-7:使用迴圈,一行一行讀取exp12-1.py的所有內容 |
(2).範例12-7.py
目的:使用迴圈,一行一行讀取exp12-1.py的所有內容
f1 = 'exp11_01.py'
a1 = open(f1,'rt',encoding='utf-8')
for i in a1:
print(i)
a1.close()
程式碼內容
|
範例12-8:讀取目前目錄下所有檔案的文字內容 |
(3).範例12-8.py
目的:讀取目前目錄下所有檔案的文字內容
import os
a1 = os.listdir()
for i in a1:
if os.path.isfile(i)==True:
print('檔案名稱=',i)
f1 = open(i,'rt',encoding='utf-8')
print(f1.read())
f1.close()
程式碼內容
|
範例12-9:存入exp12-10.py,印出新年快樂 |
(4).範例12-9.py
目的:寫一個程式,存入exp12-10.py,印出『新年快樂』
f1 = 'exp12-10.py'
txt ="""
s1 = input('輸入您的姓名=')
print(s1,'新年快樂')
"""
#將程式寫入檔案內
a1 = open(f1,'wt',encoding='utf-8')
a1.write(txt)
a1.close()
程式碼內容
|
範例12-11:存入exp12-10.py,印出新年快樂,但是用try...except |
(5).範例12-11.py
目的:寫一個程式,存入exp12-10.py,印出『新年快樂』,但是用try...except
測試寫入程式是否發生問題?
f1 = 'exp12-10.py'
txt ="""
s1 = input('輸入您的姓名=')
print(s1,'新年快樂')
"""
#將程式寫入檔案內
try:
a1 = open(f1,'twt',encoding='utf-8')
a1.write(txt)
a1.close()
except:
print('無法寫入檔案')
程式碼內容
|
範例12-12:把exp112-10.py,複製到copy.py檔案 |
6).範例12-12.py
目的:複製檔案,把exp12-10.py,複製到copy.py檔案
f1 = 'exp12-10.py'
f2 = 'copy.py'
a1 = open(f1,'rt',encoding='utf-8')
a2 = open(f2,'wt',encoding='utf-8')
txt = a1.read()
a2.write(txt)
a1.close()
a2.close()
程式碼內容
|
4.存取csv:範例12-13:讀入一個已經存在的csv檔案 |
4.存取csv檔
(1).範例12-13.py
讀入一個已經存在的csv檔案
(下載檔案: customer.csv到exp12-11.py同一個目錄)
#讀入一個已經存在的csv檔案: customer.csv
#方法1:缺點,無法指定印出:第二筆記錄的公司名稱(因為都是純文字,不是陣列或串列list)
a1 = open('customer.csv','rt',encoding='utf-8')
txt = a1.read()
print(txt)
a1.close()
#方法2:import csv模組,然後用with open('customer.csv','rt',encoding='utf-8')as fin:
import csv
with open('customer.csv','rt',encoding='utf-8')as fin:
rows = csv.reader(fin,delimiter=',')
#指定印出:第二筆記錄的公司名稱
listrow = list(rows)
print(listrow[1][1])
for i in listrow:
print(i)
結果:包括第一行的標題
[['客戶編號', '公司名稱', '連絡人', '連絡人職稱'], ['ALFKI', '三川實業有限公司', '陳小姐', '業務'], ['ANATR', '東南實業', '黃小姐', '董事長'], ['ANTON', '坦森行貿易', '胡先
生', '董事長']]
若是希望把第一行當作是標題,而不是資料列的做法
而且希望顯示字典(dictionary),顯示把{標題欄位1:數據},{標題欄位2:數據}....
程式碼內容
|
範例12-14:把第一行的標題結合資料數據,形成字典格式dict |
(2).範例12-14.py
#目的:把第一行的標題結合資料數據,形成字典格式dict
#☎重點:rows = csv.DictReader(fin,delimiter=',')
不是rows = csv.Reader(fin,delimiter=',')
#把customer.csv第一行的標題結合資料數據,形成字典格式dict
import csv
with open('customer.csv','r',encoding='utf-8')as fin:
rows = csv.DictReader(fin,delimiter=',')
for row in rows:
print(row)
print(row['公司名稱'])
結果:
OrderedDict([('\ufeff客戶編號', 'ALFKI'), ('公司名稱', '三川實業有限公司'), ('連絡人', '陳小姐'), ('連絡人職稱', '業務')])
三川實業有限公司
OrderedDict([('\ufeff客戶編號', 'ANATR'), ('公司名稱', '東南實業'), ('連絡人', '黃小姐'), ('連絡人職稱', '董事長')])
東南實業
OrderedDict([('\ufeff客戶編號', 'ANTON'), ('公司名稱', '坦森行貿易'), ('連絡人', '胡先生'), ('連絡人職稱', '董事長')])
坦森行貿易
程式碼內容
|
範例12-15:新增一個新檔案,加入一筆標題,加入一筆記錄 |
(3).範例12-15.py
#目的:新增一個新檔案,加入一筆標題,加入一筆記錄
#☎重點:wt = csv.writer(fout,delimiter=',')
wt.writerow(['AL001','全聯有限公司','張三','司機'])
#新增一個新檔案test.csv,加入一筆標題,加入一筆記錄:['AL001','全聯有限公司','張三','司機']
import csv
with open('test1.csv','w',encoding='utf-8',newline='')as fout:
#若不設定換行字元 = newline='',則會造成間隔一行(多一行空白行)
wt = csv.writer(fout,delimiter=',')
wt.writerow(['客戶編號', '公司名稱', '連絡人', '連絡人職稱'])
wt.writerow(['AL001','全聯有限公司','張三','司機'])
print('已經成功加入test.csv檔案')
程式碼內容
|
範例12-16:開啟一個舊檔,加入一筆標題,加入一筆記錄 |
(4).範例12-16.py
#目的:開啟一個舊檔test1.csv,加入一筆標題,加入一筆記錄
#☎重點:with open('test1.csv','a',newline='')as fout:
#☎其中的'a' = 寫入,若是原本的檔案已經存在,保留原本資料,在最後新增
import csv
with open('test1.csv','a',encoding='utf-8',newline='')as fout:
wt = csv.writer(fout,delimiter=',')
wt.writerow(['客戶編號', '公司名稱', '連絡人', '連絡人職稱'])
wt.writerow(['AL005','7-11有限公司','李四','經理'])
print('已經成功加入test.csv檔案')
程式碼內容
|
範例12-17:已知字典變數數據,要寫入檔案 |
(5).範例12-17.py
#目的:已知字典變數數據,要寫入檔案(以字典方式寫入,但是卻顯示第一行標題,第二行資料數據)
#☎重點:wt = csv.DictWriter(fout,atitle)
wt.writeheader()
wt.writerow(adata)
import csv
atitle = ['客戶編號', '公司名稱', '連絡人', '連絡人職稱']
with open('test2.csv','w',newline='')as fout:
wt = csv.DictWriter(fout,atitle)
wt.writeheader()
wt.writerow({'客戶編號':'AL005', '公司名稱':'7-11有限公司', '連絡人':'李四', '連絡人職稱':'主任'})
wt.writerow({'客戶編號':'AL006', '公司名稱':'麥當勞公司', '連絡人':'王五', '連絡人職稱':'經理'})
結果:
客戶編號,公司名稱,連絡人,連絡人職稱
AL005,7-11有限公司,李四,主任
AL006,麥當勞公司,王五,經理
程式碼內容
|
5.存取二進位檔案:範例12-18:把對聯文字,存入二進位檔案 |
5.存取二進位檔案
(1).公式:
(2).範例12-18.py
把對聯文字,存入二進位檔案
程式碼內容
|
| |
| |
| chp13.網絡大數據爬取與分析5(Selenium自動化網頁操作) |
| 1.日期時間函式庫 |
範例13-1:模組datetime(顯示日期,時間 |
範例13-2:模組date(只能顯示日期) |
範例13-3:模組timedelta(間隔日期,時間) |
範例13-4:傳回自1970年1月1日凌晨0:0:0開始至今的秒數 |
| 範例13-5:計算呼叫某個函式所需要的時間 |
2.可以迭代(iterate)的函式庫= itertools,函式enumerate,zip,filter,map,reduce |
範例13-6:顯示陣列 |
範例13-7:zip(a,b)是結合兩個可迭代物 |
範例13-8:模組itertools:給定起始值,遞增值,就可以產生無窮數列 |
| 範例13-9:filter(過濾函數def或lambda,資料列) |
範例13-10:過濾模組map |
範例13-11:操作每個元素模組reduce |
範例13-12:套件collections-模組OderedDict:可將兩個串列,合併形成成一個字典dict |
範例13-13:模組deque:操作可迭代資料列,新增,刪除,反轉 |
| 例13-14:模組dCounter:可計算可迭代資料列相同元素的次 |
|
|
|
|
1.日期時間函式庫 |
1.日期時間函式庫
(1).時間函式庫有三個:datetime,date,time模組
模組datetime:可以處理日期與時間函式庫,可以傳回目前的日期,時間
模組date:可以傳回目前的日期
|
範例13-1:模組datetime(顯示日期,時間 |
(2).範例13-1:模組datetime(顯示日期,時間)
公式:
from datetime import datetime
a1 = datetime.today()
y1 = a1.year
範例13-1.py
from datetime import datetime
a1 = datetime.today()
print('現在日期時間 =',a1)
y1 = a1.year
m1 = a1.month
d1 = a1.day
h1 = a1.hour
min1 = a1.minute
s1 = a1.second
print(y1,'年',m1,'月',d1,'日',h1,'時',min1,'分',s1,'秒')
程式碼內容
|
範例13-2:模組date(只能顯示日期) |
(3).模組date(只能顯示日期)
公式:
from datetime import date
a1 = datetime.today()
y1 = a1.year
範例13-2.py
from datetime import date
a1 = date.today()
print('現在日期=',a1)
y1 = a1.year
m1 = a1.month
d1 = a1.day
print(y1,'年',m1,'月',d1,'日')
程式碼內容
|
範例13-3:模組timedelta(間隔日期,時間) |
(4).模組timedelta(間隔日期,時間)
公式:
from datetime import datetime,timedelta
a1 = datetime.today()
delta2 = timedelta(days=5)
a2 = a1 + delta2
範例13-3.py
from datetime import datetime,timedelta
a1 = datetime.today()
print('今天是=',a1)
delta2 = timedelta(days=5)
a2 = a1 + delta2
print('5天後=',a2)
delta3 = timedelta(hours=3)
a3 = a1 +delta3
print('3小時後=',a3)
程式碼內容
|
範例13-4:傳回自1970年1月1日凌晨0:0:0開始至今的秒數 |
(5).模組time(時間)
公式:
import time
t1 = time.time()
功能:傳回自1970年1月1日凌晨0:0:0開始至今的秒數
範例13-4.py
import time
t1 = time.time()
print('1970年至今的秒數=',t1)
程式碼內容
|
範例13-5:計算呼叫某個函式所需要的時間 |
範例13-5.py
目的:計算呼叫某個函式所需要的時間
import time
def func():
[i for i in range(9999999)]
t1 = time.time()
func()
t2 = time.time()
print('函式執行時間 = ', t2-t1)
程式碼內容
|
2.可以迭代(iterate)的函式庫= itertools,函式enumerate,zip,filter,map,reduce |
2.可以迭代(iterate)的函式庫
(1).種類:迭代模組或函式 = itertools,函式enumerate,zip,filter,map,reduce
(2).enumerate(a)是列舉函數(編號i,元素x)
☎功能:可以把每一個元素加上編號
☎配合list:list(enumerate(a)))
☎顯示一維串列:print((x for i,x in enumerate(a)))
☎顯示二維串列:print((x[0]+'姓名是'+x[1] for i,x in enumerate(a)))
|
範例13-6:顯示陣列 |
☎範例13-6.py
a=['tom','mike','peter','yellow']
#for顯示陣列
for i in a:
print(i)
#enumrate顯示陣列 enumerate
print([x for i,x in enumerate(a)])
#enumrate顯示陣列 enumerate
print(list(enumerate(a)))
b = (('tom','湯姆'),('mike','麥克'),('peter','彼德'))
#for顯示陣列
for i in b:
print(i)
for i in b:
print(i[0],',',i[1])
#enumrate顯示二維陣列 enumerate
print([x[0] for i,x in enumerate(b)])
程式碼內容
|
範例13-7:zip(a,b)是結合兩個可迭代物 |
(3).zip(a,b)是結合兩個可迭代物件
☎功能:結合兩個可迭代物件,對應結合成一個新的物件
☎必須配合list:list(zip(a, b)))
☎範例13-7.py
a = ['tom','mike','peter','yellow']
b = [95,85,66,75]
#結合兩個可迭代物件
c = zip(a, b)
print(list(c))
程式碼內容
|
範例13-8:模組itertools:給定起始值,遞增值,就可以產生無窮數列 |
(4).模組itertools
功能:給定起始值,遞增值,就可以產生無窮數列
☎範例13-8.py
import itertools
# itertools.count(起始值,遞增值)
nums = itertools.count(1,2)
#print(list(nums))
#結果: 1 3 5 7 9....
# itertools.cycle(資料列)
nums = [1,2,3]
newnums = itertools.cycle(nums)
#print(list(newnums))
#結果: 1 2 3 1 2 3 1 2 3....
# itertools.repeat(資料列,次數)
nums = [1,2,3]
newnums = itertools.repeat(nums,2)
#print(list(newnums))
#結果: [[1,2,3],[1,2,3],]....
# itertools.accumulate(資料列)
nums = [1,2,3,4,5,6]
newnums = itertools.accumulate(nums)
print(list(newnums))
#結果: [1, 3, 6, 10, 15, 21]
# itertools.chain(資料列)
newnums = itertools.chain('how','are you')
print(list(newnums))
#結果: ['h', 'o', 'w', 'a', 'r', 'e', ' ', 'y', 'o', 'u']
# itertools.combinations(資料列',取n個)
newnums = itertools.combinations('ABC',2)
print(list(newnums))
#結果: [('A', 'B'), ('A', 'C'), ('B', 'C')]
# itertools.permutations(資料列',取n個)
newnums = itertools.permutations('ABC',2)
print(list(newnums))
#結果: [('A', 'B'), ('A', 'C'), ('B', 'C')]
程式碼內容
|
範例13-9:filter(過濾函數def或lambda,資料列) |
(5).過濾模組filter
公式:filter(過濾函數def或lambda,資料列)
功能:
☎範例13-9.py
#顯示偶數
a = [1,2,3,4,5,6,7,8,9,10]
b = filter(lambda x:x%2==0, a)
print(list(b))
#顯示有'o'的元素
a = ['tom','girl','man','took']
b = filter(lambda x:x.find('o')>=0, a)
print(list(b))
程式碼內容
|
範例13-10:過濾模組map |
(6).過濾模組map
公式:map(過濾函數def或lambda,資料列)
功能:
☎範例13-10.py
#顯示偶數
def getnum(x):
if x%2 ==0:
return x
a = [1,2,3,4,5,6,7,8,9,10]
b = filter(getnum, a)
print(list(b))
#顯示有'o'的元素
def getstr(x):
if x.find('o')>=0:
return x
a = ['tom','girl','man','took']
b = filter(getstr, a)
print(list(b))
程式碼內容
|
範例13-11:操作每個元素模組reduce |
(7).操作每個元素模組reduce
公式:reduce(過濾函數def或lambda,資料列)
功能:逐一操作每個元素
☎範例13-11.py
from functools import reduce
#計算總和
def getsum(x,y):
return x+y
a = [1,2,3,4,5]
b = reduce(getsum, a)
print(b)
#連接所有的元素
a = ['t','r','i','g','e','r']
b = reduce(lambda x,y:x+y, a)
print(b)
程式碼內容
|
範例13-12:套件collections-模組OderedDict:可將兩個串列,合併形成成一個字典dict |
3.套件collections
import collections
(1).模組OderedDict
功能:將兩個串列,合併形成成一個字典dict
☎比較:合併串列建立字典的兩種方法
☎範例13-12.py
import collections
a1 = ['姓名','住址','性別','電話']
b1 = ['張三','台南市忠孝東路15好','男','0912751477']
#合併串列建立字典,方法一
d1 = collections.OrderedDict(zip(a1,b1))
print(d1)
print('姓名=',d1['姓名'])
#合併串列建立字典,方法二:zip()合併兩個串列,轉成dict()
c1 = zip(a1,b1)
d1 = dict(c1)
print(d1)
print('姓名=',d1['姓名'],'電話=',d1['電話'])
程式碼內容
|
範例13-13:模組deque:操作可迭代資料列,新增,刪除,反轉 |
(2).模組deque
功能:操作可迭代資料列,新增,刪除,反轉
☎範例13-13.py
from collections import deque
a1 = [1,2,3,4,5]
#建立deque物件
d1 = deque(a1)
#反轉資料列
d1.reverse()
print('反轉=',d1)
#新增到資料列右邊 append(元素)
d1.append('R')
print('右邊新增=',d1)
#新增到資料列左邊 appendleft(元素)
d1.appendleft('L')
print('左邊新增=',d1)
#刪除資料列右邊一個 pop()
d1.pop()
print('刪除右邊1個=',d1)
#刪除資料列左邊一個 pop()
d1.popleft()
print('刪除左邊1個=',d1)
#刪除某個元素 remove(元素)
d1.remove(3)
print('刪除某個元素3=',d1)
d1.append(2)
#計算某個元素2出現的次數 count(元素)
n1 = d1.count(2)
print('計算某個元素2出現的次數=',n1)
程式碼內容
|
例13-14:模組dCounter:可計算可迭代資料列相同元素的次 |
(3).模組dCounter
功能:計算可迭代資料列相同元素的次數
☎範例13-14.py
from collections import Counter
s = 'today is a good day'
a1 = list(s)
print(a1)
#建立counter物件(字典)
c1 = Counter(a1)
print(c1)
#顯示所有『鍵』
print(c1.keys())
#顯示所有『值』
print(c1.values())
#顯示所有『元素』
print(list(c1.elements()))
#顯示所有『鍵值(tuple)』
print(c1.most_common())
程式碼內容
|
|
|
| |
| |
| chp14.數學函數庫math,sympy,微分,積分,偏微分 |
|
1.存取xml:模組:xml.etree.ElementTree |
範例14-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料 |
範例14-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信 |
範例14-3:修改並存入xml |
|
線上XML/JSON互相轉換工具 |
2.讀取網頁:request(url) |
範例14-4:讀取網頁:web = request.urlopen(網址) |
3.存取 json(模組:json) |
|
範例14-5:轉成json:jumps。轉成dict:loads |
範例14-6:讀取網絡上的json檔案 |
範例14-7:讀取電腦上的json檔案 |
3.網路爬蟲BeautifulSoup |
|
範例14-8:讀取網頁標題 |
範例14-9:讀取網址的網頁 |
|
|
1.存取xml:模組:xml.etree.ElementTree |
1.python的數學函數庫:math,sympy,cmath
(1)math:
功能:乘方、開方、對數,冪函數與對數函數,三角函數,角度轉換,雙曲函數,特殊函數,常量,cos,sin,e,log,tan,pow
Math模組
sqrt(x) 傳回 x 的平方根
pow(x, y) 傳回 x 的 y 次方
exp(x) 傳回 x 的自然指數
expm1(x) 傳回 x 的自然指數-1 (在 x 接近 0 時仍有精確值)
log(x [, b]) 傳回 x 以 b 為基底的對數 (預設 b=e 自然對數)
log10(x) 傳回 x 的常用對數 (以 10 為底數)
degrees(x) 傳回弧度 x 的角度 (degree)
radians(x) 傳回角度 x 的弧度 (radian)
dist(p, q) 傳回兩個座標點 p, q 的歐幾里得距離 (畢式定理斜邊)
hypot(coor) 傳回座標序列 coor 的歐幾里得距離
sin(x) 傳回 x 的正弦值
cos(x) 傳回 x 的餘弦值
tan(x) 傳回 x 的正切值
asin(x) 傳回 x 的反正弦值 (sin 的反函數)
acos(x) 傳回 x 的反餘弦值 (cos 的反函數)
atan(x) 傳回 x 的反正切值 (tan 的反函數)
atan2(y, x) 傳回 y/x 的反正切值 (tan 的反函數)=atan(y/x)
sinh(x) 傳回 x 的雙曲正弦值
cosh(x) 傳回 x 的雙曲餘弦值
tanh(x) 傳回 x 的雙曲正切值
asinh(x) 傳回 x 的反雙曲正弦值=log(x+sqrt(x**2+1))
acosh(x) 傳回 x 的反雙曲餘弦值=log(x+sqrt(x**2-1))
atanh(x) 傳回 x 的反雙曲正切值=1/2*log((1+x)/(1-x))
fabs(x) 傳回 x 的絕對值 (或稱模數, modulus)
floor(x) 傳回浮點數 x 的向下取整數 (即小於 x 之最大整數)
ceil(x) 傳回浮點數 x 的向上取整數 (即大於 x 之最小整數)
trunc(x) 傳回浮點數 x 的整數部分 (捨去小數)
modf(x) 傳回浮點數 x 的 (小數, 整數) 元組
factorial(x) 傳回 x 階乘 (x!, x=整數)
gcd(x, y) 傳回整數 x, y 之最大公因數
comb(n, k) 傳回 n 取 k 的組合數 (不依序不重複)
perm(n, k) 傳回 n 取 k 的組合數 (依序不重複)
modf(x, y) 傳回 x/y 之精確餘數 (浮點數 float)
fsum(iter) 傳回可迭代數值 iter 之精確總和
isclose(x, y) 若 a, b 值很接近傳回 True (預設差小於 1e-9)
isfinite(x) 若 x 不是 nan 或 inf 傳回 True, 否則 False
isnan(x) 若 x 為 nan 傳回 True, 否則 False
isinf(x) 若 x 為 inf 傳回 True, 否則 False
(2)sympy:
Sympy是一個數學符號庫(sym代表了symbol,符號),包括了積分,微分方程,三角等各種數學運算方法,是工科最基本的數學函數庫,用起來媲美matlab,而且其精度比math函數庫精確。
功能:
simplify運算式化簡,solve方程自動求解
limit求極限,diff求導
dsolve()計算微分方程
intergrate積分計算:1.定積分,2.不定積分,3.雙重定積分,4. 雙重不定積分
(3)cmath:專門用來處理複數運算。
|
範例14-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料 |
☎方法1:範例14-1.py
下載person.xml
#目的讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信的個人所有資料
程式碼:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
root = tree.getroot()
print('根目錄的標籤名稱',root.tag)
# root.tag 讀取 tag 名
# root.attrib 讀取 attributes
# root[0][1].rank 讀取文本值
#輸出根節點元素的tag名:person
print(root.tag)
#輸出根節點元素的attributes(空值):{}
print(root.attrib)
#輸出第一個的三個子元素的值:
print(root[0][0].text)
print(root[0][1].text)
print(root[0][2].text)
#查找所有子孫元素:tag標籤 = name
for elem in root.iter('name'):
print(elem.tag, elem.attrib, elem.text)
#比較find() 和 findall()
#查找第一個子元素:find()
print(list(root.find('student')))
#查找所有子元素:findall()
print(list(root.findall('student')))
#查找所有子元素:findall()
#tree.findall('student/*') //查詢孫子節點元素
for elem in root.findall('student/*'):
print(elem.tag, elem.text)
#tree.findall('.//name') //查詢任意層次元素
for elem in root.findall('.//tel'):
print(elem.tag, elem.text)
#查詢 包含name屬性的student
#查詢tree.findall('student[@name]')
for elem in root.findall('student[@name]'):
print(elem.tag, elem[1].text)
#查詢 name屬性為卓水信的student
#tree.findall('student[name="卓水信"]')
for elem in root.findall('student[name="卓水信"]'):
print('id=',elem[0].text)
print('name=',elem[1].text)
print('tel=',elem[2].text)
#顯示 第一個student
for elem in tree.findall('student[1]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示 第二個student
for elem in tree.findall('student[2]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示最後一個student
#tree.findall('student[last()]')
for elem in tree.findall('student[last()]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示倒數第二個country
#tree.findall('country[last()-1]')
for elem in tree.findall('student[last()-1]'):
print(elem[0].text,elem[1].text,elem[2].text)
#顯示第1階層所有階層的標籤名稱,屬性
print('顯示第1階層所有階層的標籤名稱,屬性:')
for child in root:
print(child.tag, child.attrib, child.text)
#顯示第2階層的標籤名稱,文字值
print('顯示第2階層的標籤名稱,文字值:')
for i,child1 in enumerate(root):
print(child1.tag,i)
for child2 in child1:
print(child2.tag, '=', child2.text)
#查詢某個tag標籤名稱
print('查詢某個tag標籤名稱:')
for elem in root.iterfind('student/mail'):
print(elem.tag,'=',elem.text)
#查詢某個tag標籤tel的所有文字
print('查詢某個tag標籤的所有文字:')
for elem in root:
print(elem.find('tel').text)
#查詢卓水信是否存在
print('查詢卓水信是否存在:方法1')
#方法1
for elem in root.findall('student[name="卓水信"]'):
if elem[1].text=='卓水信':
print(elem[1].text,'存在')
print('查詢卓水信是否存在:方法2')
#方法2
for elem in tree.iter():
if elem.text=='卓水信':
print(elem.tag,'=',elem.text,'存在')
#查詢卓水信的個人所有資料
#方法1
print('\n查詢卓水信的個人所有資料:方法1')
for elem in root.findall('student[name="卓水信"]'):
print(elem[0].text, elem[1].text,elem[2].text)
#方法2
print('\n查詢卓水信的個人所有資料:方法2')
for elem1 in tree.iter():
for elem2 in elem1:
if elem2.text=='卓水信':
print('name =',elem1.find('name').text)
print('tel =',elem1.find('tel').text)
print('mail =',elem1.find('mail').text)
程式碼內容
|
範例14-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信 |
☎方法2範例14-2.py
#目的讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信的個人所有資料
程式碼:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
#顯示所有的tag name = tree.iter()
print('顯示所有的tag name')
for elem in tree.iter():
print(elem.tag, elem.attrib,elem.text)
#尋找某個tag name的資料 = tree.iterfind('tag name')
print('尋找某個tag name')
for elem in tree.iterfind('student/mail'):
print(elem.tag,'=',elem.text)
#尋找某個tag text的資料 = tree.iterfind('tag name')
print('尋找某個tag attribute')
for elem in tree.iterfind('student[@hash="1cdf045c1"]'):
print(elem.tag,'=',elem.attrib)
print('\n尋找全部的mail')
for elem in tree.iterfind('student/mail'):
print(elem.tag,'=',elem.text)
#查詢卓水信的個人所有資料
print('\n查詢卓水信的個人所有資料:')
for elem1 in tree.iter():
for elem2 in elem1:
if elem2.text=='卓水信':
print('name =',elem1.find('name').text)
print('tel =',elem1.find('tel').text)
print('mail =',elem1.find('mail').text)
程式碼內容
|
範例14-3:修改並存入xml |
(3).修改並存入xml文檔
☎範例14-3.py
#修改卓水信的個人id_no = 999999
程式碼:
import xml.etree.ElementTree as xml
tree = xml.ElementTree(file='person.xml')
root = tree.getroot()
#修改
print('\n修改卓水信的個人資料:')
for elem in root.findall('student[name="卓水信"]'):
elem[0].text = '999999'
#存檔xml
tree.write('person2.xml') #儲存
#顯示
for elem1 in root:
for elem2 in elem1:
print(elem2.tag,elem2.attrib, elem2.text)
程式碼內容
|
線上XML/JSON互相轉換工具 |
線上XML/JSON互相轉換工具:
http://tools.itread01.com/code/xmljson
線上格式化XML/線上壓縮XML:
http://tools.itread01.com/code/xmlformat
XML線上壓縮/格式化工具:
http://tools.itread01.com/code/xml_format_compress
XML程式碼線上格式化美化工具:
http://tools.itread01.com/code/xmlcodeformat
更多關於Python相關內容感興趣的讀者可檢視:
《Python操作xml資料技巧總結》、《Python資料結構與演算法教程》、《Python Socket程式設計技巧總結》、《Python函式使用技巧總結》、《Python字串操作技巧彙總》、《Python入門與進階經典教程》及《Python檔案與目錄操作技巧彙總》
https://www.itread01.com/article/1535600015.html
|
2.讀取網頁:request(url) |
2.讀取網頁:request(url)
☎模組:import urllib.request as request
☎讀取網頁:web = request.urlopen(網址)
☎讀取網頁內容並解碼 = web.read().decode()
|
範例14-4:讀取網頁:web = request.urlopen(網址) |
☎範例14-4.py
程式碼:
import json
import urllib.request as request
url = 'http://web.tsu.edu.tw/bin/home.php'
web = request.urlopen(url)
print('網址=',web.geturl())
print('狀態(200表示OK)=',web.status)
print('取得網頁標頭=',web.getheaders())
print('取得網頁標頭=',web.getheaders())
txt = web.read()
print('取得網頁內容(byte格式)=',txt)
print('取得網頁內容(解碼byte格式)=',txt.decode())
程式碼內容
|
3.存取 json(模組:json) |
3.存取 json
(1).模組:json
import json
(2).把字典dict轉換成json
公式:json = json.dumps(字典)
(3).把json轉換成字典
公式:字典 = json.loads(json)
|
範例14-5:轉成json:jumps。轉成dict:loads |
(4).☎範例14-5.py
程式碼:
import json
#把字典dict轉成json:jumps
a1 = {'tom':'0912456789','mike':'0965258741','peter':'0965789365'}
j1 = json.dumps(a1)
print(j1)
#把串列list轉成json:jumps
a2 = [['tom','湯姆'],['mike','麥克'],['peter','彼德']]
j2 = json.dumps(dict(a2))
print(j1)
#把json轉成字典dict:loads
#轉成上面的json = j1
a1 = json.loads(j1)
print('tom的電話 = ',a1['tom'])
#把json轉成字典dict:loads
#轉成上面的json = j2
a2 = json.loads(j2)
print(a2)
print('mike的電話 = ',a2['mike'])
程式碼內容
|
範例14-6:讀取網絡上的json檔案 |
(5).讀取網絡上的json檔案
☎範例14-6.py
#目的:讀取網路上一個json檔案:http://acupun.site/lecture/jquery_phoneGap/json/book.json
程式碼:
import json
import urllib.request as request
url = 'http://acupun.site/lecture/jquery_phoneGap/json/book.json'
#開啟網頁:request.urlopen(url)
web = request.urlopen(url)
#讀取網頁文字:web.read()
txt = web.read()
# txt = web.read().decode()
#json轉成字典
dic1 = json.loads(txt)
print(dic1)
print('第一本書 = ',dic1[0]['title'], dic1[0]['author'])
程式碼內容
|
範例14-7:讀取電腦上的json檔案 |
(6).讀取電腦上的json檔案
☎範例14-7.py
程式碼:
import json
import os
#讀檔案
f1 = open('school.json','rt',encoding='utf-8-sig')
#讀檔案內容
txt = f1.read()
#print(txt)
#把json轉成字典dict
dict1 = json.loads(txt)
#print(dict1)
print('第一間學校 = ',dict1[0]['name'], dict1[0]['address'])
for elem in dict1:
print(elem['name'],elem['address'])
程式碼內容
|
3.網路爬蟲BeautifulSoup |
3.網路爬蟲BeautifulSoup: 讀取並分析html網頁標籤
(1).先安裝第三方函數庫,使用:pip install beautifulsoup4
下載並安裝套件
(2).讀取下載在電腦的網頁
☎#注意:這個網頁.htm,必須放在電腦檔案內,不可讀取網絡上網址的網頁
☎(正確)fin = open('web1.htm',encoding='utf-8')
☎(錯誤)fin = open('https://www.python.org/',encoding='utf-8')
☎公式
from bs4 import BeautifulSoup as soup
fin = open('網頁.htm',encoding='utf-8')
txt = fin.read()
htm = soup(txt,'html.parse')
☎讀取網頁標題
print(htm.title.prettify())
☎讀取網頁標籤
公式:BeautifulSoup.find_all(tag)
找出標籤為tag的所有元素
例如:for item in htm.find_all('tr'):
print(item)
☎讀取網頁標籤的innerHtml文字:三種方法:
for item in htm.find_all('a',href='http://epaper.edu.tw/'):
print('innerhtml內容=',item.contents)
print('innerhtml內容=',item.contents[0])
print('innerhtml內容=',item.string)
☎讀取網頁標籤
公式:BeautifulSoup.find_all(tag, attr)
找出標籤為tag+屬性為attr的所有元素
例如:for item in htm.find_all('tr',class='table_head'):
print(item)
|
範例14-8:讀取網頁標題 |
☎範例14-8.py
☎(正確)fin = open('web1.htm',encoding='utf-8')
☎(錯誤)fin = open('https://www.python.org/',encoding='utf-8')
程式碼:
from bs4 import BeautifulSoup as soup
fin = open('web1.htm',encoding='utf-8')
#fin = open('https://www.python.org/',encoding='utf-8')
txt = fin.read()
htm = soup(txt,'html.parser')
#讀取網頁標題
print(htm.title.prettify())
程式碼內容
|
範例14-9:讀取網址的網頁 |
(4).讀取網址的網頁:
☎範例14-9.py
#目的:讀取www.tsu.edu.tw網頁,如何顯示所有超連結的元素
#方法:找出標籤為tag的所有元素
例如:for item in htm.find_all('a'):
print(item)
程式碼:
import urllib.request as request
from bs4 import BeautifulSoup as soup
#使用request讀取網頁內容
url = 'http://web.tsu.edu.tw/bin/home.php'
web = request.urlopen(url)
txt = web.read().decode()
#print(txt)
#使用beautifulSoup發現網頁內容
htm = soup(txt, 'html.parser')
#讀取網頁標題
print(htm.title.prettify())
#讀取網頁所有的超連結
for item in htm.find_all('a'):
print(item)
#讀取網頁所有的超連結中,屬性是href='http://epaper.edu.tw/'
for item in htm.find_all('a',href='http://epaper.edu.tw/'):
print('指定屬性超連結a = ',item)
print('innerhtml內容=',item.contents)
print('innerhtml內容=',item.contents[0])
print('innerhtml內容=',item.string)
程式碼內容
|
| |