陳擎文教學網:客戶關係管理(Customer Relationship Management,CRM) 1.【課程重點與索引目錄】:
一,客戶關係管理概述
3-4,描述統計
3-5,交叉分析表,Cross Tables
1.CRM的定義: 是一種企業與【現有客戶及潛在客戶】之間關係互動的管理。通過對客戶資料的歷史積累和分析,CRM可以增進企業與客戶之間的關係,從而最大化【增加企業銷售收入,提高客戶留存率,滿意度,忠誠度】: ☎2.CRM在經營管理的位階與定位: 【看商業模式圖(經營模式畫布)】➜用【視覺化、結構化】方式,一目了然➜快速檢查一家企業的商業模式,在各方面是否已經準備就緒 ◉商業模式圖的九構面要素, 商業模式圖的四大導向, Uber的商業模式圖, Uber的需求導向3要素:客群CS,客戶關係CR,客群通路Channel, 純喫茶的需求導向3要素:客群CS,客戶關係CR,客群通路Channel, Uber的CRM【市場區隔, Market Segmentation】與【選擇目標客戶, Target Customer】➜都會區白領,商務人士,大學生,特殊需求者 Uber的CRM【差異性行銷】➜尊榮服務,菁英服務,動態收費 商業模式圖簡介影片, ☎3.CRM所收集的客戶數據來源: CRM會通過多個管道全方面收集客戶的相關資訊,包括:【產銷存系統、問卷調查、電子商務銷售數據、追踪並捕捉客戶在網站或APP的瀏覽行為、公司官網、電話訪談、郵件回覆、線上聊天、Line聊天室、市場行銷活動、銷售人員記錄、社群網路記錄】 ※4.分析型CRM: 根據藉由上述各種溝通管道所蒐集到的顧客資料,進而【分析顧客行為】,做【市場區隔, Market Segmentation】與【選擇目標客戶, Target Customers】,然後做【差異化行銷, Differentiated Marketing】,作為企業【決策判斷】的依據 ☎5.CRM做【市場區隔】與【選擇目標客戶】,並做【差異性行銷】的步驟: ➜(1).【市場調查和分析】:收集市場數據,分析市場需求和競爭情況 ➜(2).【選擇目標客戶市場】:根據市場潛力、競爭優勢和企業資源選擇目標市場 ➜(3).【制定營銷策略】:針對目標市場制定營銷和銷售策略 ➜(4).【實施和監控】:執行營銷策略並持續監控效果 ☎6.CRM的【市場區隔, Market Segmentation】最常用的2個方法: ➜(1).【群體細分, Group Segmentation】:根據【人口統計學特徵、購買行為、興趣愛好、地理區隔、行業區隔...】等將客戶分為不同群體,針對性地行銷和服務。 ➜(2).【RFM區隔, Recency, Frequency, Monetary】:RFM分析,可識別出高價值客戶、忠誠客戶、即將流失的客戶,並針對不同的客戶群體制定相應的營銷策略和管理計劃 ➜RFM模型, RFM應用, 7.收集數據的方法: ◉(1).傳統方法:【問卷調查析、訪談】 ◉(2).進階方法:【網站流量收集與分析(GA)、追踪客戶網頁/App上的線上瀏覽行為(GTM)】 ◉(3).最新方法:【人工智慧自動判別客戶行為後即時動態推薦商品】 ◉範例1:問卷調查【男女每週飲料花費】是否有差異?, 統計分析(平均), 結論報告, ◉範例2:問卷調查【對於洗面乳選購的在意點】是否男女會有明顯差異?, 調查數據整理, 描述統計(平均值), 檢定, 結論報告, ◉範例3:【客戶徵信調查】銀行幫客戶打【信用分數】,探討與客戶【總收入,不動產,動產,每月房貸,撫養支出】,信用分數跟哪個參數有關係?, 統計分析檢定, 結論報告, 關係線形圖, ◉選擇適當的統計檢定法, 8.量化分析數據的方法: ◉(1).傳統方法:使用【SPSS】來做數據的統計分析、 ◉(2).進階方法:使用【Python(Scipy)/R程式語言】來做數據的統計分析、 ◉(3).最新方法:使用【生成式AI(ChatGPT 4o,Gemini Pro)】來做數據的統計分析 9.在美國的職業薪水評比排名: ◉【排名圖示】美國薪資排名前3名的,有2個是應用統計相關工作, 應用統計相關工作的薪水,在美國是高於資訊軟體,電腦相關工作的 【與決策有關的資訊技術】:DDDM(數據驅動的決策模式),包括應用統計(SPSS)在CRM關鍵三步驟應用,與精準行銷 ◉【相關課程】老師與DDDM相關的授課課程 10.CRM的主要手段與目的(成效評估):CRM的「10C」: ◉顧客資料(Customer Profile)、顧客知識(Customer Knowledge)、顧客區隔(Customer Segmentation)、客製化行銷(Customization) ◉顧客滿意度(Customer Satisfaction)、顧客保留率(維繫率,Customer Retention)、顧客贏取率(Customer Acquisition)、顧客獲利率(Customer Profitability)、顧客價值(Customer Value)、顧客的貢獻度發展(Customer Development) 11.電商的成效評估指標: ◉回客率(Back off Rate)、網站轉換率(Conversion Rate,流量轉換率=訂單數/總訪客數)、網站獲利率(Profitability Rate,淨利/成本) ≠>≧=≦< ➜ μ α,➔➜→➡↓↑←⇄⇌⟷⇈⇊⇇⇉⇆,⬅⬆⬇⮕⬈⬉⬊⬋⬌⬍⭠⭡⭢⭣⭤ ⭥ ⮂⮃ |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
【一,客戶關係管理概述(Customer Relationship Management,CRM)】 在Google雲端硬碟新增目錄:【問卷】,然後新增Goolge表單【調查素食葷食】 22-1-調查素食葷食問卷
22-2-將問卷調查網址轉成QR Code:
22-3-觀看問卷調查的統計數據:
22-4-瀏覽每一筆收入數據的細節:
22-5-連結至試算表:
chp23.Google表單的製作(2):設定截止時間,或設定最多訂購數目 新增Goolge 表單【02團購泡菜,只有5箱】
23-1-團購泡菜問卷(修改設定:每題預設都是必填)【成果demo】
23-2-在中午11:30前訂購便當【成果demo】:03在中午11:30前訂購便當
➜先取消前面的【無法再新增回覆】的設定
23-3-如何處理每天的訂購便當表單:建立副本【成果demo】
:
chp24.Google表單的製作(3):李克特五點量表(Likert scale),單選題,複選題 新增Goolge 表單【本次活動滿意度調查(單選)】 24-1-本次活動滿意度調查(單選)【成果demo】
24-2-產品興趣意向調查(複選)【成果demo】
chp25.Google表單的製作(4):記錄使用者的email,並允許使用者填寫多日後再修改問卷內容 新增Goolge 表單【是否參加本週日的聚餐?】
25-1-是否參加本週日的聚餐【成果demo】
chp26.Google表單的製作(5):上傳作業檔案(zip),設定背景顏色與標題圖片 新增Goolge 表單【上傳作業檔案(zip)】 26-1-上傳作業檔案(zip)【成果demo】
chp27.Google表單的製作(6):區段跳題(選葷食到葷食區段選菜色,選素食者到素菜區段選菜色) 新增Goolge 表單【區段跳題,選菜色】 27-1-區段跳題,選菜色【成果demo】
chp28-1.Google表單的製作(7):匯入過去的1個表單來修改 新增Goolge 表單【匯入過去的1個表單來修改】 28-1-匯入過去的1個表單來修改訂購便當【成果demo】
chp28-2.Google表單的製作(8):測驗卷:2024年全世界人口數調查 新增Goolge 表單【測驗卷:2024年全世界人口數調查】 28-2-測驗卷:2024年全世界人口數調查【成果demo】
chp28-3.Google表單的製作(9):自動化出題測驗卷:word表格➜自動轉成Google表單 28-3-自動化出題測驗卷:word表格➜自動轉成Google表單【成果demo】
chp28-4.Google表單的製作(10):自動化出題測驗卷:計算機概論PDF考題➜word表格➜Google表單 28-4-自動化出題測驗卷:計算機概論PDF考題➜word表格➜Google表單【成果demo】
chp28-5.Google表單的製作(11):自動化出題測驗卷:2024年全世界人口數調查 28-5-測驗卷:2024年全世界人口數調查【成果demo】
※(1).30-1-北科大軟體雲網址
chp31-1.分析參加夏令營青少年的個資(手動輸入➜SPSS)
※(1).下載或開啟【夏令營青少年的個資pdf檔案】
chp31-2.分析參加夏令營青少年的個資(Excel➜SPSS)
※(1).下載或開啟【夏令營青少年的個資Excel檔案】
chp31-3.分析參加夏令營青少年的個資(CSV➜SPSS)
※(1).下載或開啟【夏令營青少年的個資CSV檔案】
chp31-4.分析參加夏令營青少年的個資(Google表單➜Google試算表➜Excel➜SPSS)
31-4-身高體重調查【成果demo】
chp32-1.繪製【服務年資】的3D長條圖,且標註【計數,百分比,x軸的類別文字】
※(1).【成果Demo】:3D長條圖成果,示意圖:
chp32-2.繪製【擔任職務】的圓餅圖,且標註【計數,百分比,各種職務的類別文字】
※(1).【成果Demo】:繪製【擔任職務】的陰影圓餅圖:
chp32-3.繪製【性別 vs 整體幸福感】的盒形圖,且標註【計數,百分比,各種職務的類別文字】
※(1).【成果Demo】:繪製【性別 vs 整體幸福感】的陰影盒形圖:
chp32-4.繪製【服務地區】的頻數分析線形圖,且標註【標記的數字】
※(1).【成果Demo】:繪製【服務地區】的頻數分析線形圖,共有3種方法都可以做出:
chp32-5.繪製【服務地區 vs 主題幸福感】的對應線形圖,且標註【標記的數字】
※(1).【成果Demo】:繪製【服務地區 vs 主題幸福感】的對應線形圖:
chp32-6.繪製【性別,擔任職務】的綜合頻數分析,用【3D立體長條圖】表示
※(1).【成果Demo】:繪製【性別,擔任職務】的綜合頻數分析,用【3D長條圖】表示:
chp32-7.繪製【(性別,擔任職務) vs 整體幸福感】的3軸對應關係,用【3D立體長條圖】表示
※(1).【成果Demo】:繪製【(性別,擔任職務) vs 整體幸福感】的3軸對應關係,用【3D立體長條圖】表示:
【3-3-A,報表分析(1):線上多層分析處理過程(OLAP, Online Analytical Processing)】 chp33-1.分析國小老師【性別 vs 整體幸福感】的【多層分群分析報表OLAP】
※(1).【成果Demo】:分三層【總計,男,女】的統計分析:
chp33-2.分析國小老師【(性別,服務地區) vs 整體幸福感】的【多層分群分析報表OLAP】
※(1).【成果Demo】:【(男,北區) vs (男,東區) 比較整體幸福感】的【多層分群分析報表OLAP】
※(3).下載問卷調查資料:教師幸福感指數調查 ※上傳【32-1-教師幸福感問卷調查_1.xlsx】,到北科大軟體雲的windows電腦的F:\硬碟 ※【問卷調查題目】:國小教師職場生活感受調查 ........ ※【服務地區】:1男,2女 ※【服務地區】:1x科任未兼任行政,2x教師兼組長,3x級任未兼任行政,4教師兼主任 ※【服務地區】:1北區,2中區,3南區,4東區 ※【服務年資】:1:5年以下,2:6-10年,3:11-15年,4:16-20年,5:21-25年,6:26年以上 ※(4).用北科大軟體雲的SPSS讀入【32-1-教師幸福感問卷調查_1.xlsx】檔案 讀入問卷檔案,示意圖1, ※(6).建立【多層分群分析處理,OLAP】 ➜上方【分析】➜【報告】➜【OLAP資料方塊] 示意圖, ➜設定【摘要變數,目標y=f(x)】➜【整體幸福感】 ➜設定【分組變數,x,分群,groupby】➜【性別,服務地區】 設定分群變數x,目標求值y,示意圖, ➜設定【統計計量數】➜【觀察值數,平均,標準差】 點按【統計資料】按鈕,示意圖, 設定【統計計量數】,示意圖, ➜設定【標題】➜【國小教師(性別,服務地區)的整體幸福感分析】 點按【標題】按鈕,示意圖, 設定標題文字,示意圖 ※(7).建立【多層多維度分析】➜【總計,男/北區,男/東區】 ➜先在【性別:總計-報表表格】的空白處➜滑鼠右鍵➜【複製】➜貼在下方 複製第1個表格,貼到之後, ➜double click【總計】➜選擇【男】 ➜double click【總計】➜選擇【北區】 分三層【男/北區,男/東區】的統計分析,示意圖 ※(8).建立【北區/東區的『差異性』分析】 ※【服務地區】:1北區,2中區,3南區,4東區 ➜點按【差異】按鈕➜ ➜勾選【群組之間的差異】 ➜【組別變數】➜選擇【服務地區】 ➜【種類】➜輸入【1】(1北區) ➜【減種類】➜輸入【4】(4東區) ➜把2個變數➜移動到【配對】➜(1-4)default 設定參數:北區/東區的『差異性』分析,示意圖 北區/東區的『差異性』分析,示意圖 ※(9).分析【男老師,(北區-東區)差異的%是多少?】 ➜先在【性別:總計-報表表格】的空白處➜滑鼠右鍵➜【複製】➜貼在下方 複製第1個表格,貼到之後, ➜double click【總計】➜選擇【男】 ➜double click【總計】➜選擇【北區】 男老師,在(北區-東區)差異%分析,示意圖 分析【男老師,(北區-東區)差異的%是多少?】 = 11.6% 33-5.word分析報告 chp33-3.分析【國小兒童(男女 vs 身高)】的【列的報告摘要】
※(1).【成果Demo】:國小兒童身高的『列』統計分析(分群不同性別,不同班級):
※(4).下載問卷調查資料:國小兒童身高調查 ※上傳【33-3-國小兒童身高.sav】,到北科大軟體雲的windows電腦的F:\硬碟 ※(5).用北科大軟體雲的SPSS讀入【33-3-國小兒童身高.sav】檔案 ※(6).建立【列的報告摘要】 ➜上方【分析】➜【報告】➜【列的報告摘要] 示意圖, ➜設定【資料欄變數,目標y=f(x)】➜【身高】 ➜設定【岔斷欄變數,x,分群,groupby】➜【性別】 ➜勾選【顯示觀測值】 設定岔斷變數x,資料欄變數y,示意圖, ➜設定【摘要】➜【平均值,觀察值數目】 設定【摘要,統計計量數】,示意圖, ➜設定【標題】➜【置中】➜【國小兒童身高的分群分析】 列報表結果:身高欄位太窄,示意圖, ※(7).修改【身高的欄位寬度】 ➜打開【列的報告摘要】➜【資料欄變數】的【格式】➜【欄寬】=20 設定【欄寬】,示意圖, 列報表結果,示意圖, ※(8).修改【每個性別(男,女)下都有計算平均值】 ➜打開【列的報告摘要】➜【岔斷變數】的【摘要】➜勾選【平均值】 設定【岔斷變數】的【摘要】,示意圖, 列報表結果,示意圖, ※(9).設定【2個岔斷變數:性別,班級】 ➜打開【列的報告摘要】➜新增1個【岔斷變數】:【班級】 ➜設定【岔斷變數】的【摘要】➜勾選【平均值】 設定【岔斷變數】的【摘要】,示意圖, 列報表結果(男),示意圖, 列報表結果(女),示意圖, chp33-4.分析【國小兒童(男女 vs 身高)】的【欄位的報告摘要】
※(1).【成果Demo】:國小兒童身高的『欄位』統計分析(分群不同性別,不同班級):
※(4).下載問卷調查資料:國小兒童身高調查 ※上傳【33-3-國小兒童身高.sav】,到北科大軟體雲的windows電腦的F:\硬碟 ※(5).用北科大軟體雲的SPSS讀入【33-3-國小兒童身高.sav】檔案 ※(6).建立【列的報告摘要】 ➜上方【分析】➜【報告】➜【欄位的報告摘要] 示意圖, ➜在最下方顯示整體平均➜點按【摘要】➜勾選【顯示總計】 設定【摘要】【顯示總計】,示意圖, ➜設定【標題】➜【置中】➜【國小兒童身高的分群分析】 ※(7).設定【資料欄變數】 列報表結果:身高欄位太窄,示意圖, ➜設定『每個欄位只顯示平均,不顯示個別值』➜點按【資料欄變數】➜【摘要】➜勾選【平均值】 資料欄變數只顯示平均,示意圖, ➜設定【資料欄變數】的欄位寬度➜點按【格式】➜【欄寬】=20 設定資料欄(身高)的欄寬,示意圖, ※(8).設定岔斷變數【性別】 ➜點按【性別】➜【選項】➜勾選【顯示小計】 設定資料欄(性別)的選項,示意圖, ➜點按【班級】➜【選項】➜勾選【顯示小計】 設定資料欄(班級)的選項,示意圖, 欄的成果摘要成果,示意圖, 【3-3-C,報表分析(4):觀察值摘要 Cases Summary】 chp33-5.分析【國小兒童(男女 vs 身高)】的【觀察值摘要 Cases Summary】
※(1).【成果Demo】:國小兒童身高的統計分析(分群不同性別,不同班級):
※(4).下載問卷調查資料:國小兒童身高調查 ※上傳【33-3-國小兒童身高.sav】,到北科大軟體雲的windows電腦的F:\硬碟 ※(5).用北科大軟體雲的SPSS讀入【33-3-國小兒童身高.sav】檔案 ※(6).建立【觀察值摘要 Cases Summar】 ➜上方【分析】➜【報告】➜【觀察值摘要 Cases Summar] 示意圖, ➜設定【變數,目標y=f(x)】➜【身高】 ➜設定【分組變數,x,分群,groupby】➜【性別,班級】 ➜取消勾選【顯示觀測值】 設定變數x,分組變數y,示意圖 ➜設定【統計資料】➜【觀察值數目(樣本數N),平均值,中位數】 設定【統計資料,統計計量數】,示意圖 ➜設定【選項(標題)】➜【標題】➜【國小兒童身高的分群分析】 設定標題,示意圖 報表結果,示意圖 33-5.word分析報告 【3-4-A,描述統計(1):次數分配表(Frequencies,頻數分析)】 chp34-1.分析【120名男子血壓分佈】的【次數分配表(Frequencies,頻數分析,單一變數的常態分佈)】
※(1).【成果Demo】:【120名男子血壓分佈】的【次數分配表(Frequencies,頻數分析)】:
chp34-2.分析【100名大學生血清蛋白分佈】的【次數分配表(Frequencies,頻數分析,單一變數的常態分佈)】
※(1).【成果Demo】:【100名大學生血清蛋白分佈】的【次數分配表(Frequencies,頻數分析)】:
【3-4-B,描述統計(2):描述統計(描述統計分析,Descriptive Statistics)】 chp34-3.分析【期末考English成績】的【描述統計分析,Descriptive Statistics】
※(1).【成果Demo】:【期末考English成績】的【描述統計分析,Descriptive Statistics】:
chp34-4.分析【20名嬰兒體重】的【描述統計分析,Descriptive Statistics】
※(1).【成果Demo】:【20名嬰兒體重】的【描述統計分析,Descriptive Statistics】:
chp34-5.分析【一週飲料花費】的【預檢資料,Explore】:做分組分群統計摘要分析+圖形分組比對
※(1).【成果Demo】:【一週飲料花費】的【預檢資料,Explore】:
chp34-9.分析【一週飲料花費】的【預檢資料,Explor】:看數據是否有【異常值】,或是否接近【常態分佈】
※(1).【成果Demo】:【一週飲料花費】的【預檢資料,Explor】:看數據是否有【異常值】
chp34-10.分析【120名男子血壓分佈】的【預檢資料,Explor】:看數據是否有【異常值】,或是否接近【常態分佈】
※(1).【成果Demo】:【120名男子血壓分佈】的【預檢資料,Explor】:看數據是否有【異常值】
☎【3-5,交叉分析表,Cross Tables】:探討2個類別變數之間的關聯性(重要) chp35-1.【ABC三個品牌與喜歡原因DEF之間的關聯性】的【交叉分析表解析】➜分析報告【SPSS➜Excel➜Word】
※(1).【成果Demo】:【ABC三個品牌與喜歡原因DEF之間的關聯性】的【交叉分析表解析】➜分析報告【SPSS➜Excel➜Word】:
chp35-2.【品牌與喜好原因】的【交叉分析表應用】➜變成三種定量分析的百分比表格➜可說出數據背後的3種物理意義,與定量比對➜分析報告【SPSS➜Excel➜Word】
※(1).【成果Demo】:【品牌與喜好原因】的【交叉分析表應用】➜變成三種定量分析的百分比表格➜可說出數據背後的3種物理意義,與定量比對
chp35-3.【交叉分析表的圖形比較:可以一眼看出關聯因子的關聯特色】:【品牌與喜好原因】交叉分析後以長條圖比較
※(1).【成果Demo】:【交叉分析表的長條圖比較:可以一眼看出關聯因子的關聯特色】:【品牌與喜好原因】交叉分析後以長條圖比較
☎chp35-4.【靈魂拷問,大哉問】:
客戶【每個月到星巴克的次數】與【性別】是否存在顯著關聯?】(重要)
※(1).【成果Demo】:客戶【每個月到星巴克的次數】與【性別】是否存在顯著關聯?】
(4).上傳中文字型檔到ChatGPT 4o
◉【思源黑體字型NotoSansTC-Medium】下載連結(推薦下載這個,比較簡單) ※上傳【35-4-星巴克每個月消費次數與零用金關聯.sav】,到北科大軟體雲的windows電腦的F:\硬碟 ※(4).用北科大軟體雲的SPSS讀入【35-4-星巴克每個月消費次數與零用金關聯.sav】檔案 ➜此問卷共有200份受訪者填寫 ➜【次數】:每個月到星巴克消費次數,1為<=3次,2為4~9次,3為>=10次 ➜【零用金】:每個月可支配的零用金,1為<=5000,2為5001~10000次,3為>=10001次 ➜【性別】:1為男,2為女 ※(5).建立【交叉分析表:每個月到星巴克消費次數 vs 性別】 ➜上方【分析】➜【描述統計】➜【交叉表分析,Cross tables】 ➜設定【列】➜【每個月到星巴克消費次數】 ➜設定【欄】➜【性別】 ➜設定【資料格】➜【計數】➜【觀察值】 
➜ 【靈魂拷問,大哉問】:客戶【每個月到星巴克的次數】與【性別】是否存在顯著關聯?】 ➜ 【重要觀念】:探討問卷調查中2個變數之間是否有關聯,無法目測,必須用【獨立性檢定Test】,檢定後才能知道是否2個變數有關聯? ➜【觀察1】:若是觀察樣本數(觀察值),似乎男生的次數少,女生的次數多,似乎【次數】與【性別】有關聯 ➜【請問】:你能夠說【到星巴克購買的女生購買次數多於男生嗎? 你能夠說【購買次數與性別有關聯嗎】? ※(6).比較【交叉分析表:次數 vs 性別】以【百分比】方式表示 設定【百分比-欄】,示意圖, 
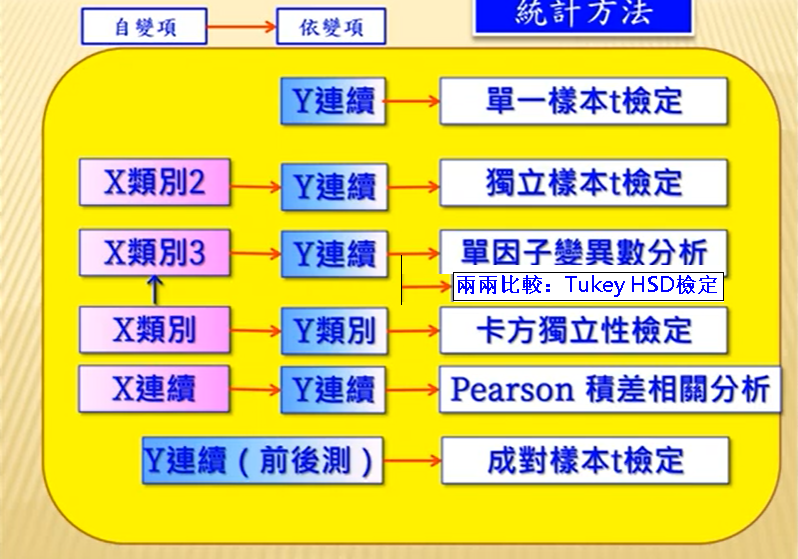
➜【發現】:不論購買次數【低,或高】,男女的比例,都是差不多 ➜ 【結論】:探討問卷調查中2個變數之間是否有關聯,不能夠用樣本數(計數)來比較,必須轉換成【百分比】才準確 ※(7).【統計檢定】:判斷2個變數是否有關聯 ➜ 【請問】:探討這個問卷的2個變數【次數,性別】的關聯性,必須採用哪一種檢定? ➜ ☎【判斷檢定方法的最重要圖表】: ➜根據(x, y)對應的不同格式,可以選擇不同的統計檢定方法: 

➜ 【重要觀念】:若2個變數都是【類別,種類】變數(性別,地區,是否有房子,是否有汽車), 即【類別 vs 類別】變數的關聯性, 則必須用【卡方檢定】 ➜ ☎【結論】:【類別 vs 類別】用【卡方檢定(χ² test)】 ※(8).建立【交叉分析表:次數 vs 性別】的【統計檢定】 ➜設定【統計資料】➜勾選【卡方檢定】 勾選【卡方檢定】,示意圖, 
➜【注意1】:查表【卡方分配表】的【顯著水準➜一般都是以 α = 0.05來設定】 ➜【判別技巧1】:若是我們計算出來的【漸近顯著性】值< 0.05,表示【2個變數之間呈現顯著性關聯】 ➜【判別技巧2】:若是我們計算出來的【漸近顯著性】值> 0.05,表示【2個變數之間沒有關聯】 ➜【注意2】:df是自由度,degree of freedom ➜【注意3】:數值 = 卡方值 = χ² = Chi-Square ➜☎【結論】:計算結果的【漸近顯著性】值 = 0.905 > 0.05,表示【2個變數之間沒有關聯】 ➜☎【表示】:受訪者到星巴克的【次數高低】,並不會因為【性別】而有顯著差異 ※(9).【判斷2個變數之間是否有顯著關聯】的【統計檢定】步驟: ➜卡方獨立性檢定(Chi-Square Test of Independence):適用於類別變數。 ➜步驟1:設置2種假設: ◉零假設(𝐻0):兩個變數之間獨立(無顯著關聯)。 ◉對立假設(𝐻1):兩個變數之間不獨立(有顯著關聯)。 ➜步驟2:根據數據構建列聯表(交叉表)。 ➜步驟3:計算卡方統計量(𝜒2):使用公式計算卡方值。 ➜步驟4:計算p值:根據卡方值和自由度,查找對應的p值。 ➜步驟5:比較顯著水平:如果p值小於顯著水平(如0.05),則拒絕零假設,認為兩變數之間有顯著關聯。
☎chp35-4-(2).【使用AI來做統計分析】:
客戶【每個月到星巴克的次數】與【性別】是否存在顯著關聯?】(重要)
※(1).【成果Demo】:客戶【每個月到星巴克的次數】與【性別】是否存在顯著關聯?】
☎chp35-5.客戶【每個月到星巴克的次數】與【每月可支配的零用金】是否存在顯著關聯?
※(1).【成果Demo】:客戶【每個月到星巴克的次數】與【每月可支配的零用金】是否存在顯著關聯?
(4).上傳中文字型檔到ChatGPT 4o
◉【思源黑體字型NotoSansTC-Medium】下載連結(推薦下載這個,比較簡單) ※上傳【35-4-星巴克每個月消費次數與零用金關聯.sav】,到北科大軟體雲的windows電腦的F:\硬碟 ※(4).用北科大軟體雲的SPSS讀入【35-4-星巴克每個月消費次數與零用金關聯.sav】檔案 ➜此問卷共有200份受訪者填寫 ➜【次數】:每個月到星巴克消費次數,1為<=3次,2為4~9次,3為>=10次 ➜【零用金】:每個月可支配的零用金,1為<=5000,2為5001~10000次,3為>=10001次 ➜【性別】:1為男,2為女 ※(5).建立【交叉分析表:每個月到星巴克消費次數 vs 零用金】 ➜上方【分析】➜【描述統計】➜【交叉表分析,Cross tables】 ➜設定【列】➜【次數】 ➜設定【欄】➜【零用金】 ➜設定【資料格】➜【百分比】➜【欄位】 
※(6).【統計檢定】:判斷2個變數是否有關聯 ➜已知【類別 vs 類別】:用【卡方檢定(χ² test)】 ➜【疑問】:零用金是數值(10000),不是類別,為什麼可以用【卡方檢定?】 ➜請說出你的答案? ※(7).建立【交叉分析表:次數 vs 零用金】的【統計檢定】 ➜設定【統計資料】➜勾選【卡方檢定】 
➜【判別技巧】:若是我們計算出來的【漸近顯著性】值< 0.05,表示【2個變數之間呈現顯著性關聯】 ➜☎【結論】:計算結果的【漸近顯著性】值 = 0.013 < 0.05,表示【2個變數之間有顯著關聯】 ➜☎【表示】:受訪者到星巴克的【次數高低】,會因為【零用金】而有顯著差異 ※(8).如何目測看出【受訪者到星巴克的【次數高低】,會因為【零用金】而有顯著差異】 ➜目測:每個月到星巴克較少者(小於3次),主要是零用金較少者(<5000) ➜目測:每個月到星巴克稍多者(4~9次),主要是零用金較多者(>10000) ➜目測:每個月到星巴克最多者(大於10次),主要是零用金較多者(>10000) ➜結論:每個月到星巴克的次數,的確與零用金的高低而有顯著差異 
※(9).如何繪圖(困難點:Y軸要顯示百分比) 

35-5.Final完整的word分析報告
☎chp35-6.【縮減組數】卡方檢定必須要每個類別期望個數不小於5才有效:調查【男女】與【運動時間】是否存在顯著關聯?
※(1).【成果Demo】:調查【男女】與【運動時間】是否存在顯著關聯?
chp35-7.ChatGPT等AI的圖表顯示中文字,必須安裝中文字型檔 【3-6,相對比分析,比例分析,Ratio】:探討2個類別變數對比(相除)的統計分析,探討2個變數對比的關聯性 chp36-1.【中國大陸2007年城鄉消費額分析】,探討是否不同的城鄉消費有明顯差異?
※(1).【成果Demo】:【中國大陸2007年城鄉消費額分析】,探討是否不同的城鄉消費有明顯差異?:
【3-7,單一樣本t檢定(1個連續數值y)】:探討1個連續變數樣本平均值,與指定檢定值之間是否存在顯著差異
chp37-1.某校【大一新生體重數據】與【5年前大一平均體重65.6】相比,是否有顯著差異?(雙尾檢定)
※(1).【成果Demo】:某校【大一新生體重數據】與【5年前大一平均體重65.6】相比,是否有顯著差異?
※(4).用北科大軟體雲的SPSS新增一個新的【SPSS】檔案 ➜在【變數視圖】視窗➜建立2個欄位【編號,體重】 建立2個欄位【編號,體重】,示意圖 ➜在【資料視圖】視窗➜複製【37-1-大一新生體重數據.csv】的數據,貼上 複製csv數據,示意圖 貼到SPSS,示意圖 ※(5).建立【單一樣本t檢定】 ➜上方【分析】➜【比較平均數法】➜【單一樣本t檢定】 點選【單一樣本t檢定】,示意圖 ➜設定【檢定變數】➜【體重】 ➜設定【檢定值】➜【65.6】 ➜設定【選項】➜【信賴區間百分比】= 95% 點選【單一樣本t檢定】,示意圖 
➜【平均】:67.50似乎比5年前(65.6)還要高一些 ➜【但是檢定後發現】:p= 0.095>信賴水準0.05,所以不顯著(符合Ho虛無假設,2個變數沒有差異) ➜ 【結論】:現在大一學生的體重與5年前學生體重相比,沒有顯著差別(差不多) ※(6).【單一樣本t檢定】步驟: ➜【單一樣本t檢定】:適用於單一連續數值變數。 ➜步驟1:設置2種假設: ◉零假設(𝐻0),又名虛無假設:兩個變數之間獨立(無顯著關聯,無顯著差異)。 ◉對立假設(𝐻1):兩個變數之間不獨立(有顯著關聯,有顯著差異)。 ➜步驟2:用公式計算t檢定值。 ➜步驟3:計算p值:查找對應的p值。 ➜步驟4:比較顯著水平:如果p值小於顯著水平(如0.05),則拒絕零假設,認為兩變數之間有顯著關聯。 37-1.word分析報告
chp37-2.【大學生每週運動時間】與【5年前平均70分鐘】相比,是否有今年已經明顯增加?(單尾檢定)
※(1).【成果Demo】:【大學生每週運動時間】與【5年前平均70分鐘】相比,是否有今年已經明顯增加?(單尾檢定)?
※(8).如何決定使用【雙尾檢定,或單尾檢定】? 單尾與雙尾檢定的選擇在統計檢定中,單尾檢定與雙尾檢定的選擇取決於研究問題的假設方向性。 1. 雙尾檢定(Two-tailed Test)的用途當研究問題探討是否有差異,但不特別關注增加或減少的方向時,應使用雙尾檢定。 理由:我們關注的是任何方向的變化(可能增加或減少),因此需檢查分布的兩端。 例如:「與5年前相比,運動時間是否有差異?」這是一個雙尾檢定問題,因為我們不預設差異方向。 2. 單尾檢定(One-tailed Test)的用途當研究問題明確關注某一特定方向的變化(如「增加」或「減少」)時,應使用單尾檢定。 理由:我們的關注點僅限於「運動時間是否增加」,不需要檢查是否減少。 例如:「今年的運動時間是否明顯增加?」這是一個單尾檢定問題,因為我們只假設變化的方向是「增加」。 3. 為什麼題目問題影響檢定選擇?統計檢定的方向性反映研究目標:
4. 實例比較
關鍵差異:
5. 結論「是否有今年已經明顯增加?」,【增加】2字表示【頂端】,所以已明確指出感興趣的是「增加」,因此應採用單尾檢定。 chp37-3.某報紙宣稱【大學生每週飲料花費已經 ≥ 100元】,是否可以否定該宣稱(α < 0.05)?
※(1).【成果Demo】:某報紙宣稱【大學生每週飲料花費已經 ≥ 100元】,是否可以否定該宣稱(α < 0.05)?
【3-8,獨立樣本t檢定(2類別x vs 連續數值y)】:檢定2個獨立樣本(2個選擇的種類)的總體平均數,是否存在顯著差異? chp38-1.判定【男女每週飲料花費】,【是否存在差異】?
※下載問卷調查數據csv:男女之飲料花費
※(9).【獨立樣本t檢定】的重要進階心法:什麼是【右尾檢定,左尾檢定】? (A).心法1:右尾檢定,就是判斷是否第1個群組變數比較大? 心法:左尾檢定,就是判斷是否第2個群組變數比較大? 右尾檢定,示意圖, 左尾檢定,示意圖, 
※(B).心法2:什麼是【第1個群組變數】? 
※(C).心法3:如何判斷【右尾檢定】的符合H1假設? 如果 t值>0,且p值(右尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第一組的均值顯著大於第二組」 右尾檢定,示意圖, 
※(D).心法4:如何判斷【左尾檢定】的符合H1假設? 如果 t值<0,且p值(左尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第二組的均值顯著大於第一組」 左尾檢定,示意圖, 
chp38-2.判定【男女每週運動時間】,【男生是否大過女生】?
※下載問卷調查數據csv:男女每週之運動時間比較
※(9).【獨立樣本t檢定】的重要進階心法:什麼是【右尾檢定,左尾檢定】? (A).心法1:右尾檢定,就是判斷是否第1個群組變數比較大? 心法:左尾檢定,就是判斷是否第2個群組變數比較大? 右尾檢定,示意圖, 左尾檢定,示意圖,
※(B).心法2:什麼是【第1個群組變數】?
※(C).心法3:如何判斷【右尾檢定】的符合H1假設? 如果 t值>0,且p值(右尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第一組的均值顯著大於第二組」 右尾檢定,示意圖,
※(D).心法4:如何判斷【左尾檢定】的符合H1假設? 如果 t值<0,且p值(左尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第二組的均值顯著大於第一組」 左尾檢定,示意圖,
chp38-3.判定【台北/雲林地區所得比較】,是否【台北所得高過於雲林】?
※(1).【問卷表單Demo】:判定【台北/雲林地區所得比較】,是否【台北所得高過於雲林】?
※(9).【獨立樣本t檢定】的重要進階心法:什麼是【右尾檢定,左尾檢定】? (A).心法1:右尾檢定,就是判斷是否第1個群組變數比較大? 心法:左尾檢定,就是判斷是否第2個群組變數比較大? 右尾檢定,示意圖, 左尾檢定,示意圖,
※(B).心法2:什麼是【第1個群組變數】?
※(C).心法3:如何判斷【右尾檢定】的符合H1假設? 如果 t值>0,且p值(右尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第一組的均值顯著大於第二組」 右尾檢定,示意圖,
※(D).心法4:如何判斷【左尾檢定】的符合H1假設? 如果 t值<0,且p值(左尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第二組的均值顯著大於第一組」 左尾檢定,示意圖,
☎chp38-4.【量表的檢定】:判定【男女對於洗面乳選購的在意點】,是否【男女會有明顯差異?】(1)(重要)
※(1).
【問卷表單Demo】:建立Google問卷調查表單:男女對於洗面乳選購的在意點調查
※(9).【獨立樣本t檢定】的重要進階心法:什麼是【右尾檢定,左尾檢定】? (A).心法1:右尾檢定,就是判斷是否第1個群組變數比較大? 心法:左尾檢定,就是判斷是否第2個群組變數比較大? 右尾檢定,示意圖, 左尾檢定,示意圖,
※(B).心法2:什麼是【第1個群組變數】?
※(C).心法3:如何判斷【右尾檢定】的符合H1假設? 如果 t值>0,且p值(右尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第一組的均值顯著大於第二組」 右尾檢定,示意圖,
※(D).心法4:如何判斷【左尾檢定】的符合H1假設? 如果 t值<0,且p值(左尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第二組的均值顯著大於第一組」 左尾檢定,示意圖,
☎☎☎chp38-5.【實戰市場調查後的商品開發:如何設計男女洗面乳商品】:判定【男女對於洗面乳選購的在意點】,是否女生會比男生來得明顯重視?(同時做差異檢定,高低檢定)(2)(重要)
※(1).
【第2種表單】建立可以取代【5點量表】又可以【儲存數字】的Google問卷表單
請開啟【上一題的Google問卷表單】,要做修改 ☎【請問1】:上述Google問卷的選項若要儲存【數字1,2,3...】,除了採用【5點量表】外,還有什麼方法? ➜☎【請問2】:上述Google問卷的同時有很多一樣選項的題目,首選是【單選方格】,但是它沒有支援【5點量表】,只能用【文字選擇題】來做,如何才能儲存數字欄位? ➜☎【請問3】:上述Google問卷的【性別】,若是用【5點量表】來做,有點怪怪的,可以用【選擇題/單選題】來做嗎? ➜☎【請問4】:難道【5點量表】是問卷調查唯一的方法了嗎? ➜☎【請問5】:這個是【雙尾檢定,還是右尾檢定,還是左尾檢定】? ※(2).【修改Google表單】:找出,又可以取代【5點量表】又可以【儲存數字】的做法: 【第2種表單】建立可以取代【5點量表】又可以【儲存數字】的Google問卷表單 ➜【方法1】:使用【選擇題】,其中的項目用【1,2,3...】 ➜【方法2】:使用【單選方格(5點量表)】,其中的項目用【1,2,3...】 ※輸入3筆數據 回覆後建立的Google試算表檔案:發現欄位名稱過長 ➜【檔案】➜【下載】➜ ➜把【時間戳記】➜修改成【編號】➜這個欄位,滑鼠右鍵➜修改【儲存格格式】➜改成【數值】➜小數點0位 ➜把其它欄位修改成簡短欄位名稱:【抗痘,去油,美白,保濕,保濕,緊緻毛孔,卸妝】 ➜修改編號的值,輸入【1,2,3,.....】 修改後的excel數據畫面,示意圖 ※(3).下載問卷調查的完整資料:男女對於洗面乳選購的在意點調查 ※開啟【38-4-男女對於洗面乳選購的在意點調查.csv】, 複製csv的數據,貼到excel檔案 修改後的excel數據畫面,示意圖 ※(4).【第3種表單】,選擇項目都是文字,最後到Excel再去取代成數字 ※輸入3筆數據: 回覆後建立的Google試算表檔案:發現欄位名稱過長 ➜【檔案】➜【下載】➜ ➜把【時間戳記】➜修改成【編號】➜這個欄位,滑鼠右鍵➜修改【儲存格格式】➜改成【數值】➜小數點0位 ➜把其它欄位修改成簡短欄位名稱:【抗痘,去油,美白,保濕,保濕,緊緻毛孔,卸妝】 ➜修改編號的值,輸入【1,2,3,.....】 ➜把【非常不重要】修改成【1】 ➜把【不重要】修改成【2】 ➜把【普通】修改成【3】 ➜把【重要】修改成【4】 ➜把【非常重要】修改成【5】 ➜把【男,女】修改成【1,2】 修改後的excel數據畫面,示意圖 ※(5).用北科大軟體雲的SPSS新增新的檔案,先在【變數視圖】視窗,建立2個欄位 ➜【編號】 ➜【抗痘】:數值 ➜【去油】:數值 ➜【美白】:數值 ➜【緊緻毛孔】:數值 ➜【卸妝】:數值 ➜【性別】:數值➜在【值】欄位建立標籤(1:男,2:女) ➜將excel的全部數據,複製貼到SPSS 示意圖1, 示意圖1 ※(6).建立【獨立樣本t檢定】 ➜上方【分析】➜【比較平均數法】➜【獨立樣本t檢定】 ➜設定【檢定變數】➜【抗痘,去油,美白,保濕,保濕,緊緻毛孔,卸妝】 ➜設定【分組變數】➜【性別】 ➜設定【選項】➜【信賴區間百分比】= 95% ➜點按【定義群組】: ➜設定【群組1】➜1 ➜設定【群組2】➜2 示意圖1 ※(7).要判斷這是【雙尾檢定,還是單尾(左/右尾)檢定?】 ➜題目問題的假設:判定【男女對於洗面乳選購的在意點】,是否【女生是不是會比男生來得明顯重視?】 ➜【注意】:H0虛無假設/否定假設:是這句話的相反(女生是不是會比男生來得明顯重視?)➜相反➜女生沒有比男生明顯重視這些洗面乳屬性 ➜H0虛無假設/否定假設:μ1 ≧ μ2(女生μ2沒有比男生μ1明顯重視這些洗面乳屬性,μ2<μ1,男生重視值≧女生) ➜H1對立假設:μ1 < μ2(男生重視值<女生) ➜【注意】:這是【單尾檢定】(左尾檢定) 

※(8).【注意】:上面的檢定表,【要經過2階段檢定】 ※(A-第1階段):先看【變異數等式的Levene檢定】 ➜判斷【顯著性是否<0.05】:全部的【顯著性值】都>0.05➜➜表示接受虛無假設【2個母體變異數相等的假設】➜第1列的值 ※(B-第2階段):再看【平均值等式的t檢定】 二,獨立樣本t檢定,判斷過程: 1.這是【單尾檢定】➜所以要把【顯著性值】/2 2.判斷方法:【顯著性是否<0.05】: 3.判斷【抗痘】的【顯著性值】0.523/2 =0.2616>0.05 ➜表示接受【虛無假設H0】➜【男生重視值≧女生】 4.判斷【去油】的【顯著性值】0.096/2 = 0.048<0.05 ➜表示接受【獨立假設H1】➜【男生重視值<女生】。 5.但【去油】屬性,它的檢定顯著性值,在0.05左右,在顯著/不顯著邊緣。 6.判斷【美白,保濕,保濕,緊緻毛孔,卸妝】的【顯著性值】都<0.05 ➜表示接受【對立假設H1】➜【男生重視值<女生】 ➜【注意,要選擇第1列的顯著性值】:這是因為階段1,已經證明,必須選擇【相等變異數】 
三,結論: 1.【結論1】:在選購洗面乳時,男生比較在意的點是【抗痘】 2.【結論2】:在選購洗面乳時,女生比較在意的點是【去油,美白,保濕,保濕,緊緻毛孔,卸妝】。 3.【結論3】:【去油】屬性,它的檢定顯著性值,在0.05左右,在顯著/不顯著邊緣。 4.【結論3】:若是看平均數字,女生在考慮【美白,保濕,保濕,緊緻毛孔,卸妝】的分數比較高,【所以:明顯是女生比較會考慮,男生比較不在意】 5.【結論4】:若是看平均數字,男生在考慮【抗痘,去油】的分數比較高,【所以:明顯是男生比較會考慮所買的洗面乳能否『抗痘,去油』】 ※四,【發現問題】:數據太雜亂,無法精簡,一目了然地描述 ➜在撰寫報告時,若只是參考SPSS的輸出表格,會因為參數太多,而很難一目了然地說明數據 ➜所以一般會把【SPSS表格➜貼到Excel修改,排序,彙整一個精簡表格➜貼到Word寫報告】 ※(9).【獨立樣本t檢定】的重要進階心法:什麼是【右尾檢定,左尾檢定】? (A).心法1:右尾檢定,就是判斷是否第1個群組變數比較大? 心法:左尾檢定,就是判斷是否第2個群組變數比較大? 右尾檢定,示意圖, 左尾檢定,示意圖,
※(B).心法2:什麼是【第1個群組變數】?
※(C).心法3:如何判斷【右尾檢定】的符合H1假設? 如果 t值>0,且p值(右尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第一組的均值顯著大於第二組」 右尾檢定,示意圖,
※(D).心法4:如何判斷【左尾檢定】的符合H1假設? 如果 t值<0,且p值(左尾)<0.05,則拒絕𝐻0假設,接受𝐻1假設,表示「第二組的均值顯著大於第一組」 左尾檢定,示意圖,
chp38-6.把上述【男女對於洗面乳選購的檢定】➜寫成分析報告【SPSS➜Excel➜Word】(3)
※(1).
【第2種表單】建立可以取代【5點量表】又可以【儲存數字】的Google問卷表單
※(2).先建立【觀測值摘要】 ➜【原因】:因為我們要排序,還要分組分群分析比較,所以首選【觀測值摘要】 ➜SPSS開啟上1個資料檔案➜上方【分析】➜【報告】➜【觀測值摘要】 ➜設定【變數】➜【抗痘,去油,美白,保濕,保濕,緊緻毛孔,卸妝】 ➜設定【分組清單】➜【性別】 ➜設定【統計資料】➜選【平均數】 ➜取消勾選【顯示觀察值】 設定參數,示意圖, 
※(3).將SPSS【觀察值摘要】表格【複製】到【Excel】 ➜在表格➜【滑鼠右鍵】➜【複製】 ➜貼到Excel去編輯每1個表格 ➜複製➜【A3:H6】 【貼表格到Excel編輯】,示意圖, ➜到【B9】➜【選擇性貼上/轉置(T)】 【選擇性貼上/轉置(T)】,示意圖, 
➜到【A9】➜輸入【編號】➜新增編號1,2,3,4....7 
※(4).【計算排名】 ➜到【F9】➜輸入【排名】 ➜到【F10】➜輸入公式【=RANK(E10,$E$10:E$16)】 
※(5).到SPSS【顯示獨立樣本t檢定表格】 ➜在表格➜【滑鼠右鍵】➜【複製】 ➜貼到Excel➜【到新的工作表】➜到【B1】➜貼上 【貼表格到Excel,並刪除某些欄位列】,示意圖, ➜刪除【第I欄位以後各個欄位】 ➜刪除【第4列,第1,第2列】 ➜刪除【G欄位:自由度】 【刪除後】,示意圖, ➜輸入儲存格文字【編號,屬性,變異數檢定】➜ 示意圖1, ※(6).【處理B欄空格】 ➜選取【B2:B13】➜【複製】 ➜點按【B3】➜【選擇性貼上】➜【略過空格】 選取【B2:B13】,示意圖1, 【選擇性貼上】➜【略過空格】,示意圖1, 【成果】,示意圖, ※(7).【處理F欄,E欄的空格】 ➜按照上述的做法,相同做法 【成果】,示意圖, ※(8).【刪除『變異數檢定』欄位,全部是『不採用相等變異數』的列】 ➜原因:根據判斷【顯著性是否<0.05】:全部的【顯著性值】都>0.05➜➜表示接受虛無假設【2個母體變異數相等的假設】➜第1列的值 【刪除多列】,示意圖, 【成果】,示意圖, ※(9).複製【G欄】到【第1個工作表『觀察值摘要』的最後2個欄位】 ➜修改【最後1個欄位:H欄】的【標題】➜【顯著性(單尾)】 【複製G欄】,示意圖, 【成果】,示意圖, ※(10).在【H10】➜輸入【=G10/2】➜公式作用到【H10~H16】 ➜複製【H10~H16】➜【原地】➜選擇性貼上➜【值】 【先複製,再原地選擇性貼上:值】,示意圖, 【結果】,示意圖, ※(11).刪除【G欄】(顯著性(雙尾) 【結果】,示意圖, ※(12).在最後1個欄位【H欄位】➜輸入【<α】(判斷是否符合p<0.05) ➜在【H10】➜輸入【=IF(G10<0.05,"*", "")】➜公式套用到【H10~H16】 【公式套用到相關欄位,再原地選擇性貼上:值】,示意圖, ※(13).在【B17】➜輸入【樣本數】 ➜在【C17~E17】➜輸入【46,104,150】 ➜表格加上【內外框線】 
【下載Excel成果檔案】, ※(14).將表格複製貼到到【Word】➜寫成【分析報告】 【下載Word分析報告檔案】,
☎☎chp38-7.判定【東京的1月份均溫,在90年代前,和90年代後】,【是否存在差異】?
※下載調查數據excel:東京1月份歷史溫度
【3-9,成對樣本t檢定,配對樣本t檢定(彼此有相關的類別x vs 連續數值y)】:檢定2個獨立樣本(2個選擇的種類)的總體平均數,是否存在顯著差異? ☎chp39-1.【比較2廠牌輪胎的磨損,車子左邊用正欣輪胎,右邊用見大輪胎】,【正欣輪胎是否比見大磨損大】?
※下載調查數據csv:輪胎磨損數據
☎chp39-2.【無瞎米打字法,訓練10位同學,經過訓練後,能夠多進步40個字嗎】?
※下載調查數據csv:打字訓練前後數據
【3-10,單因子變異數分析,ANOVA】:檢驗多組(n>2)母體平均數是否相等(x類別>=3 vs 連續數值y) chp310-2.【大學生每月刷卡金額,是否與零用金來源不同而有所差異】?
※下載調查數據csv:每月刷卡金額
chp310-3.多種分析【大學生每月手機支出月費,與【男女性別】與否而有差異嗎?與【居住狀況】不同而有差異嗎?
※下載調查數據csv:手機平均月費
☎☎☎chp310-1.【在報紙投放不同方式的4種廣告,比較回應人數效果】,是否有差異?,哪一種效果比較好?(同時做差異檢定,高低檢定)
※下載調查數據csv:廣告效果數據
☎☎☎chp310-4.【實戰市場調查:洗髮精的競品調查】:消費者購買洗髮精【考慮的因素】會隨著【選擇品牌的不同】,而有顯著差異嗎?(1)
※
下載問卷調查數據sav(壓縮檔):消費者對於洗髮精選購的在意點調查
☎chp310-5.把上述【消費者對於洗面乳選購的檢定】➜寫成分析報告【SPSS➜Excel➜Word】(3)
※(1).【成果Demo】:把上述【消費者對於洗面乳選購的檢定】➜撰寫分析報告【SPSS➜Excel➜Word】(3)
※(2).先建立【觀測值摘要】 ➜【原因】:因為我們要排序,還要分組分群分析比較,所以首選【觀測值摘要】 ➜SPSS開啟上1個資料檔案➜在上方【分析】➜【報告】➜【觀測值摘要】 ➜設定【變數】➜【去頭皮屑,保濕,熱油護髮,止癢,香味,防止分岔,柔順,整體效果】 ➜設定【分組清單】➜【使用品牌】 ➜設定【統計資料】➜選【平均數】 ➜取消勾選【顯示觀察值】 設定參數,示意圖, 
※(3).將SPSS【觀察值摘要】表格【複製】到【Excel】 ➜在表格➜【滑鼠右鍵】➜【複製】 ➜貼到Excel去編輯每1個表格 ➜複製➜【A3:I10】 【貼表格到Excel編輯】,示意圖, ➜到新的工作表的【B1】➜【選擇性貼上/轉置(T)】 【選擇性貼上/轉置(T)】,示意圖, 
➜到【A1】➜輸入【編號】➜新增編號1,2,3,4....7 
※(4).【計算排名】 ➜到【J1】➜輸入【排名】 ➜到【J2】➜輸入公式【=RANK(I2, $I$2:$I$9)】 
➜到【B10】➜輸入【樣本數】 ➜到【C10:I10】➜輸入【22,14,22,10,20,36,124】 
※(5).到SPSS顯示【單因子變異數分析表格】 ➜在表格➜【滑鼠右鍵】➜【複製】 ➜貼到Excel➜【到新的工作表】➜到【B1】➜貼上 【貼表格到Excel,並刪除某些欄位列】,示意圖, ➜刪除【第C~F欄】 ➜刪除【第1列】 【刪除後】,示意圖, ➜在【A2:B2】輸入儲存格文字【編號,屬性】➜ ※(6).【刪除空白列】 選取【空白列】刪除,示意圖1, 【成果】,示意圖, ※(7).複製第3個工作表的【C:D 2個欄】到【第1個工作表『觀察值摘要』的最後2個欄位】 ➜修改【最後1個欄位:H欄】的【標題】➜【顯著性】 【成果】,示意圖, ※(8).在【M1】➜輸入【<α】(判斷是否符合p<0.05) ➜在【H10】➜輸入【=IF(L2<0.05, "*", "")】➜公式套用到【M2~M9】 【公式套用到相關欄位,再原地選擇性貼上:值】,示意圖, ※(9).表格加上【內外框線】 
【下載Excel成果檔案】, ※(14).將表格複製貼到到【Word】➜寫成【分析報告】 【下載Word分析報告檔案】, ☎☎☎chp310-6.【單因子變異數分析ANOVA高級篇】:A/B Testing
※【觀念】:六種檢定裡面,ANOVA變異數分析檢定是【最複雜,最困難,應用最廣】的
【3-11,相關性研究】:探討2個變數之間的相關性(2種方法:相關係數法,繪製散佈圖法) chp311-1.探討A公司的【投放的廣告費】與【銷售量】的【相關性】?
※下載問卷調查csv數據:廣告費與銷售量
chp311-2.用【散佈圖】來探討A公司的【投放的廣告費】與【銷售量】的【相關性】?
※下載調查數據csv:廣告費與銷售量
chp311-3.探討國中3甲班級的【國文成績】與【英文成績】的【相關性】?
※(1).【成果Demo】:探討國中3甲班級的【國文成績】與【英文成績】的【相關性】?
chp311-4.【多個變數之間的相關矩陣】:探討汽車【鈑金,省油,價格】3個變數的相關性?
※下載調查數據csv:汽車鈑金省油價格相關性
chp311-5.【多個變數之間的相關矩陣】:探討學生【成績,出席率,選修學分數,打工時數】4個變數的相關性?
※下載調查csv數據:成績,出席率,學分數,打工時數相關性
chp311-6.【偏相關(Partial,淨相關):多個變數之間排除其他條件的專門檢定2個變數】:探討汽車【鈑金,省油,價格】3個變數的相關性?
※下載調查csv數據:汽車鈑金省油價格相關性
chp311-7.【偏相關(Partial,淨相關):多個變數之間排除其他條件的專門檢定2個變數】:探討學生【平均成績 vs 打工時數】4個變數的2個變數的相關性?
※下載調查csv數據:成績,出席率,學分數,打工時數相關性
【3-12,迴歸分析】:探討依變數y與自變數x之間的迴歸方程式 chp312-1.探討A公司的【投放的廣告費】與【銷售量】的【線性迴歸方程式】?
※下載問卷csv數據:廣告費與銷售量
chp312-2.探討A銀行的【放款金額】與【存款餘額】的【線性迴歸方程式】?
※(1).【成果Demo】:
chp312-3.探討中古車行的【價格】與【車齡】的【線性迴歸方程式】?
※下載問卷調查csv數據:中古車車齡與車價
chp312-4.探討中古車行的【價格】與【車齡】的【線性迴歸方程式】並【繪圖】
※(1).【成果Demo】:
chp312-5.【非線性迴歸:二次曲線迴歸】探討【年齡】與【每月所得】的【非線性迴歸方程式】並【繪圖】
※下載問卷調查csv資料:年齡與所得
chp312-6.【非線性迴歸:對數曲線迴歸】探討樹木【直徑】與【高度】的【非線性迴歸方程式】並【繪圖】
※下載調查csv數據:樹木直徑與高度
※下載問卷調查csv數據:中古車車齡與車價
chp312-8.【複迴歸/多元迴歸】銀行幫客戶打【信用分數】,探討與客戶【總收入,不動產,動產,每月房貸,撫養支出】的【迴歸方程式】並【繪圖】
※(1).【成果Demo】:
chp312-9.【複迴歸/多元迴歸】老師要找出學生【出席率】低的原因,探討學生【是否點名,成績高低,上課內容,上課時段】的【迴歸方程式】並【繪圖】
※下載問卷調查csv數據:上課出席率
【四,實作:程式量化分析方法:Python統計分析(scipy統計模組)】 chp43.單變數anova檢定,單因子變異數分析(x類別>=3 vs 連續數值y) chp44.單變數pearson相關性檢定(連續數值x vs 連續數值y) chp46.多變數迴歸分析與檢定,(x1,x2,x3..連續數值 vs 數值y) 【五,實作:應用人工智慧於顧客區隔(Customer Segmentation)的分群預測,可找出不同的目標客群,然後做差異性行銷】 【5-1.三步驟的分類預測:Classification Prediction】 範例5-3.用sklearn模組,『簡易3步驟』建立『KNN,K鄰近』模型來預測『客戶關係管理裡面的客戶價值度』 範例5-4.用sklearn模組,『簡易3步驟』建立『邏輯迴歸』模型來預測『客戶關係管理裡面的客戶價值度』 範例5-7.用sklearn模組,『簡易3步驟』建立『支持向量機算法SVM』模型來預測『客戶關係管理裡面的客戶價值度』 【5-2.五步驟的分類預測:Classification Prediction】 範例6-3.用sklearn模組,『入門5步驟』建立『KNN,K鄰近』模型來預測『客戶關係管理裡面的客戶價值度』 範例6-4.用sklearn模組,『入門5步驟』建立『邏輯迴歸』模型來預測『客戶關係管理裡面的客戶價值度』 範例6-5.用sklearn模組,『入門6步驟』建立『決策樹tree』模型來預測『客戶關係管理裡面的客戶價值度』 【5-3.進階處理問題1:使用【標準化(Standardization)➜特徵縮放scaler】來處理輸入變數刻度差距很大,造成計算誤差與準確率低】 範例8-2.用標準化類別函數StandardScaler(),把『客戶關係管理的客戶價值度RFM資料集』先標準化處理,再用『sklearn邏輯迴歸模型』預測分類 範例8-3.用標準化類別函數StandardScaler(),把『客戶關係管理的客戶價值度RFM資料集』先標準化處理,再用『keras類神經網絡模型』預測分類 【5-4.進階處理問題2:使用【管道器封裝中間的全部流程:(x➜【管道器pipeline】➜y】來處理『數據要經過多種預處理所造成的繁雜易出錯』】 範例9-3.用『管道器pipeline』封裝『keras類神經網絡模型』,處理『客戶關係管理的客戶價值度RFM資料』並預測分類 範例10-5.用『管道器pipeline』封裝『sklearn的5種模型』,處理『IBM電信的客戶流失率資料集』並預測A客戶是否會流失 範例10-6.用『管道器pipeline』封裝『sklearn的5種模型』,處理『歐洲信用卡公司盜刷資料集』並預測A客戶是否會盜刷 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


 ,
,










































































































































| 資源 | |||||
| 上課工具 | 線上黑板( Online blackboard) | 廣播教學 | 上課錄影影片 | Goole輸入法(Input:exe) | teams遠距上課-北科大使用方法 |
| 證照考試:商用數據應用師 | 考試題庫 (從中約抽70題) | 報名證照相關說明與方法 | 考試方式:100題單選題,每題1分,70分及格 | 考試指定用書 | |
| 數據集,資料集,dataset | UCI的各種資料集 | Kaggle的各種資料集 | 考試方式:100題單選題,每題1分,70分及格 | 考試指定用書 | |
| 上課參考教材 | 書籍:跨領域學 Python:資料科學基礎養成 | 書籍:Python 資料科學與人工智慧應用實務 | 書籍:一行指令學Python:用機器學習掌握人工智慧 | ||
| 書籍:用Pandas掌握商務大數據分析 | 進階書籍:Python商業數據分析:零售和電子商務案例 | pandas官網(英文) | w3schools的pandas教學(英文) | ||
| pandas參考教材 | w3Cschool的pandas教學(中文) | Steam教學網-python | 蓋若pandas 教程 | pandas的df的操作函數 | |
| colab繪圖如何顯示中文,方法1 |
☎#colab顯示繁體中文,方法1
問題:matplotlib繪圖,會發生中文無法顯示的問題 參考:colab繪圖如何顯示中文 ☎程式碼: #-------------------------------- # colab繪圖顯示繁體中文 #-------------------------------- import matplotlib # 先下載台北黑體字型 !wget -O taipei_sans_tc_beta.ttf https://drive.google.com/uc?id=1eGAsTN1HBpJAkeVM57_C7ccp7hbgSz3_&export=download import matplotlib # 新增字體 matplotlib.font_manager.fontManager.addfont('taipei_sans_tc_beta.ttf') # 將 font-family 設為 Taipei Sans TC Beta # 設定完後,之後的圖表都可以顯示中文了 matplotlib.rc('font', family='Taipei Sans TC Beta') |
||||
| colab繪圖如何顯示中文,方法2 |
☎#colab顯示繁體中文,方法2
☎程式碼: #-------------------------------------- # 課本的中文處理 #-------------------------------------- import matplotlib as mpl import matplotlib.font_manager as fm !wget "https://www.wfonts.com/download/data/2014/06/01/simhei/simhei.zip" !unzip "simhei.zip" !rm "simhei.zip" fm.fontManager.addfont('SimHei.ttf') mpl.rc('font', family='SimHei') # 這一行能讓字體變得清晰 %config InlineBackend.figure_format = 'retina' |
||||
| windows的spyder繪圖如何顯示中文 |
☎解決:windows的spyder,會發生中文無法顯示的問題 參考:windows繪圖如何顯示中文 ☎程式碼: #在windows 10 的spyder,繪圖如何顯示中文 #使用微軟正黑體(Microsoft JhengHei) plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei'] #有些中文字體在碰到負號時,會無法正常顯示,尤其是內建的字體,加入以下語法就可以解決『負號無法顯示』問題 plt.rcParams['axes.unicode_minus'] = False |
||||
| 在colab如何更改目錄 |
☎解決:在colab如何更改目錄的問題 ☎程式碼: import os os.chdir("/content/drive/MyDrive/Colab Notebooks") !ls |
||||
| 解決簡體字csv造成亂碼 |
☎解決簡體字csv,打開後都是亂碼的問題: 第2 種方式: (1)先執行Excel 軟體,新增空白活頁簿, (2)然後在上方功能選項中點選「資料」➜「取得外部資料」➜ 「從文字檔」 → 「選擇csv文件」, 選擇你的CSV 檔, 在「匯入字串精靈」對話框中選擇檔案原始格式65001:Unicode(UTF-8) 即可。 若是utf-8還是有亂碼,再改成 在「匯入字串精靈」對話框中選擇檔案原始格式54986:簡體中文(GB18080) 即可。 (3)打勾:我的資料有標題 (4)分隔符哈:逗號 |
||||
| 程式模板 |
☎存入excel檔案,並且畫柱狀圖
|
||||
| 程式模板chp8-6.樞紐分析表的必要指令:展開 |
☎輸出excel檔案:建立3個資料表sheet(英文成績,數學成績,中文成績)
|
||||
| 打開chrome網頁線上英文字典功能 |
☎如何安裝google chrome的網頁線上英文字典工具: ➜google chrome的右上角工具➜更多工具➜擴充功能 ➜左上角主選單➜開啟chrome線上應用程式商店 ➜勾選:google製作,免費 ➜搜尋:google dictionary➜安裝 ➜到chrome右上擴充功能➜點按google dictionary的『詳細資料』➜擴充功能選項 ➜my language=chinese ➜打勾2個:Pop-up definitions: (1)反白單字翻譯:Display pop-up when I double-click a word (2)ctrl+拖曵整段翻譯: Display pop-up when I select a word or phrase |
||||
| 上課用excel | 學生成績-chinese | 學生成績-有缺值-chinese | 學生成績-物理歷史-chinese | 學生成績-amy-simon-chinese | |
| 學生成績-生日-chinese | 學生成績-分組-chinese | 人事資料-chinese | 男女時薪-chinese | ||
| 學生成績-english | 學生成績-有缺值-english | 學生成績-分組-english | 圖書資料-chinese | ||
| 上課用csv | 小費tips-chinese | 小費tips-english | 學生成績-chinese | 學生成績-english | |
| 圖書資料-chinese | |||||
| 上課用其它資料庫 | mySQL-ch09 | SQLite-student | json-學生成績 | xml-personnel | |
| 課本商業範例資料庫 | 商業銷售分析-sales csv | 系所生源分析-excel | 股市分析-台積電聯發科股票線型-excel | 問卷資料分析-excel | |
| pandas參考教材 | 十分鐘入門 Pandas(英文) | 十分鐘入門 Pandas(英文) | 10分鐘的Pandas入門-繁中版 | 十分鐘入門 Pandas(中文) | |
| pandas參考教材 | pandas官網全部章節翻譯 | pandas官網全部章節翻譯 | |||
| pandas參考教材(英文) | kaggle pandas教學 | 100 pandas tricks to save you time and energy | 官網0.22.0:pandas documentation | ||
| pandas參考教材(中文) | Pandas 101:資料分析的基石 | 資料科學家的pandas 實戰手冊:掌握40 個實用 | 簡明 Python Pandas 入門教學 | 資料分析必懂的Pandas DataFrame處理雙維度資料方法 | |
| pandas速查手冊 | pandas 速查手册 - 盖若 | Pandas速查手冊中文版 - 知乎專欄 | Pandas速查手冊中文版- 騰訊雲開發者社區 | ||
| pandas速查手冊 | Pandas中DataFrame基本函數整理(全) | Pandas 魔法筆記(1)-常用招式總覽 | pandas的df的操作函數 | ||
| 資料集dataset | 小費資料集Tips Dataset(csv) | kaggle小費資料集範例A Waiter's Tips example | 【視覺化】小費(tips)資料集分析 | 小費(tips)資料集提取和檢視相應資料 | |
| SQL語法 | SQL語法教程 | pandas vs SQL | |||
| 資料分析4大模組(runoob) | numpy | pandas | matplotlib | scipy | |
| w3c、w3school、w3cschool、runoob、w3capi比較 | runoob流量監控儀表板 | ||||
| w3school vs runoob |
1.w3school中文版是直接google翻譯英文版 2.runoob.com翻譯自英文版w3schools,但重新排版 3.runoob = run + noob(菜鳥,小白) 4.runoob是python,html,javascript中文版最好的教學網 |
||||
| 官網 | python官網 | vscode官網 | |||
| python 教學網站 | python 3(官網手冊中文) | python 3教學(中文) | python 3教學(中文) | 簡易1小時教學 | |
| w3school(英文版) | |||||
| 線上執行python online |
https://www.python.org/shell/(建議用這個) https://repl.it/languages/python3 |
||||
| 用Anacond寫python(*建議使用) | |||||
| 作業(homework) | |||||
| 作業1 | |||||
| 作業2 | |||||
| 作業3 | |||||
| side project | 期末作業 (side project) |
1.題目:你是A公司的新進行銷人員,請你使用SPSS的量化分析技術,表現出你有精準制定決策的能力
2.目的:用SPSS量化分析技術、做精準市場調查分析、精準產品定位、精準競爭品牌分析、精準行銷、精準客戶服務,達成數據驅動輔助決策(DDDM)的制定。 3.數據集種類:商業交易數據、公司內部數據、行銷活動問卷調查數據、學生學習問卷數據、學生體能調查數據,咖啡飲料市場調查數據、 最後請寫出分析報告。請多用定量描述的方式,來證明你分析觀點的可靠性、準確性與權威性,以建立個人數據分析的品牌與形象。 4.分析題目:共9題 第1題:咖啡飲料市場的市場調查,與前二競爭對手品牌調查 第2題:量化分析【工作效率】與【工作年資,每日開會時數】的迴歸方程式 第3題:量化分析【學習時數、社交活動時間、線上課程參與次數】對【考試成績】的相關係數 第4題:量化分析與DDDM應用在Netflix影片平台的差異性行銷與目標客戶的選定 第5題:行銷活動問卷,不同男女客戶的體驗行銷度分析 第6題:行銷活動問卷,不同教育程度客戶的滿意度分析 第7題:行銷活動問卷,探討『服務品質』對『滿意度』的關聯影響 第8題:行銷活動問卷,探討『性別』對『已婚否』的關聯影響 第9題:同學結果訓練四周後,探討柔韌性是否有改善分析 |
|||