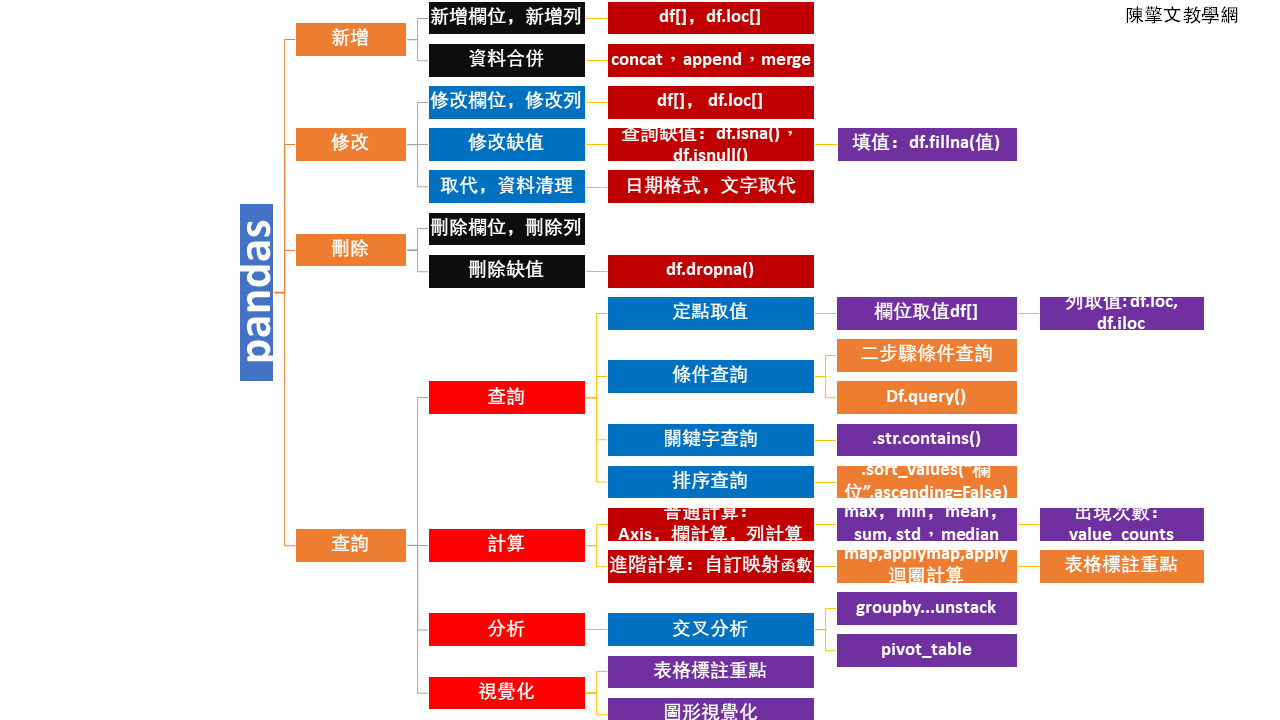
| 資源 | |||||
| 線上黑板( Online blackboard) | 廣播教學 | Zuvio | Goole輸入法(Input:exe) | ||
| 上課參考教材 | 書籍:用Pandas掌握商務大數據分析 | 進階書籍:Python商業數據分析:零售和電子商務案例 | pandas官網(英文) | w3schools的pandas教學(英文) | |
| pandas參考教材 | w3Cschool的pandas教學(中文) | Steam教學網-python | 蓋若pandas 教程 | pandas的df的操作函數 | |
| colab繪圖如何顯示中文,方法1 |
☎#colab顯示繁體中文,方法1
問題:matplotlib繪圖,會發生中文無法顯示的問題 參考:colab繪圖如何顯示中文 ☎程式碼: #-------------------------------- # colab繪圖顯示繁體中文 #-------------------------------- import matplotlib # 先下載台北黑體字型 !wget -O taipei_sans_tc_beta.ttf https://drive.google.com/uc?id=1eGAsTN1HBpJAkeVM57_C7ccp7hbgSz3_&export=download import matplotlib # 新增字體 matplotlib.font_manager.fontManager.addfont('taipei_sans_tc_beta.ttf') # 將 font-family 設為 Taipei Sans TC Beta # 設定完後,之後的圖表都可以顯示中文了 matplotlib.rc('font', family='Taipei Sans TC Beta') |
||||
| colab繪圖如何顯示中文,方法2 |
☎#colab顯示繁體中文,方法2
☎程式碼: #-------------------------------------- # 課本的中文處理 #-------------------------------------- import matplotlib as mpl import matplotlib.font_manager as fm !wget "https://www.wfonts.com/download/data/2014/06/01/simhei/simhei.zip" !unzip "simhei.zip" !rm "simhei.zip" fm.fontManager.addfont('SimHei.ttf') mpl.rc('font', family='SimHei') # 這一行能讓字體變得清晰 %config InlineBackend.figure_format = 'retina' |
||||
| windows的spyder繪圖如何顯示中文 |
☎解決:windows的spyder,會發生中文無法顯示的問題 參考:windows繪圖如何顯示中文 ☎程式碼: #在windows 10 的spyder,繪圖如何顯示中文 #使用微軟正黑體(Microsoft JhengHei) plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei'] #有些中文字體在碰到負號時,會無法正常顯示,尤其是內建的字體,加入以下語法就可以解決『負號無法顯示』問題 plt.rcParams['axes.unicode_minus'] = False |
||||
| 在colab如何更改目錄 |
☎解決:在colab如何更改目錄的問題 ☎程式碼: import os os.chdir("/content/drive/MyDrive/Colab Notebooks") !ls |
||||
| 解決簡體字csv造成亂碼 |
☎解決簡體字csv,打開後都是亂碼的問題: 第2 種方式: (1)先執行Excel 軟體,新增空白活頁簿, (2)然後在上方功能選項中點選「資料」➜「取得外部資料」➜ 「從文字檔」 → 「選擇csv文件」, 選擇你的CSV 檔, 在「匯入字串精靈」對話框中選擇檔案原始格式65001:Unicode(UTF-8) 即可。 若是utf-8還是有亂碼,再改成 在「匯入字串精靈」對話框中選擇檔案原始格式54986:簡體中文(GB18080) 即可。 (3)打勾:我的資料有標題 (4)分隔符哈:逗號 |
||||
| 程式模板 |
☎存入excel檔案,並且畫柱狀圖
|
||||
| 程式模板chp8-6.樞紐分析表的必要指令:展開 |
☎輸出excel檔案:建立3個資料表sheet(英文成績,數學成績,中文成績)
|
||||
| 打開chrome網頁線上英文字典功能 |
☎如何安裝google chrome的網頁線上英文字典工具: ➜google chrome的右上角工具➜更多工具➜擴充功能 ➜左上角主選單➜開啟chrome線上應用程式商店 ➜勾選:google製作,免費 ➜搜尋:google dictionary➜安裝 ➜到chrome右上擴充功能➜點按google dictionary的『詳細資料』➜擴充功能選項 ➜my language=chinese ➜打勾2個:Pop-up definitions: (1)反白單字翻譯:Display pop-up when I double-click a word (2)ctrl+拖曵整段翻譯: Display pop-up when I select a word or phrase |
||||
| 上課用excel | 學生成績-chinese | 學生成績-有缺值-chinese | 學生成績-物理歷史-chinese | 學生成績-amy-simon-chinese | |
| 學生成績-生日-chinese | 學生成績-分組-chinese | 人事資料-chinese | 男女時薪-chinese | ||
| 學生成績-english | 學生成績-有缺值-english | 學生成績-分組-english | 圖書資料-chinese | ||
| 上課用csv | 小費tips-chinese | 小費tips-english | 學生成績-chinese | 學生成績-english | |
| 圖書資料-chinese | |||||
| 上課用其它資料庫 | mySQL-ch09 | SQLite-student | json-學生成績 | xml-personnel | |
| 課本商業範例資料庫 | 商業銷售分析-sales csv | 系所生源分析-excel | 股市分析-台積電聯發科股票線型-excel | 問卷資料分析-excel | |
| 進階課本資料庫(零售電子商務) | 淘寶電商的營業數據-csv | 3年驅蟲劑市場數據 | 3年滅鼠殺蟲劑細分市場數據 | 淘寶服飾店的流量數據-excel | |
| 進階課本資料庫(零售電子商務) | 對手的單品SKU價格-excel | 對手的單品價格-excel | |||
| 資料集dataset | 小費資料集Tips Dataset(csv) | kaggle小費資料集範例A Waiter's Tips example | 【視覺化】小費(tips)資料集分析 | 小費(tips)資料集提取和檢視相應資料 | |
| 資料集dataset | 中山管院-公開資料集資源連結 | 台南市資料集 | |||
| 如何準備應徵的CV履歷 | 可操作性超強的CV包裝,跨專業新手也能寫出資料分析經驗 | 一份令人心動的【學術簡歷】| An Excellent Academic CV | 怎麼寫簡歷才能不被篩選軟體淘汰掉 | ||
| pandas參考教材 | 十分鐘入門 Pandas(英文) | 十分鐘入門 Pandas(英文) | 10分鐘的Pandas入門-繁中版 | 十分鐘入門 Pandas(中文) | |
| pandas參考教材 | pandas官網全部章節翻譯 | pandas官網全部章節翻譯 | |||
| pandas參考教材(英文) | kaggle pandas教學 | 100 pandas tricks to save you time and energy | 官網0.22.0:pandas documentation | ||
| pandas參考教材(中文) | Pandas 101:資料分析的基石 | 資料科學家的pandas 實戰手冊:掌握40 個實用 | 簡明 Python Pandas 入門教學 | 資料分析必懂的Pandas DataFrame處理雙維度資料方法 | |
| pandas速查手冊 | pandas 速查手册 - 盖若 | Pandas速查手冊中文版 - 知乎專欄 | Pandas速查手冊中文版- 騰訊雲開發者社區 | ||
| pandas速查手冊 | Pandas中DataFrame基本函數整理(全) | Pandas 魔法筆記(1)-常用招式總覽 | pandas的df的操作函數 | ||
| SQL語法 | SQL語法教程 | pandas vs SQL | |||
| 資料分析4大模組(runoob) | numpy | pandas | matplotlib | scipy | |
| w3c、w3school、w3cschool、runoob、w3capi比較 | runoob流量監控儀表板 | ||||
| w3school vs runoob |
1.w3school中文版是直接google翻譯英文版 2.runoob.com翻譯自英文版w3schools,但重新排版 3.runoob = run + noob(菜鳥,小白) 4.runoob是python,html,javascript中文版最好的教學網 |
||||
| 官網 | python官網 | vscode官網 | |||
| python 教學網站 | python 3(官網手冊中文) | python 3教學(中文) | python 3教學(中文) | 簡易1小時教學 | |
| w3school(英文版) | |||||
| 線上執行python online |
https://www.python.org/shell/(建議用這個) https://repl.it/languages/python3 |
||||
| 用Anacond寫python(*建議使用) | |||||
| 作業(homework) | |||||
| 作業1 | 圖1 | 圖2 | 圖3 | ||
| 作業2 | |||||
| 作業3 | |||||
| 作業4 | |||||
| side project 1 |
第一個side project(可以放到你的履歷當做作品集) 題目: 這個是委託案,來自某私校大學系主任,因為招生日益困難,因而委託你:做學生來源落點的分析專案, 請你從各種角度來分析客戶群的潛在落點所在,探討逐年變化,並分析過去歷史的強項所在與弱項所在, 最後,請你寫個簡單的結案摘要,告訴業主,該如何做,才能改善招生率 |
||||
| side project 2 |
第二個side project(可以放到你的履歷當做作品集) 題目: 你是A公司的新進商業數據分析師,A公司今年2016年業績大幅下滑,公司想請你分析歷年數據後,寫份摘要報告,從各種不同角度分析,包括:『不同業務單位、不同業務員、不同產品、逐年、每季、每月』的分析,找出業績下降的原因,以及如何改善。 請多用定量描述的方式,來證明你分析觀點的可靠性、準確性與權威性,以建立個人數據分析的品牌與形象。 |
||||
| chp0.前言,與什麼是大數據 | |||||
| 1.課程簡介投影片 | 2.學習程式的4種方法 | ||||
| 1.現今企業的數據有哪些 | 2.運用數據三階段 | 3.資料生產的四步驟 | 3.資料最基本的三個概念 | ||
| 5.什麼是大數據Big Data | 6.大數據分析與傳統商業分析的差異 | 7.大數據的分析步驟 | 8.視覺化常用工具 | ||
| 9.什麼是大數據Big Data | 10.大數據分析與傳統商業分析的差異 | 11.大數據的分析步驟 | 12.大數據的類型:結構化、非結構化、半結構化資料 | ||
1.現今企業的數據有哪些 |
1.現今企業的數據有哪些: (1)所謂大數據,即是透過不同來源、渠道取得的海量數據資料, 現今企業如果想做數據蒐集的方法變得非常多元,包括: (2)來自用戶的第一方數據: ☎傳統的用戶資料建檔、問卷調查, ☎網頁的瀏覽行為等數據的追蹤, ☎App應用程式的瀏覽行為等數據的追蹤、 ☎物聯網IoT設備傳遞的數據等, 這些都是可以蒐集到。 還有更多可捕捉用戶站外資訊的非第一方數據也漸漸被重視, (3)透過交換共享得到的第二方數據: ☎第二方數據 (也稱為第二方或 2P 數據):是另一個同行公司收集的數據,但可由另一家公司通過購買或協作訪問。 ☎營銷人員在希望擴展其營銷資料庫以吸引新的潛在客戶時,通常會購買它。 ☎例如,如果一個為女性製作的服裝品牌決定增加一個男裝系列,並且需要相關的目標來行銷,就可以向外同行公司購買男裝的數據資料庫。 (4)任何與商業需求有關的第三方數據: ☎第三方數據 (也稱為第三方或3P數據):是來自第三方的數據,該第三方已聚合了多個數據源並使其可供購買。 ☎第三方數據的缺點:是它可能缺乏準確性和品質,因此重要的是了解數據來自何處以及數據使用年限. (5)比較:第一方、第二方和第三方數據之間的差別: 第一方、第二方和第三方數據之間的主要區別在於:『來源』。 ☎第一方數據:由其『存儲/擁有的公司』收集。 ☎第二方數據:由『同行公司』收集,並由另一家公司購買(或通過合作協定與他們共用)。 ☎第三方數據:是從『多個未知來源』收集的,並由一家公司購買。 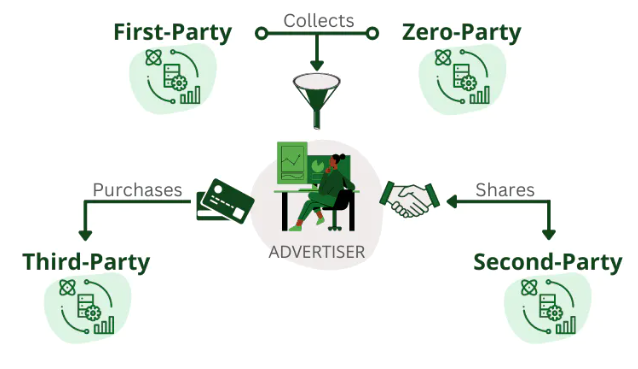 (6)參考文獻: 1.第一方、第二方、第三方和零數據對廣告商意味著什麼 2.分析大數據在各領域的應用 |
||||
2.運用數據三階段 |
1.市場上的數據需求,主要分為四個階段: ☎數據蒐集、 ☎數據分析、 ☎數據應用 (1)數據蒐集:蒐集第一方、第二方和第三方數據 ☎傳統的用戶資料建檔、問卷調查, ☎網頁的瀏覽行為等數據的追蹤, ☎App應用程式的瀏覽行為等數據的追蹤、 ☎物聯網IoT設備傳遞的數據等, ☎第二方數據:向同行公司購買數據。 ☎第三方數據:向『其他管道,如:數據收集公司』購買。 (2)數據分析:原始數據(raw data)要先處理過 ☎透過多元渠道獲取大量數據資料往往是原始數據(raw data),無法直接使用, ☎必須經過一層又一層的處理過程 ☎處理方法1:數據檢查(data inspecting) ☎處理方法2:數據清理(data cleansing) ☎處理方法3:數據轉換(data transforming) (2-1)處理方法2:數據清理(data cleansing) A.資料清理是資料前處理的第一步,需要先將資料中的問題處理。 B.收載資料時一定會遇到各式髒資料,有的資料樣態會導致無法轉入資料庫,而有的資料會在塞入資料庫時,出現錯位、亂碼等各式各樣非預期的情況,此時倉儲資料清理的準則變得極為重要,因將攸關於整個系統資料的統一。 C.資料清理的準則設定可以從三個角度著手: ☎「檔案類型」問題的清理 ☎「欄位型態」問題的清理 ☎「資料邏輯」問題的清理 D.☎數據清洗:按照一定的規則剔除或者填充不滿足實際需要的業務資料。 E.☎清洗主要包括三部分的內容: 第一部分是測試資料、 第二個是錯誤的資料, 第三個是缺失的資料。 錯誤的資料我們可以關注:『資料是否重複』、格式是否『錯誤、欄位描述』的資訊是否錯誤。 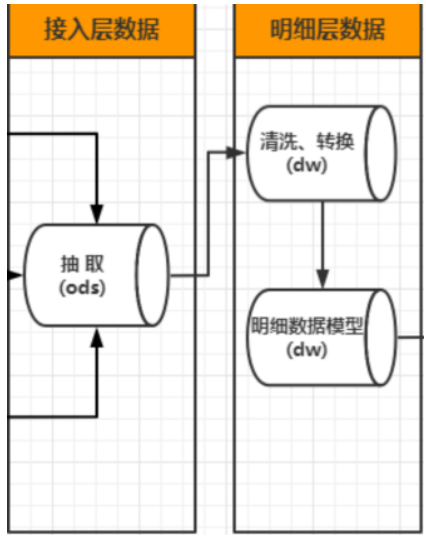 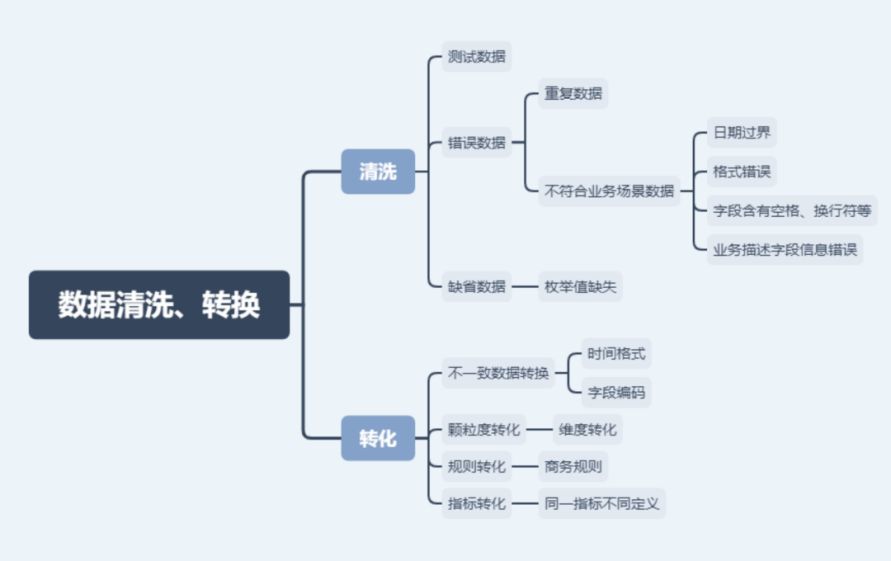 D.(2-1-a)例如:資料來源檔案類型:純文字檔 ☎資料內容以純文字的方式儲存的特色: 欄位與欄位之間以特定符號作為分隔, 例如:逗號、分號或|等等, ☎較常被使用的是「逗號」 ☎可能發生的問題: 然而使用各符號作為分隔時,會遇到其中一種情況是:以逗號為例,如該欄位內容包含逗號,將會造成欄位內容分割時發生錯誤,但此逗號明明屬於資料的內容,卻被誤認為是分隔符號,使得分割完的資料對應到錯誤的欄位 ☎解決的辦法: 將內容值前後都加上雙引號後,再以逗號分隔串連各欄位資料 D.(2-1-a)例如:檔案類型:資料庫 ☎讀取資料庫文字欄位型態的資料時,內容包含換行符號,系統就認為這筆資料已經讀取完,則換行符號後面的資料內容即為下一筆資料的開頭,無法完整的將一筆資料讀取進來。 ☎解決辦法:是移除換行符號,若需要保留換行符號, D.(2-1-b)例如:欄位型態:日期 ☎格式:同時出現以 斜線分隔(YYYY/MM/DD)、無分隔符號(YYYYMMDD) 或 連接號(YYYY-MM-DD) 的日期格式。 ☎處理方式:透過判斷式將內容使用的符號,或沒有符號的純文字格式,換成資料庫可接受的日期格式。 ☎西元年/民國年:同一欄位參雜西元年與民國年的日期。 ☎處理方式:若以西元年格式存入資料庫,年若小於1911,則將 年份+1911 ;年若大於1911,則直接轉入。 ☎值異常:例如日期出現2月30日、年份早於1911年等,或是不可為NULL的欄位卻出現NULL值等非正常的日期。 ☎處理方式:異常的日期通常已經無法追溯到正確的值,或來源的日期就是髒資料,可統一為特定日期(如:1911年1月1日),日後看到即可確定來源的資料因有異常而清理過。 D.(2-1-b)例如:欄位型態:特殊字元 ☎說明:文字是最容易造成轉檔失敗的型態,因為此型態可容許輸入任何類型的字元,例如:特殊字元,但資料庫本身並非接納的了所有字元,較特別的會無法轉入,或需要做其他特殊的轉換才能收載。 ☎處理方式:必須找出那一筆,替換掉『特殊字元』後,再登錄進資料庫。 D.(2-1-c)例如:資料邏輯:縣市代碼 ☎台灣曾經經歷過縣市升格為直轄市,有更換過縣市的中文名稱,那麼資料也須跟著配合調整。 ☎處理方式:是做一張新舊對照縣市代碼與名稱的轉換表,日後資料若有縣市資訊需求,即可勾稽此資料表,讓縣市升格前與後的資料,能自由並適當的轉換,得到想要的資訊。 D.(2-1-c)例如:資料邏輯:身分證號的規則判斷 ☎身分證號的編碼有固定的規則, 第一碼是初次戶籍所在的縣市代碼, 第二碼是性別(1:男性;2:女性), 第三到九碼是流水碼, 最後一碼第十碼是檢查碼,檢查碼會以第一到第九碼之英數字組合經過權重計算而得。 ☎若要確認身分證是否有效,可依據這些規則去做判斷。 (2-3)處理方法3:數據轉換(data transforming) A.☎數據轉化:按照一定的規則、技術手段轉化不同格式,或者顆粒度不同的資料。 B.(1)例如:格式的轉換,比如說時間格式,在不同的業務系統可能會有不同的時間格式,但是到我們大資料系統,為了方便下游資料的使用,我們會統一轉換成一種資料格式。包括一些欄位編碼也是這樣。 C.(2)資料顆粒度的轉換:我們在DW層的資料明細層到資料應用層的整個過程,都是顆粒度不斷轉化的一個過程。還包括一些業務規則、商務規則和一些指標。 ☎補充:數據顆粒度:資料顆粒度指數據的細緻程度。 資料顆粒度越高,細緻程度越高,意味著可以進行更準確的分析。 然而,需要指出的是,資料顆粒度直接決定資料庫需要的儲存空間。 高顆粒度的資料需要更多儲存空間;如果資料顆粒度太高,能夠識別出背後的資料,隱私相關挑戰也會加大。 (4)參考文獻: 1.資料指標體系(1)如何理解資料顆粒度、維度以及指標 |
||||
3.資料生產的四步驟 |
1.資料生產的四步驟: • 資料指標體系搭建 • 資料獲取 • 資料存儲 • 數據清洗 2.建立資料後,即可開始資料分析 |
||||
4.資料最基本的三個概念 |
1.資料最基本的三個概念: ☎顆粒度 ☎維度 ☎指標 (1)顆粒度 ☎資料的顆粒度是指數據的 “粗細”,也就是我們看資料的視野的大小,或者說格局的大小。 ☎例如: 一個電商公司,同樣是看GMV(總銷售額),CEO關注的可能是『今年總的GMV』是多少, 而業務老闆關注的可能是『每月的GMV』如何, 具體到某個小團隊,關注的點可能就是某些商品,『每天的GMV』如何了。 ☎資料顆粒度最常見的劃分是:時間 (2)維度 ☎資料的維度:是指看待事物不同的角度。 ☎是從不同角度來看一件事,會得到不同的結論。 ☎在做資料分析時也是一樣的。分析一個活動,或者一個策略對用戶的吸引時,如果我們以『新增用戶數』作為分析的指標(也就是展開方式,分析點), ☎可以列為『維度』進行拆分的項目: • 時間維度:拆分為早晨、中午、晚上 • 性別維度:男性、女性、未知 • 受教育程度:小學、中學、大學、研究生、博士 ☎通過維度的分解,我們可以看到每個部分的變動,和整體的變化趨勢是否相同,是否存在不同,而哪些不同點往往會成為我們接下來分析的重點。 ☎顆粒度和維度的『相似性』:例如“時間”這個要素,在兩個部分都出現了 ☎顆粒度和維度的『差異性』:不同在於拆分的方式不同 • 顆粒度:是一種縱向的聚合,類似於金字塔的形狀,不同的顆粒度都代表著不同的聚合程度 • 維度:是一種橫向拆分的模式。類似于把鏡子打碎成不同的部分,每個部分都是獨立的,把所有部分合在一起又能拼成完整的整體 (2-1)指標 ☎資料指標:是衡量事物發展方式及程度的一種單位或者方法,一般通過對原始資料進行加減乘除等操作生成得到。 ☎例如:長度,是把所有部分加在一起得到的一種衡量外在大小的單位。 ☎列舉一些常見網路流量的資料指標: • DAU(daily active user):每天,“活躍”過的用戶數的加總,count(distinct user_id) group by day • MAU(monthly active user):每個月,“活躍”過的用戶的加總,count(distinct user_id) group by month • 留存率(次日、7日、30日):今天“活躍”過的用戶的總量,一段時間後的某個時間點,還活躍的比例 • 轉化率:兩個有遞進的環節之間,從上層到下層用戶轉化的比例,例如:CTR=實際點擊次數/展示量 (4)參考文獻: 1.大數據前的資料清理 2.分析大數據在各領域的應用 |
||||
5.什麼是大數據Big Data |
1.為什麼有大數據的問題 現在的企業資料,因為以下的興起,造成大量數據的需求: ☎網路網路資料(社交網站,交易資料) ☎物聯網IoT, Internet of Things ☎感測器sensor 2.大資料的來源 資料來源主要分為以下三類: (1)社交數據: ☎顧名思義,社交資料來源於社交媒體評論、發帖、圖片以及與日俱增的視頻檔。隨著全球 4G 和 5G 蜂窩網路的普及,到 2023 年,全球手機視頻使用者將增至 27.2 億。 ☎雖然社交媒體及其使用趨勢瞬息萬變、難以預測,但作為數位資料的主要來源,其穩定增長趨勢是不會改變的。 (2)機器數據: ☎物聯網設備和機器都配有感測器,能夠發送和接收數位資料。物聯網感測器能夠幫助企業採集和處理來自整個企業的設備、工具和裝置的機器資料。 ☎從天氣和交通感測器到安全監控,全球範圍內的資料生成設備正在迅速增多。 ☎據 IDC 估計,到 2025 年,全球物聯網設備數量將超過 400 億,生成的資料量幾乎占全球數位資料總量的一半。 (3)交易資料: ☎交易資料是世界上發展速度和增長速度最快的資料。 ☎例如,一家大型國際零售商每小時處理超過 100 萬筆客戶交易,全球那麼多採購和銀行交易,生成的資料量會有多麼驚人。 ☎此外,交易資料越來越多地由『半結構化』資料組成,包括圖片和注釋等,使得管理和處理難度不斷增加。  3.大數據的五大特性: (1)大數據的3V特性: ☎資料量(Volume) ☎資料類型(Variety)。 ☎資料傳輸速度(Velocity) 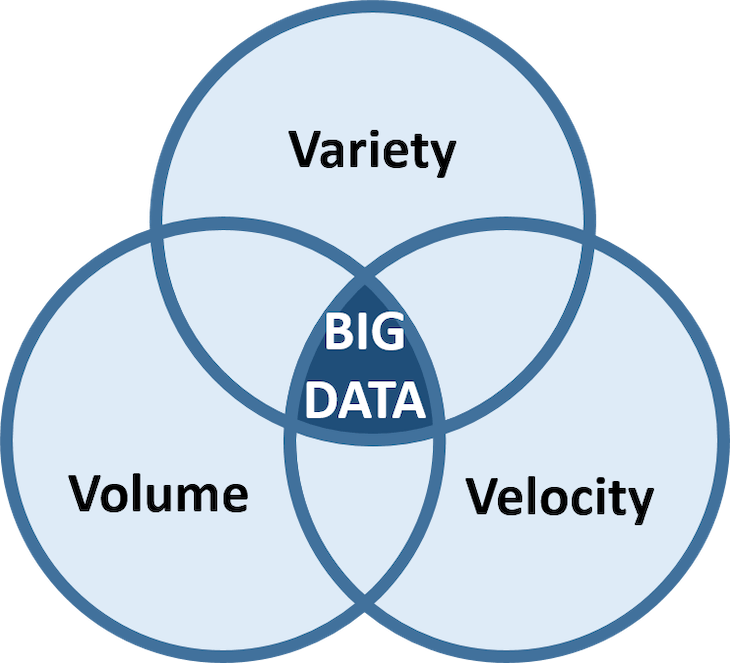 ☎Volume(資料量) 無論是天文學、生物醫療、金融、聯網物間連線、社群互動…每分每秒都正在生成龐大的數據量,如同上述所說的 TB、PB、EB 規模單位。 ☎Variety(資料多元性) 真正困難的問題在於分析多樣化的資料:從文字、位置、語音、影像、圖片、交易數據、類比訊號… 等結構化與非結構化包羅萬象的資料,彼此間能進行交互分析、尋找數據間的關聯性。 ☎Velocity(資料即時性) 大數據亦強調資料的時效性。隨著使用者每秒都在產生大量的數據回饋,過去三五年的資料已毫無用處。 一旦資料串流到運算伺服器,企業便須立即進行分析、即時得到結果並立即做出反應修正,才能發揮資料的最大價值。 (2)大數據的4V特性: ☎資料量(Volume) ☎資料類型(Variety) ☎資料傳輸速度(Velocity) ☎資料真實性(Veracity) 在3V成為大數據的主要定義後,隨著儲存資料的成本下降、取得成本也下降,大數據發展出第四個特性:Veracity,意旨除了資料量,也需要確認資料的真實性,過濾掉造假的數據與異常值後,分析出來的結果才能達到準確預測的目的。 (3)大數據的5V特性: ☎資料量(Volume) ☎資料類型(Variety) ☎資料傳輸速度(Velocity) ☎資料真實性(Veracity) ☎價值(Value) 大量、快速取得,來源多樣的資料,經過真實性考驗之後,擁有一定的價值,是大數據的核心架構 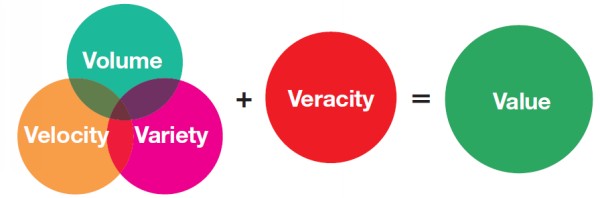 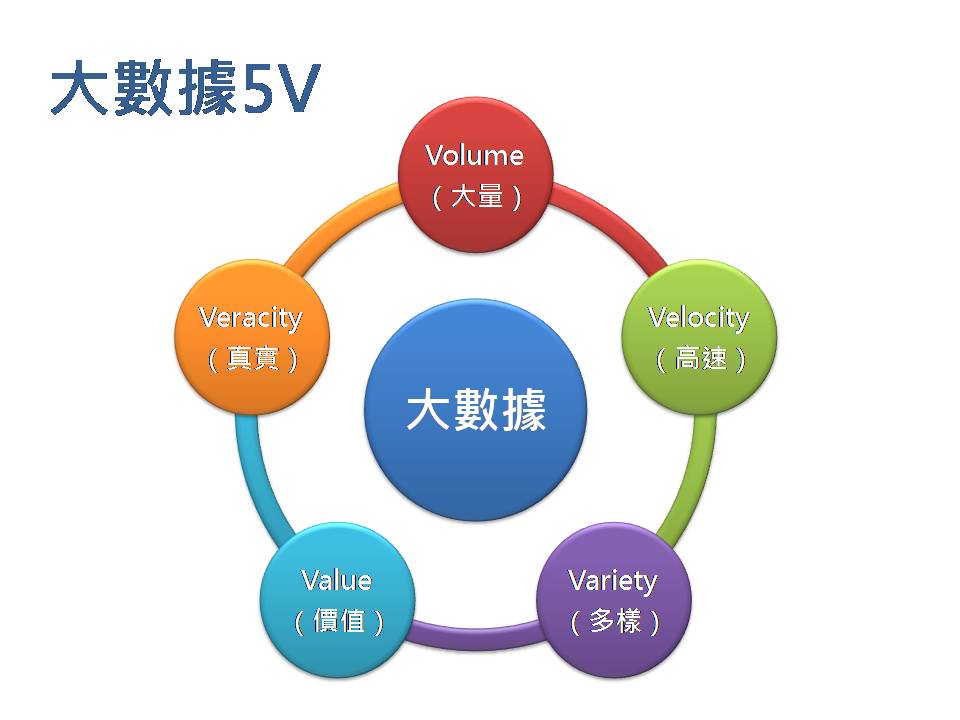 4.多大的資料量才算大數據Big Data ☎資料量要多大才能說是大數據? 根據維基百科的定義,資料大小從幾TB(Terabyte)到幾PB(Petabyte)不等 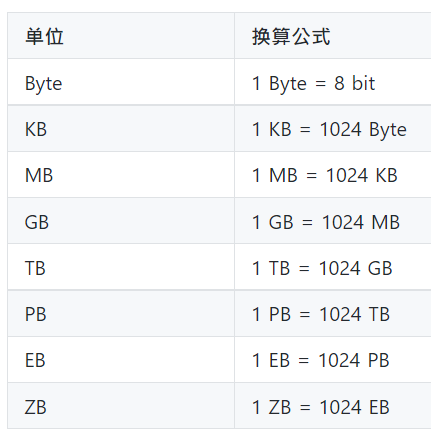 5參考文獻: (1).什麼是大數據 (2).巨量資料(wiki) (3).大數據到底是什麼意思?事實上,它是一種精神 (4).認識大數據定義、分析與工具 (5).大數據,不只是很大的數據 |
||||
6.大數據分析與傳統商業分析的差異 |
1.大數據分析與傳統商業分析的差異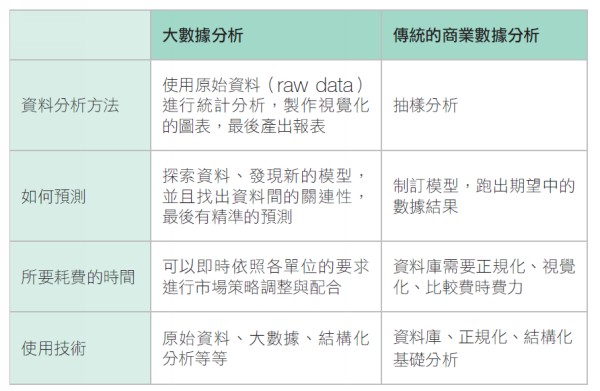 (1)大數據分析: ☎分析方法:使用原始資料➜統計分析➜產生視覺化圖表➜產生報表 ☎使用技術:原始資料,大數據,使用程式碼(python/R)進行結構化分析 ☎預測方法:找出數據間的關聯性➜建立預測模型➜完成預測 2.參考文獻: (1).大數據,不只是很大的數據 |
||||
7.大數據的分析步驟 |
1.大數據的分析步驟:取得,儲存,運算,視覺化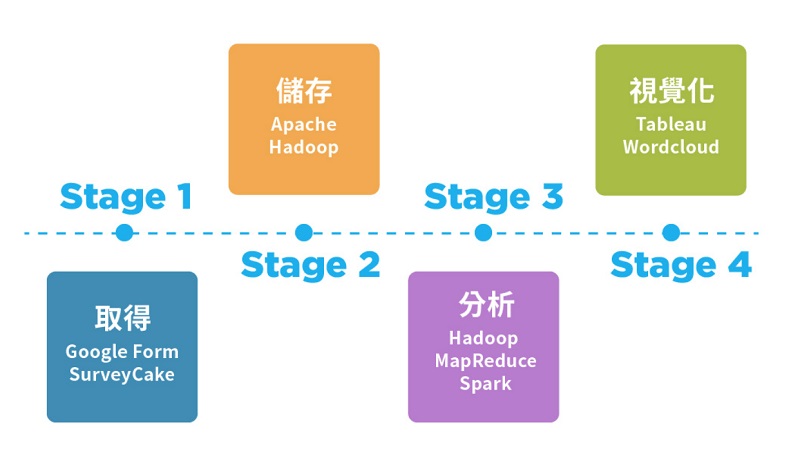 ☎大數據分析第一步:取得 數據隨時隨地都在產生,就連你上班時的行走路線,都可以成為商家選擇新店地址的參考資料。若是擁有大量使用者的企業,蒐集使用者的活動紀錄就可達到以數據預測未來的目標;若是較小型的企業,則可主動邀請使用者填寫問卷,逐步累積資訊量。 ☎大數據分析第二步:儲存 由於資料量龐大,突破儲存技術式處理大數據的第一個難關。因此處理大數據時多使用分散式處理系統,透過分割資料與備份儲存,突破記憶體過小的障礙。 ☎大數據分析第三步:運算 為達成預測未來的目的,機器可以透過分類、迴歸分析、排序、關聯分析等方式找出其中規律,並運用決策樹、遺傳演算法、人工神經網路等模型進行計算。 ☎大數據分析第四步:視覺化 經過分析後的數據仍是數字與列表,不易閱讀。因此可搭配視覺化工具,將數據轉化為較容易閱讀與理解的形式。 2.參考文獻: (1).認識大數據定義、分析與工具 |
||||
8.視覺化常用工具 |
1.三大視覺化工具:Power BI,Tableau,Data Studio 功能:都能夠製作Dashboard(互動儀表板,報表平台) 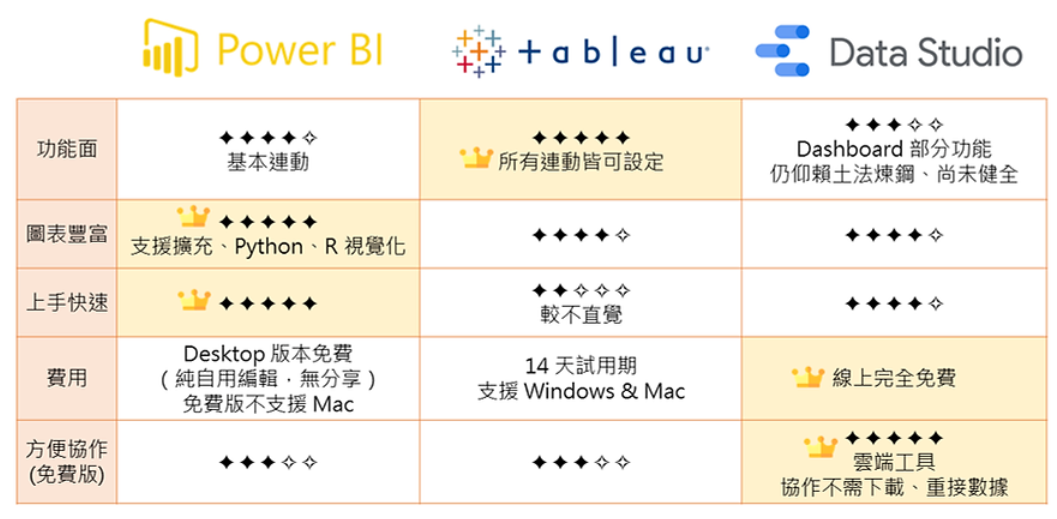 (1)Power BI:微軟Microsoft (1-1)費用: ☎免費版:若要編輯或瀏覽 Power BI Dashboard 僅能確保每個使用者都有在桌面下載 Power BI。 但免費PC版 Power BI 僅能在 Windows 上使用, Mac 使用者僅能夠過網頁/付費方式使用 ☎付費版:Power BI 可透過企業全體購買 Pro License(每個月300元),進而能夠做到網頁版共用。 ☎付費版:公司內可以購買整個 Office 365 package(已經包含 Power BI Pro License),以利內部資料互通,大家也不用另外在電腦下載應用程式,直接網路編輯與瀏覽即可,Mac 使用者也能進而編輯 ☎付費版:Power BI Premium,每月每個人600元。 ☎Power BI定價參考網址 (1-2)功能: Power BI 基本上功能與Tableau大同小異。 Power BI的操作比較簡單,更直覺化(Tableau操作較複雜)。 Power BI同時可支援 Python & R 的視覺化工具, Power BI 的 DAX 語法相較 Tableau 好懂。 (2)Tableau (2-1)費用: ☎Tableau Public 是一個免費的平台 ☎Tableau Prep 免費試用30天 ☎Tableau Desktop 免費試用14天 ☎Tableau Server 免費試用 ☎CRM Analytics(原稱 Tableau CRM) 認識大數據定義、分析與工具 ☎Tableau 在企業級規模部署時Power BI比較便宜,因為雖然Power BI 隨附於O365中,但若要企業級部署,考慮Power BI Pro與Power BI Premium 間的功能差距,若真的要能做到 Tableau Server 大部分的功能,是一定需要 Premium 的,不然會受到算力、數據量大小、協作功能等的差距影響,很難做到企業級部署。 而Power BI Premium 在2021/02時所記錄的起始報價為 台幣 150,120。 Tableau的產品生態: 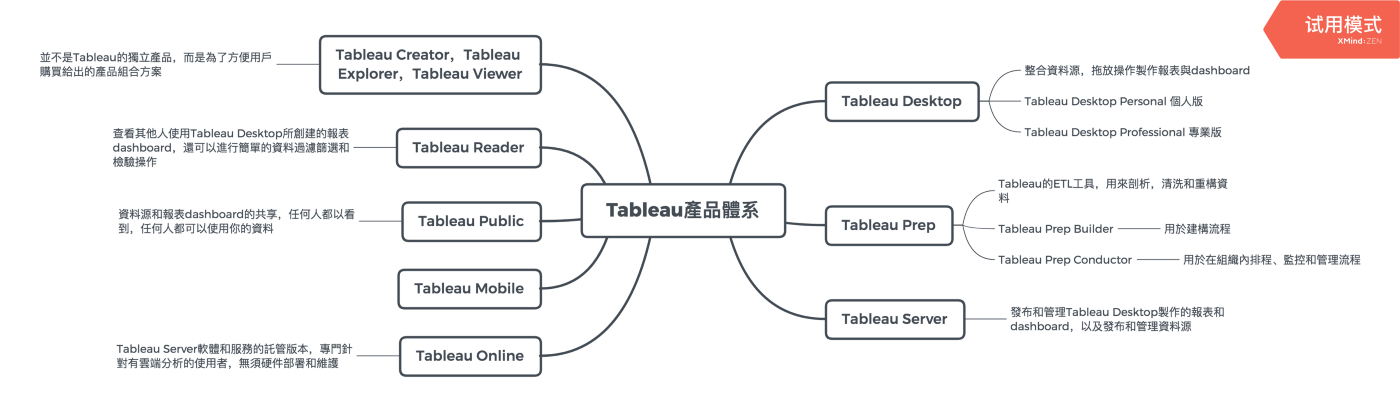 (2-2)功能: ☎功能強大。 ☎2020/01年時統計,世界500強企業裡面96%是Tableau的客戶。 (3)Data Studio (3-1)費用: ☎google雲端軟體,完全免費的平台 (3-2)功能: ☎優點:因為 Google 產品大多都是可開權限共享, 所以要結合Google 其他應用程式(Big Query, Google Analytics),就可以直接串接到 Data Studio,因為便利而使用它。 ☎優點:雲端使用,是目前線上最流暢的(因為google產品都是雲端產品),而且可以共同編輯 ☎缺點:功能性而言,現在 Data Studio 在細節調整上還是略輸 Power BI 與 Tableau 一些 2.BI(Business Intelligence,商業智慧)市場分成2類: (1)自助式分析組別: 組織裡面每個人都有能力利用此組別內的BI工具連接數據與探索數據,發表屬於自己的數據見解 例如:Power BI,Tableau,Data Studio (2)報表組別: 大部份情況之下,因需要撰寫大量函式或需要寫SQL,需要由統一專業部門開發,如IT單位 例如:Finereport,Microstrategy 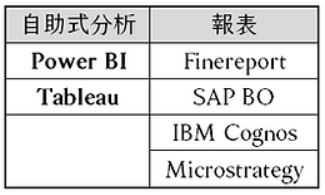 3.參考文獻: (1).Tableau 與 Power BI 完整比較指南 (4).Tableau VS. PowerBI |
||||
9.大數據的類型:結構化、非結構化、半結構化資料 |
1.大數據的類型:結構化、非結構化、半結構化資料 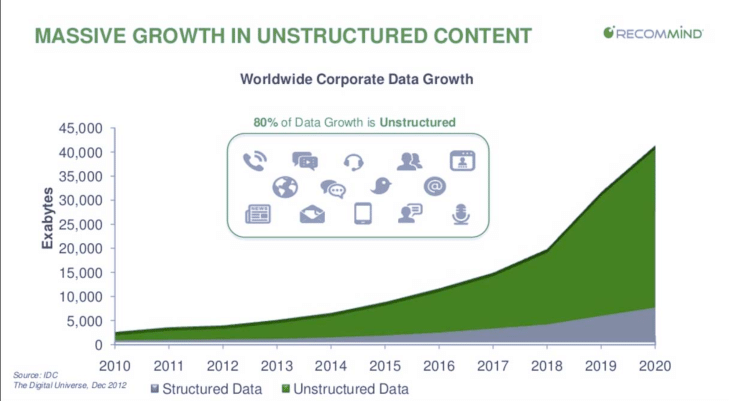 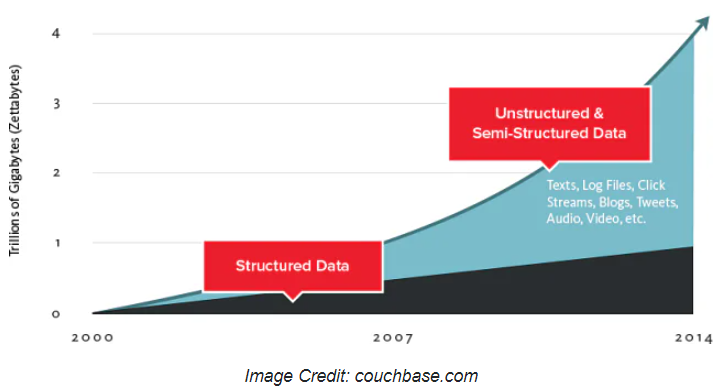  (1)結構化資料:這類資料最容易整理和搜索, ☎主要包括:財務資料、機器日誌、人口統計明細等。 結構化資料很好理解,類似於 Excel 試算表中預定義的行列佈局。 這種結構下的資料很容易分門別類,資料庫設計人員和管理員只需要定義簡單的演算法就能實現搜索和分析。 不過,即使結構化資料數量非常大,也不一定稱得上大資料,因為結構化資料本身比較易於管理,不符合大資料的定義標準。 一直以來,資料庫都是使用 SQL 程式設計語言管理結構化資料。 SQL 是由 IBM 在 20 世紀 70 年代開發的。 (2)非結構化資料: ☎因為web2.0盛行後產生很多非結構資料。 ☎(web 2.0內容:透過網路應用,以使用者為中心,促進網路上人與人間的資訊交換和協同合作) ☎(web 2.0範例:網路社群、網路應用程式、社群網站、部落格、Wiki) ☎資料包括:社交媒體內容、音訊檔、圖片、開放式客戶評論等。 ☎這些資料符合大數據定義中:『大而複雜』的要求,也因此這些資料通常很難用標準的行列關係型數據庫捕獲。 大多數情況下企業若想搜索、管理或分析大量非結構化資料,只能依靠繁瑣的手動流程。 毫無疑問,分析和理解這類資料能夠為企業帶來價值,但是執行成本往往太過高昂。而且,由於耗時太長。 但是因為無法存儲在試算表或關係型數據庫中,所以非結構化資料通常存儲在資料湖、資料倉庫和 NoSQL 資料庫中。 (3)半結構化資料: ☎半結構化資料是結構化資料和非結構化資料的混合體。 ☎例如:電子郵件, 因為其中的正文:屬於非結構化資料, 而寄件者、收件人、主題和日期:屬於結構化資料。 使用地理標記、時間戳記或語義標記的設備也可以同時提供結構化資料和非結構化內容。 3.參考文獻: (1).什麼是大數據 (2).web 2.0 (4).Tableau VS. PowerBI |
||||
| chp1.安裝與使用python的四種方法 | |||||
| 1.使用python的四種方法 | 2.Anaconda下載點 | 3.安裝anaconda | 4.Anaconda cmd指令 | ||
| 5.建立Anaconda虛擬環境 | 6.使用Spyter編譯器 | 7.網頁版python編輯器jupyter notebook | 8.其它線上雲端可編譯的python平台 | ||
1.前言 |
Python堪稱是大數據與AI時代的最重要程式語言,在資料處理上有著非常重要的地位。而隨著AI的興起,讓傳統的零售業、金融業、製造業、旅遊業,以及政府都爭相投入,無不希望能運用數據分析與預測來協助決策方向,也讓新興的數據分析師、資料分析師成為熱門職業,因此本課程將講解如何使用網絡爬蟲技術以掌握資料爬取分析、視覺化呈現,以及儲存交換應用的關鍵技術。 Python資料處理的三大技術分別是:擷取分析、視覺化呈現與儲存應用。 而其應用的範疇包括:網路爬蟲、資料正規化、資料視覺化、資料儲存與讀取(CSV、Excel、Google試算表、SQLite、MySQL)、批次檔案下載、公開資料應用、API建立、驗證碼辨識。 |
||||
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組 |
||||
2.執行python的四種方法 |
1.要編寫python有三種的方法: 一、方法1:安裝python單純的python 缺點:功能陽春,沒有太多的模組,無法馬上寫大數據分析程式。 安裝網址:python官網下載 二、方法2:安裝Anaconda 優點:會同時安裝python、1000多種數學繪圖模組、Spyder編輯器,能夠支援大數據分析。 缺點:會安裝了很多你用不到的模組,浪費硬碟空間。 安裝網址:到Anacond官網下載安裝 三、方法3:使用python官網線上shell 使用repl線上python 四、方法4:使用google雲端硬碟的雲端軟體:Cola,colaboratory 優點:Google 的 Colab 是一個讓你用網頁瀏覽器就能寫 Python 程式、並且執行的平台。 優點:Colab 提供免費的 GPU 讓你高效運算機器學習與深度學習演算法。 優點:Google Colab 預先幫你安裝好大家最常用的 Python 套件,幫你解決了一半以上的煩惱,讓 Python 新手可以不用在剛起步就學習環境部署的麻煩事。數據分析常用的 Pandas 與 Numpy、資料視覺化好用的 Seaborn 與 Matplotlib、還有機器學習必備的 xgboost 或 Tensorflow,這些都是 Colab 預先安裝好的套件。 不需要再自行安裝套件:(Terminal)輸入 pip install 優點:可以從 Google Drive 取得你要用的檔案、然後透過 Python 程式讀取; 優點:可以與google其它軟體整合,例如:也可以匯入 Google Sheet 的表格資料,然後用你最愛的視覺化套件(例如 Matplotlib)畫出美麗的圖表。 優點:Colab 其中一個厲害的地方就是,你除了可以執行 Python、也能執行 Command Line,只要在 Command Line 指令加上驚嘆號就能做到,像是 !mkdir。你可以在 Colab 裡 Python 程式碼寫到一半的時候,突然加進幾行 Command Line 來操作檔案,完成後,再讓 Python 程式碼接著寫下去,Python 與 Command Line 可以無痛切換。 優點:%%timeit:算出你的程式碼區塊花多少時間執行,分析你的演算法效率時很好用。 優點:%run my_script.py:執行你的另一個 Python 程式,如果你的程式還需要呼叫另一個程式,就需要使用。 |
||||
3.Anaconda下載點 |
|
||||
| 3.安裝anaconda |
3.安裝anaconda 功能:原始的python功能太陽春,若下載anaconda,則可以提供300多種的科學數學模組,可以提供大數據資料分析 (1)Anaconda是一個免費的Python和R語言的發行版本,用於計算科學(資料科學、機器學習、巨量資料處理和預測分析) (2)因為Anaconda有很多的數據分析模組,所以大數據分析會使用到的『pandas、Numpy、Scipy』python package套件,在anaconda安裝完成時就已經包含在裡面了。 (3)Anaconda中文是森蚺(大蟒蛇)。 1)可以把Anaconda當作是Python的懶人包,除了Python本身(python2, 3) 還包含了Python常用的資料分析、機器學習、視覺化的套件 2).完全開源和免費 3).額外的加速、優化是收費的,但對於學術用途可以申請免費的 License 4).全平台支持:Linux、Windows、Mac 5).支持 Python 2.6、2.7、3.3、3.4,可自由切換, 6).內帶spyder 編譯器(還不錯的spyder編譯器) 7).自帶jupyter notebook 環境 (就是網頁版的python編輯器,副檔名為IPthon) (4)常用套件:  Numpy: Python做多維陣列(矩陣)運算時的必備套件,比起Python內建的list,Numpy的array有極快的運算速度優勢 Pandas:有了Pandas可以讓Python很容易做到幾乎所有Excel的功能了,像是樞紐分析表、小記、欄位加總、篩選 Matplotlib:基本的視覺化工具,可以畫長條圖、折線圖等等… Seaborn:另一個知名的視覺化工具,畫起來比matplotlib好看 SciKit-Learn: Python 關於機器學習的model基本上都在這個套件,像是SVM, Random Forest… Notebook(Jupyter notebook): 一個輕量級web-base 寫Python的工具,在資料分析這個領域很熱門,雖然功能沒有比Pycharm, Spyder這些專業的IDE強大,但只要code小於500行,用Jupyter寫非常方便,Jupyter也開始慢慢支援一些Multi cursor的功能了,可以讓你一次改許多的變數名稱 (5)優點:省時:一鍵安裝完90%會用到的Python套件,剩下的再用pip install個別去安裝即可 (6)缺點:占空間:包含了一堆用不到的Python的套件(可安裝另一種miniconda) (7)下載網址:https://www.anaconda.com/ 選擇個人版:indivisual https://www.anaconda.com/products/individual →Download →Windows Python 3.7(會自動幫你安裝Python 3.7) 64-Bit Graphical Installer (466 MB) 32-Bit Graphical Installer (423 MB) (8)安裝過程,要勾選 不勾選:add the anaconda to the system PATH(但是2020年,ananconda不建議勾選這個,容易發生錯誤) 勾選:Register anaconda as system Python 3.7 (9)安裝結束 →在windows開始→anaconda有6個項目,最常用的有3個 (1)anaconda prompt:可以直接下cmd指令 (2)Spyter:編譯器(還不錯的spyder編譯器) (3)jupyter notebook(網頁版的python編輯器,副檔名為IPthon) |
||||
| 4.Anaconda prompt:cmd指令 |
4.使用anaconda prompt:直接下cmd指令 注意:windows 10 必須使用管理員來執行(點選anaconda prompt→滑鼠右鍵→以系統管理員身份進行) (1)列出目前已經安裝的anaconda的模組與版本: conda list (2)對某個模組更新安裝 conda update 模組 範例:conda update ipython (3)安裝某個模組 方法1:conda install 模組 範例:conda install numpy # 安裝 NumPy 1.15 以後、 1.16 以前 conda install 'numpy>=1.15,<1.16' 方法2:pip install 模組 範例:pip install numpy (4)解除安裝某個模組 方法1:conda uninstall 模組 範例:conda uninstall numpy 方法2:輸入 conda remove PACKAGE_NAME可以從目前的工作環境移除指定套件。 # 移除 NumPy conda remove numpy numpy-base 方法3:pip uninstall 模組 範例:pip uninstall numpy (5)在anaconda prompt執行python程式 方法1: 先到工作目錄:cd ch1 執行.py程式:python test1.py 方法2:python c:\chp1\test1.py (6)常用指令 conda --version 檢視 conda 版本 conda update PACKAGE_NAME更新指定套件 conda --help 檢視 conda 指令說明文件 conda list --ENVIRONMENT 檢視指定工作環境安裝的套件清單 conda install PACAKGE_NAME=MAJOR.MINOR.PATCH 在目前的工作環境安裝指定套件 conda remove PACKAGE_NAME 在目前的工作環境移除指定套件 conda create --name ENVIRONMENT python=MAIN.MINOR.PATCH 建立新的工作環境且安裝指定 Python 版本 conda activate ENVIRONMENT 切換至指定工作環境 conda deactivate 回到 base 工作環境 conda env export --name ENVIRONMENT --file ENVIRONMENT.yml 將指定工作環境之設定匯出為 .yml 檔藉此複製且重現工作環境 conda remove --name ENVIRONMENT --all 移除指定工作環境 使用 conda list | grep numpy 檢查 Python 套件清單中是否還有 NumPy 套件 輸入 conda search PACKAGE_NAME可以檢視指定套件在 conda 中可安裝的版本列表。 # 檢視 NumPy 在 conda 中可安裝的版本 conda search numpy=1.16.3 |
||||
| 5.用Anaconda prompt來建立虛擬環境 |
5.使用Anaconda prompt來建立虛擬環境 功能:可以建立多個Anaconda虛擬環境 例如:目前安裝後預設是python 3.x版本的環境,若要創建一個python 2.x的環境,就可以在Anaconda虛擬環境實現 (1)# 檢視電腦中可使用與目前所在的工作環境 conda env list (2)使用 conda create --name ENVIRONMENT python=MAIN.MINOR.PATCH 指令可以建立出乾淨、極簡且資源隔絕的工作環境。 指令:conda create -n 虛擬環境名稱 python=版本 anaconda # 建立一個名稱為 demo 的 Python 2 工作環境 conda create --name demo python=2 範例:建立py27env環境 conda create -n py27env python=2.7 anaconda (3)輸入 conda activate ENVIRONMENT 可以啟動指定工作環境、 方法1:conda activate ENVIRONMENT 方法2:activate ENVIRONMENT 範例:activate py27env 方法3:到windows→開始→點選Anaconda prompt(py27env) (4)關閉虛擬目錄,回到原本pytohn環境(base) 使用 conda deactivate 則是切換回預設的 base 工作環境。 方法1:conda deactivate 方法2:deactivate (5)# 檢視 demo 工作環境中的套件 conda list -n py27env (5)範例 A.建立py27env虛擬環境 conda create -n py27env python=2.7 anaconda B.切換到py27env虛擬環境 activate py27env C.檢視 demo 工作環境中的套件 conda list -n py27env D.# 檢視 Python 版本 python --version E.關閉虛擬目錄,回到原本pytohn環境(base) deactivate (5)複製一個與目前pyhon環境(或是py27env) 完全相同的工作環境 conda create -n 新虛擬環境名稱 --clone root 範例:conda create -n py27env2 --clone root # 檢查明確所有虛擬環境名稱 conda info -e (6)移除某個虛擬環境 conda remove -n 虛擬環境名稱 --all 範例:conda remove -n py27env --all (7)常用指令整理 安裝:conda install 更新:conda update 移除:conda remove 在工作環境管理透過 創建:conda create 啟動:conda activate 停止:conda deactivate 匯出設定檔:conda env export 移除:conda remove |
||||
| 6.使用Spyter編譯器 |
6.使用Spyter:編譯器 (1)新增一個py檔案 File→ New file print("你好,歡迎光臨") print(1+1) Run➤ (2)開啟已經存在的檔案 方法1:File→ Open 方法2:拖曵檔案總管的py檔案到Spyder (3)在Spyter使用簡易智慧輸入 方法:按『tab』 範例: 先輸入p 然後按『tab』 出現list清單,都是p開始的指令 (4)程式除錯 方法1:若是這一行有指令寫錯,就會在最左邊出現三角形▲警告icon 方法2:在這個一行最左邊double click,就會出現中斷點(或是這一行按F12) |
||||
| 7.jupyter notebook網頁版的python編輯器 |
7.jupyter notebook (1)功能:是網頁版的python編輯器,副檔名為IPthon 會開啟瀏覽器:http://localhost:8888/tree 對應的硬碟目錄 = C:\Users\電腦名稱 (例如: C:\Users\user) (2)練習線上編輯一個簡單python程式 A.右方→New→Python3 在cell裡面輸入In[1] a = ("apple","grape","banana") print(a[2]) B.Run C.修改檔案名稱→Untitled→exp1-3 D.查詢雲端檔案放置位置:C:\Users\電腦名稱\exp1-3.ipynb (3)二種不同的Run方式 A.Run:會新增一個new cell B.Ctrl+Enter:會停留在原本的cell (4)在jupyter notebook使用簡易智慧輸入 方法:按『tab』 範例: 先輸入p 然後按『tab』 出現list清單,都是p開始的指令 (5)在jupyter notebook編輯的檔案無法讓python IDE編譯 jupyter notebook編輯的檔案是.ipynb 與python的.py不同 改善方法:只能把程式碼複製貼上,在兩個平台交流 |
||||
| 8.其它線上雲端可編譯的python平台 |
8.其它線上雲端可編譯的python平台 網站:http://rep.it/languages/python3 |
||||
| chp2.Pandas與數據分析 | |||||
| 2-1.Python大數據分析最重要的四個模組:pandas,matplotlib,numpy,scipy | 2-2.Pandas介紹 | 2-3.Pandas安裝 | 2-4.Pandas的資料結構 | ||
| Pandas速查手冊 | 2-1-Pandas速查手冊 | ||||
| 上課參考教材 | 用Pandas掌握商務大數據分析 | pandas官網(英文) | w3schools的pandas教學(英文) | runoob的pandas菜鳥教程(中文) | |
| pandas參考教材 | w3Cschool的pandas教學(中文) | Steam教學網-python | 蓋若pandas 教程 | pandas的df的操作函數 | |
| pandas參考教材 | 十分鐘入門 Pandas(英文) | 十分鐘入門 Pandas(英文) | 10分鐘的Pandas入門-繁中版 | 十分鐘入門 Pandas(中文) | |
| pandas參考教材 | pandas官網全部章節翻譯 | pandas官網全部章節翻譯 | |||
| pandas參考教材(英文) | kaggle pandas教學 | 100 pandas tricks to save you time and energy | 官網0.22.0:pandas documentation | ||
| pandas參考教材(中文) | Pandas 101:資料分析的基石 | 資料科學家的pandas 實戰手冊:掌握40 個實用 | 簡明 Python Pandas 入門教學 | 資料分析必懂的Pandas DataFrame處理雙維度資料方法 | |
| pandas速查手冊 | pandas 速查手册 - 盖若 | Pandas速查手冊中文版 - 知乎專欄 | Pandas速查手冊中文版- 騰訊雲開發者社區 | ||
| pandas速查手冊 | Pandas中DataFrame基本函數整理(全) | Pandas 魔法筆記(1)-常用招式總覽 | |||
| 資料集dataset | kaggle小費資料集範例A Waiter's Tips example | 【視覺化】小費(tips)資料集分析 | 小費(tips)資料集提取和檢視相應資料 | 小費資料集Tips Dataset(csv) | |
| 資料集dataset | Kaggle的星巴克滿意度調查資料集( | 中文解析:Kaggle星巴克滿意度調查 | |||
| SQL語法 | SQL語法教程 | pandas vs SQL | 如何在Pandas裡寫SQL查詢語句 | ||
| 資料分析4大模組(runoob) | numpy | pandas | matplotlib | scipy | |
| 資料分析四大模組 |
1.Python大數據分析最重要的四個模組 |
||||
| Pandas介紹 |
2-2.Pandas介紹: |
||||
| Pandas安裝 |
2-3.Pandas安裝: |
||||
| Pandas的資料結構 |
2-4.Pandas的資料結構: |
||||

| chp4.Pandas基礎入門練習 | |||||
| 上課練習範例 | 📣4-1-讀csv | 📣4-2-讀excel | 📣4-3-畫圖 | 4-4-基本資料分析-平均-f-string格式-90以上 | |
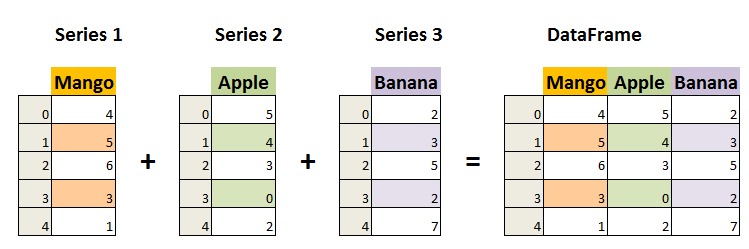
| 4-5-DataFrame與Series | 4-6-df["欄名稱"]與df.loc["列名稱"] | 4-7-列索引鍵取值.iloc | 4-8-列索引鍵取值.loc | ||
| 4-9-一般排序sort_values | 4-10-進階排序(函數def,lambda) | 4-11-修改-大小寫-replace | 4-12-新增insert/append | ||
| 📣4-13-刪除drop | 4-14-查詢欄位-新增欄位df.assign() | 4-15-條件查詢-一般做法-df.query() | 📣4-16-關鍵字查詢-.str.contains('經管') | ||
| 4-17-查缺值-isnull-isna-notna | 4-18-axis軸,計算mean,sum,max,min | 4-19-資料的合併:concat橫向併,縱向併,append上下併 | 📣4-20-條件查詢 | ||
| 1.Plotly,Plotly-Express簡介 |
1.Plotly,Plotly-Express簡介 |
||||
|
chp11.讀取各種資料庫檔案 chp11-1.noSQL:csv |
|||||
| 上課練習範例 | 11-1-1-Excel轉csv | 11-1-2-筆記本自行做csv | |||
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組 |
||||
1.Numpy簡介與安裝 |
1.Numpy簡介與安裝 |
||||
|
|||||
|
chp11.讀取各種資料庫檔案 chp11-2.noSQL:json |
|||||
| 上課練習範例 | 11-2-1-Excel轉json | 11-2-2-自己寫json | 11-2-3-字典dict轉json | ||
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組 |
||||
1.Numpy簡介與安裝 |
1.Numpy簡介與安裝 |
||||
|
|||||
|
chp11.讀取各種資料庫檔案 chp11-3.noSQL:xml |
|||||
| 上課練習範例 | 11-3-1-Excel轉xml,缺考者 | ||||
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組 |
||||
1.Numpy簡介與安裝 |
1.Numpy簡介與安裝 |
||||
|
|||||
|
chp11.讀取各種資料庫檔案 chp11-4.noSQL:字典dict,串列list |
|||||
| 上課練習範例 | 11-4-1-第1種:以欄位角度,將dict轉df | 11-4-2-第2種:以列index角度,將list轉df | 11-4-3-第3種:字典dict轉成df-groupby分群4做法 | ||
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組 |
||||
1.Numpy簡介與安裝 |
1.Numpy簡介與安裝 |
||||
|
|||||
|
chp11.讀取各種資料庫檔案 chp11-5.noSQL:資料集dataset |
|||||
| 上課練習範例 | 11-5-1-讀外部資料集:kaggle tips小費(分群),groupby-agg | 11-5-2-內部資料集:鐵達尼號資料集(分群,繪圖),groupby-agg-plot | |||
| 資料下載:鐵達尼號資dataset (1)指令: import seaborn as sns df = sns.load_dataset('titanic') (2)欄位參數: PassengerId:乘客ID編號 survival:是否倖存(0 = No, 1 = Yes pclass:船票等級(1 = 1st, 2 = 2nd, 3 = 3rd sex:性別 Age:年齡 sibsp:在船上同為兄弟姐妹或配偶的數目 parch:在船上同為家族的父母及小孩的數目 ticket:船票編號 fare:船票價格 cabin:船艙號碼 embarked:登船的口岸(C = Cherbourg,Q = Queenstown,S = Southampton 補充: Cherbourg:瑟堡,位於法國西北的一個城鎮,屬重要軍港和商港。 Queenstown:科芙,位於愛爾蘭,於1850年更名為皇后鎮(又稱昆士敦),以紀念維多利亞女王的造訪,直到1920年,愛爾蘭自由邦建立後,它被重新命名為科芙。 Southampton:南安普敦,位於陽光燦爛的英國南方海岸,是個港口城市,離倫敦僅1小時車程,鐵達尼號正是從這裡出航。 |
|||||
Python大數據分析最重要的四個模組 |
1.Python大數據分析最重要的四個模組 |
||||
1.Numpy簡介與安裝 |
1.Numpy簡介與安裝 |
||||
|
|||||
|
chp11.讀取各種資料庫檔案 chp11-6.noSQL:SQLite |
|||||
| 上課練習範例 | 11-6-1.SQLite資料庫的編輯軟體下載與安裝 | 11-6-2-讀取一個已經建立好的SQLite資料庫 | 11-6-3-由dict建立SQLite資料庫,下載後再讀入 | ||
| 手機資料庫:SQLite | |||||
1.SQLite資料庫的編輯軟體下載與安裝 |
1.手機資料庫:SQLite特色: |
||||
|
|||||
|
chp11.讀取各種資料庫檔案 chp11-7.SQL:mySQL 注意:pandas讀取mySQL非常重要,詳細說明在chp7,chp8 |
|||||
| 教學 | 1.安裝mySQL | 2.範例:建立第一個mySQL資料庫 | 3.Python先要安裝模組才能連線mySQL | 4.方法1:安裝讀取mySQL模組:pymysql | |
| 教學 | 5.方法2:安裝讀取mySQL模組:pymysql | ||||
| 下載 | 1.架站安裝mySQL:Wamp | 2.架站安裝mySQL:Xampp | 3.下載ch09資料庫 | ||
| 建立mySQL資料庫 | 1.將ch09.sql轉成ch09資料庫 | 2.將有欄位名稱Excel檔案轉成mySQL資料庫 | 3.將無欄位名稱Excel檔案轉成mySQL資料庫 | ||
| 上課練習範例 | 14-1-用sqlalchemy連資料庫,新增1資料表 | 14-2-修改資料表(改約翰數學為59) | 14-3-刪除約翰的資料) | 14-4-新增1個欄位(歷史分數) | |
| 上課練習範例 | 14-5-新增1筆資料(新增amy的資料) | 14-6-修改資料表(改約翰數學為59) | |||
| 1.常用的架設Apache主機與mysql的安裝工具 | 常用的安裝mySQL與php架設主機工具: |
||||
| 2.建立第一個mySQL資料庫 | 2.建立第一個mySQL資料庫: |
||||
| 要安裝模組才能連線mySQL | 3.Python要安裝模組(支援mySQL): |
||||
| 安裝讀取mySQL模組:pymysql | 4.方法1:安裝讀取mySQL模組:pymysql |
||||
| 安裝第2種模組:SQLalchemy | 5.方法2:安裝第2種模組連線mySQL:SQLalchemy |
||||
| 1.建立第一個mySQL資料庫 | 1.建立第一個mySQL資料庫: |
||||
| 11-2.將有欄位名稱Excel檔案轉成mySQL資料庫 | 11-2.將Excel檔案轉成mySQL資料庫: |
||||
| 11-3.將無欄位名稱Excel檔案轉成mySQL資料庫 | 11-3.將無欄位名稱Excel檔案轉成mySQL資料庫 |
||||
|
|||||


| chp11-10.noSQL:把excel/csv傳到網站空間,分析結果讓主管也能夠存取 | |||||||||||||||||||||||||||||||||||
| 上課練習範例 | 11-10-1.(免費,穩定,速度快,但只有excel):上傳到wordpress網站 | 11-10-2.(免費,穩定,速度普通,只有excel/csv):上傳雲端轉成google sheet,再發布網路 | 11-10-3.(免費,穩定,不快,如何檔案皆可):上傳到GitHub網站 | 11-10-4.(免費但不穩定):將google雲端硬碟轉換成網站 | |||||||||||||||||||||||||||||||
wordpress網站 |
11-10-1.(免費,穩定,速度快):用wordpress.com網站來存放excel/csv檔案: (1)優點:簡單,免費,穩定,速度快 (2)WordPress有2個平台:wordpress.org,wordpress.com WordPress.com和WordPress.org之間的主要差異:  比較WordPress.com和WordPress.org ☎WordPress.com:
☎WordPress.org:
(3)使用 WordPress.org 的方式架站,大概要花多少錢? A.主機空間:每年約 1000元~數萬元 B.網域 (網址):每年約300元~數萬元 其餘選擇性的花費則是: C.佈景主題:有的人可能會買佈景主題來快速套用版型,客製化網站的外觀,費用可能是 1500元~數萬元。 D.外掛程式:有的人可能會買外掛程式來擴充網站的功能,通常越能幫助你賺錢的外掛越多,這方面的花費就越高。 雖然如此,wordpress.org還是比wordpress.com還要便宜, 所以初學者還是建議,從wordpress.org建立網站入手(設計過程是免費的),只有放入網站空間託管才要花錢。 WordPress.org的建立方法 WordPress.org/com的費用比較 (4)要怎麼開始買主機 (遠端的電腦、網路空間)? 主機商,例如: Bluehost 主機、 A2 Hosting 主機 Cloudways 主機, 他們都是世界級的主機商,穩定不斷線 (5)wordpress.com免費版: 最大的好處就是什麼都免費:『網址免費、主機免費、空間免費』,全部都免費。 但即然是免費的,就不免會限制一大堆。例如:
(6)若要來存放excel/csv資料檔案的網站,應該選擇:wordpress.com網站 ☎網址:WordPress.com 功能:架設網站、銷售商品、創作網誌 1.建立步驟1:註冊帳號:使用google帳號登入即可 2建立步驟2:選擇:免費方案:NT$ 0 3.建立步驟3:任運勾選:你的目標是什麼? 4.第一步,先幫網誌取個名字:myData 5.第二步:撰寫你的第一篇文章 新增文章標題:myData 點選左上角+ 選擇『媒體➜檔案』➜上傳excel檔案 示意圖 顯示上傳到wordpress網站空間的excel檔案的網址: 點選檔案名稱➜複製檔案網址: 示意圖 (6)excel檔案的網址: https://ccwtsu.files.wordpress.com/2023/05/member.xlsx |
||||||||||||||||||||||||||||||||||
wordpress網站 |
11-10-2.(免費,穩定,速度普通,只有excel/csv):上傳雲端轉成google sheet,再發布網路: (1)優點:簡單,免費,穩定,速度普通 缺點:只能讀取excel/csv (2)參考影片教學 (6)如何抓取與發佈GOOGLE試算表CSV檔 1.先上傳的你excel/csv檔案到google雲端硬碟,例如: 學生成績(excel) 圖書資料(csv) 2.在google雲端,打開檔案 3.滑鼠右鍵➜共用➜一般存取權➜知道連結的任何人 4.要打開檔案: (menu)檔案➜共用➜發布到網路➜網頁:選擇『Microsoft Excel』 示意圖 示意圖 5.取得google sheet的發布網路網址: 示意圖 |
||||||||||||||||||||||||||||||||||
|
11-10-3.(免費,穩定,不快):上傳到GitHub網站(使用GitHub 當作網頁空間) (1)什麼是GitHub? ☎網址:https://github.com/ ☎特色1:它的 G 跟 H 是大寫,其它字母小寫。它是一個商業網站,是目前全球最大的 Git Server ☎特色2:它屬於社群平台(類似FaceBook,IG),可以與全世界的『寫程式的網頁』分享訊息/分享程式碼的社群平台。 ☎特色3:它也是程式開發者最好的履歷。因為你過去所做過的專案、分享過的程式訊息/觀念、寫過哪些 Code,都可以看到記錄,無法造假。 ☎特色4:GitHub 是全世界最大的程式技術社群(6500萬程式設計師使用,有2億個open source程式碼開放分享出來),能與程式相關人員建立聯繫並進行交流,從中取得最新的知識與累積經驗。也能參與開放原始碼專案的建立。 (2)GitHub 主要有兩個核心用途: ☎開發者(Developer)可以儲存自己的專案(Project) ☎將對程式設計有興趣的人聚集在一起的社交平台(network) (3)GitHub的費用? ☎如果你採用分享的方式(上傳你的 Open Source 專案),可以完全免費使用。 ☎早期,如果想要在GitHub建立私人專案,則需要收費,費用是每個月 7 塊錢美金。 ☎Microsoft 在 2018 年 10 月併購了 GitHub,以往需要付費才能開設私人專案, 從2019 年 1 月開始,即使是免費帳號也可無限制的開設私人專案。 (4)鑑別Git vs GitHub,兩者不同 ☎Git:是工具:Git是用來版本控制的工具,類似『程式開發的日記』,會記錄每天程式開發過程的進度記錄,若是程式開發錯誤,可以回到之前正確的日期。 ☎GitHub:是網站,網站空間,可以代管原始碼(程式碼,網頁,git資料...)的服務平台server。 GitHub 的本體是一個 Git Server,網站則是使用 Ruby on Rails 開發 ☎GitHub 是一個雲端代管服務和公司,可以讓你的git 封存更輕鬆管理; 如果想找尋並處理開源程式碼Open Source專案的開發者,GitHub就是很好的選擇(託管網站) ☎Git是一個分散式的版本控制軟體,GitHub則是一個存放Git的空間 影片介紹:Git + GitHub 入門 (6)如何使用GitHub來免費發佈網站: 參考影片:用GitHub來免費發佈網站 參考影片:把做好的網頁秀在網路上 參考網頁:GitHub 註冊教學 ☎上傳到GitHub網站的好處:免費,穩定。 (5-1).建立帳號方法: (A).到GitHub官網:https://github.com/ (B).註冊帳號sign up:註冊 GitHub 網站,sign up (5-2).上傳網站到GitHub方法: ☎可以把 GitHub 想像成 Google 雲端,你將自己的作品上傳到雲端 第一步:準備好您要發佈的網頁,放在資料夾裡 第二步:在GitHub按下 New Repository 第三步:提供New Repository 名稱,必須遵守這個規則:名稱.github.io,完成後按下新增 第四步:按下uploading an existing file,然後將網頁資料夾移到 New Repository 裡 第五步:上傳檔案之後,在Commit 輸入訊息,最後再按下送出 第六步:到Settings / GitHub Pages 裡,按下Check it out here. 裡頭的Source選擇main 並Save 第七步:按下網址,並在網址後面加上/資料夾名稱/首頁名稱 完成 |
|||||||||||||||||||||||||||||||||||
1.google雲端硬碟 |
11-10-3.(免費但不穩定):將google雲端硬碟轉換成網站: |
||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||


|
chp12.網路爬蟲:web crawler chp12-1.Pandas讀取網頁表格 |
|||||
| 上課練習範例 | 12-1-1.pandas讀網頁第1個(df[0]),第2個表格(df[1]) | 12-1-2-用match找到相關表格,轉成df | 12-1-3-pandas用attrs尋找網頁標籤tag | ||
|
|||||
|
|||||
|
chp12.網路爬蟲:web crawler chp12-2.讀取html網頁:Request |
|||||
| 上課練習範例 | 12-2-1.Requests讀取網頁html標籤 | 12-2-2-Requests讀取json網頁結構 | |||
|
|||||
|
|||||
|
chp12.網路爬蟲:web crawler chp12-3.分析html標籤tag內容:BeautifulSoup |
|||||
| 上課練習範例 | 12-3-1.BeautifulSoup做網頁的資料爬取 | 12-3-2-BeautifulSoup網路爬蟲,查所有的超連結的innerhtml, href, class | |||
|
|||||
|
|||||
| chp5.Pandas一維資料結構:Series | |||||
| 上課練習範例 | 5-1-1-建立Series一維資料 | 5-1-2-Series一維資料的常用函數(1):max,min,mean,sum,std,median,describe | 5-1-3-Series一維資料的基本計算數目函數(2):size,count(),len(sr),sr+2 | ||
| 5-1-4-Series的取值2種方法:位置法,索引鍵法 | 📣5-1-5-Series有哪幾種unique, 有幾種nunique, ☎每一種的數目value_counts (重要性:商業數據分析經常會用value_counts查看各參數出現次數) |
||||
|
(1)性別有哪幾種?:df['性別'].unique() (2)性別有幾種?:df['性別'].nunique() (3)統計性別的『男,女』,出現的頻率?(統計內容值的出現次數):df['性別'].value_counts() (4)統計性別的『男,女』,出現頻率的百分比?:value_counts(normalize=True) (5)柱狀圖,比較性別的『男,女』,出現的頻率,2種: 次數比較圖 import matplotlib.pyplot as plt sr.value_counts().plot(kind="bar") 百分比比較圖 sr.value_counts(normalize=True).plot(kind='bar') |
|||||
| chp6.Pandas二維資料結構:DataFrame chp6-1.建立DataFrame 【課表9-2頁】 |
|||||
| 上課練習範例 | ☎6-1-0-(成果圖)欄位角度,用串列list建立DataFrame | ||||
| 上課練習範例 | 6-1-1-欄位角度,用字典dict建立DataFrame | 6-1-2-用串列list建立DataFrame,並設定欄索引鍵 | 6-1-3-用串列list建立DataFrame,並設定列索引鍵 | 6-1-4-用純字典dict建立DataFrame | |
|
(1)自己建立DataFrame:加上欄位 df = pd.DataFrame() df['name'] = ["約翰", "湯姆"] df['math'] = [90, 70] df['eng'] = [100,80] |
|||||
| chp6.Pandas二維資料結構:DataFrame chp6-2.DataFrame的5個屬性:index,columns,values內容,shape維度,dtypes資料型態 【課表9-5頁】 |
|||||
| 上課練習範例 | 6-2-1-5個屬性index,columns,values內容,shape維度,dtypes資料型態 | 6-2-2-取得欄索引鍵:df['xx'], df.xx | 📣6-2-3-修改欄位名稱,df.rename(columns={"xx":"xx"}) | 6-2-4-用純字典dict建立DataFrame | |
| 上課練習範例 | 6-2-5-設定index列索引鍵set_index,取消列索引鍵reset_index | ||||
|
(1)修改局部欄位名稱:數學➜math: df2.rename(columns={"數學":"math"}, inplace=True) (2)修改全部欄位名稱 df2.columns = ["id", "name", "sex", "chi", "eng", "math"] (3)全部的數學成績,都為0分 df2['math'] = 0 (4)全部的中文成績,都加10分 df2['chi'] += 10 (5)修改約翰的數學成績 = 0,方法1:欄位取值入手 df2['math'][3] = 0 (6)修改約翰的英文成績,為0分,方法2:索引取值入手 df2.set_index('name', inplace=True) df2.loc['約翰','chi'] = 10 ☎注意:設定值(索引,欄位)的特殊寫法:df.loc[索引, 欄位] = 100 |
|||||
|
chp6-3.列索引鍵有自動對齊的功能 【課表9-14頁】 |
|||||
| 上課練習範例 | 6-3-1-資料加入,列索引鍵會自動對齊資料,無資料則NAN | 6-3-2-列索引鍵vs欄位,轉置(df.T) | |||
|
chp6-4.數據清理:處理缺值NAN(檢查是否有缺值,統計總數,刪除,填滿缺值) 【課表9-16頁】 |
|||||
| 上課練習範例 | 6-4-1-查全部有缺值NAN的總共數目 | 6-4-2-查colunmns/index有缺值NAN的數目(降維查缺值) | 6-4-3-缺值NAN的處理(1):刪除該筆df.dropna() | 6-4-4-缺值NAN的處理(2):缺值填滿m1= df.fillna(值) | |
| 6-4-5-缺值填上面列的值(3)= df.fillna(method='ffill') | |||||
|
(1)什麼是NAN? NAN = not a number,缺值 (2)注意:要計算前,一定要先處理缺值,否則計算的結果,沒意義 (3)數據分析的步驟:數據採集,數據清洗,數據『查詢、計算』,數據分析與挖掘,數據可視化。 (4)數據的清洗:包括:缺值的處理、日期格式的統一,字串的取代 (5)如何快速檢查,是否有缺值,2步驟: 步驟1:先快速檢查全體:df.info():某個column,若有數字減少,代表有缺值 步驟2:熒光筆標註缺值:df.style.highlight_null() (6)判斷是否有缺值條件查詢,錯誤寫法: a1 = df['數學']=="NAN" 正確寫法: a1 = df['數學'].isna() a1 = df['數學'].isnull() (7)統計每個欄位的缺值共幾個? 查各欄位有缺值NAN的統計資料 = df.isnull().sum(axis=0) axis方向口訣:橫1,縱0 不寫axis,預設代表axis=0 (8)計算全部缺考人數 df.sum() ==>算總和,會降1維 ==> 2D -> 1D df.sum().sum() ==> 會降2維 ==> 2D -> 數字 (9)快速判別是否有缺值,2種方法: df2.isna().sum().sum() df2.info() (10)把有缺值的資料,都填入0 方法:df.fillna(0, inplace=True) (11)把有缺值的資料,都填入平均值 平均 m1 = df[['中文','英文','數學']].mean().mean() df.fillna(m1, inplace=True) (12)刪除有缺值的資料:df.dropna(inplace=True) (13)刪除中文有缺值的資料 = df2.dropna(subset=['中文']) (14)缺值填上面列的值 方法:df.fillna(method='ffill', inplace=True) ffill = forward fill (15)缺值填下面列的值 df2.fillna(method="bfill", inplace=True) df2.fillna(method="backfill", inplace=True) (16)統計各科目有缺值NAN的總數 df.isnull().sum(axis=0).to_frame().T (17)查那些科目有缺值的?(有,就顯示True) df.isnull().any(axis=0).to_frame().T (18)統計每個人有缺值的總數 df.set_index("姓名", inplace=True) df.isnull().sum(axis=1) (19)查每個人,是否有缺值(True/False)? df.isnull().any(axis=1).to_frame() (20)只要有缺值,就顯示個人資料 a1 = df.isnull().any(axis=1) df[a1] 注意:條件查詢的a1,一定是一條series的True/False |
|||||
|
chp6-5.DataFrame取值,三種格式 【課表9-22頁】 |
|||||
| 上課練習範例 | 📣6-5-0-三種取值法,簡易練習 | ||||
| 📣6-5-1-欄索引鍵取值 | 6-5-2-列索引鍵取值 | 6-5-3-列欄索引鍵共同取值 | 6-5-4-設定『麥克,傑克』的『英文,數學』= 0分 | ||
|
chp6-6.新增一欄/一列 【課表9-31頁】 |
|||||
| 上課練習範例 | 📣6-6-1-新增一欄df['歷史']=[..],新增一列df.loc['amy']=[...] | ||||
|
chp6-7.用軸axis來輔助函數計算(mean,sum,max,min) 【課表9-33頁】 |
|||||
| 上課練習範例 | 📣6-7-1-用axis來計算『個人平均,各科平均』 | ||||
|
(1)計算平均分數 = mean() # 計算1維Series的平均分:df['math].mean() # 計算2維DataFrame,每個欄位columns的平均分:df.mean(axis=0) # 計算2維DataFrame,每個列index的平均分:df.mean(axis=1) (2)axis=0,axis=1是什麼意思? # numpy和pandas中 axis(軸)的概念: # (A)df.mean(axis=1),表示『橫向計算』,依照row(index),計算每一水平列(每個學生)的平均 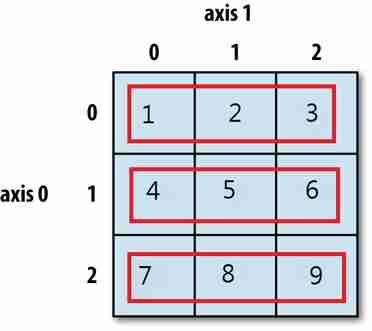 # (B)df.mean(axis=0),表示『縱向計算』依照欄位(colunmns),計算每一垂直欄位(每個科目)的平均 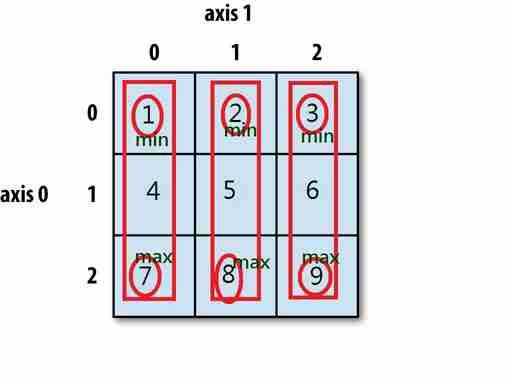 # 記憶法:橫移,總領 # 記憶法:橫1 ,縱0 (3)軸有2種寫法:axis=0/1,或是axis=columns/index,它們是什麼意思? # (A)原本df是2維資料,我要計算,若是向上推壓資料(向上方向為縱向,axis=0),最後2維表格被壓扁成一列(最後是一列資料,axis=index) # (B)原本df是2維資料,我要計算,若是向右推壓資料(向右方向為橫向,axis=1),最後2維表格被壓扁成一欄(最後是一欄位料,axis=columns) # (c)重要結論:axis代表2維資料的『降維』方法: ☎推壓2D數據的『過程』:橫向推axis=1,縱向推axis=0 ☎推壓2D數據的『結果』:最後變成一欄axis=columns,最後變成一列axis=index ☎推壓降維的『方向,與結果』,是不同方向(彼此垂直) 正是因為它們的方向不同,會造成很多同學無法理解 ☎其實,它們在描述同一件事情,只是描述的時間點不同,一個是『推壓過程』,一個是『資料最後降維結果的型態』 (4)新增一欄(各科平均),用axis來計算『各科平均』,2種方法: df.set_index("姓名", inplace=True) df.loc['各科平均'] = df[['中文','英文','數學']].mean(axis='index') df.loc['各科平均2'] = df[['中文','英文','數學']].mean(axis=0) |
|||||
|
chp6-8.篩選資料2種方法:條件查詢,query 【課表9-36頁】 |
|||||
| 上課練習範例 | 6-8-1-查『數學不及格的』2種:條件查詢,query | 6-8-2-多條件查詢:『數學>=60,且,英文>85』 | 6-8-3-多條件查詢:『數學<60,或,英文<70』 | ||
|
chp6-9.DataFrame的3種合併:concat,append,merge 【課表9-40頁】 |
|||||
|
(1)concat左右上下合併: # 橫向合併指令:df3 = pd.concat([df,df2], axis=1) # 縱向合併指令:df5 = pd.concat([df,df4], axis=0) # axis軸的口訣:橫移(1),總領(0) (2)append上下合併:df3 = df1.append(df2, ignore_index=True) (3)merge關聯合併(同名欄位):df3 = df1.merge(df2, on='性別') (4)merge關聯合併(不同名欄位):dfnew = df.merge(df4, how='left', left_on='畢業學校', right_on='學校') |
|||||
| 上課練習範例 | 6-9-1-DataFrame合併:concat(橫向併,縱向併) | 6-9-2-append(上下合併) | 6-9-3-merge(同名欄位的左右合併) | 6-9-4-merge(不同名欄位的左右合併) | |
| 6-9-5-merg(左右合併的各種練習) | |||||
|
chp6-10.DataFrame的常用函數(排序,max,min,sum,mean,出現次數value_counts) 【課表9-45頁】 |
|||||
| 上課練習範例 | 6-10-1-前3筆head(3),iloc[0:3],後3筆tail(3),iloc[-3:0] | 6-10-2-隨機取3筆sample(3),df基本資料describe | 6-10-3-使用函數sum,mean,max,min,計算欄位,計算列『科目總和,平均,最大,最低』 | 6-10-4-數學最高的前3名nlargest | |
| 上課練習範例 | 📣6-10-5-sort_values數學排序由低到高,排序由高到低 | 6-10-6-rank,數學排名,算三科排名,三科排名合併到原資料 | 6-10-7-rank,新增欄位『個人平均,全班排名』 | 6-10-8-☎計算出現次數:value_counts(非常重要), 種類unique, 類別幾種nunique |
|
|
☎(非常重要)進階計算:使用自訂映射函數:map,applymap,apply來轉換計算 【課表9-61頁】 |
|||||
| 上課練習範例 | ☎6-12-0-比較『map, applymap, apply7』的不同 | ||||
| 上課練習範例 | ☎6-12-1-map迴圈標示性別為『male, female』 | ☎6-12-2-applymap迴圈函數判別DataFrame及格/不及格 | ☎6-12-3-apply+axis來判別個人最低分,科目最低分 | ☎6-12-4-計算個人平均,排名次,標註當掉,計算年齡 | |
| 6-12-5-標註最低分,最高分,範圍標註,小數點精度,漸層圖標註 | 6-12-6-柱狀圖標註,文字漸層圖,某欄位反白標註,某欄位文字標註 | ☎6-12-7-applymap條件標註某欄位,apply條件標註某欄位,apply條件標註某索引列 | |||
| ☎初級商業數據五大分析型態: (1)自訂映射函數,有3種:apply(), applymap(), map()   (B).比較不同1: # DataFrame.apply:一次對整行或整列進行操作。 # DataFrame.applymap:一次操作一個元素 # Series.apply:一次操作一個元素 # Series.map:一次操作一個元素 (C).比較不同2:應用調用物件不同 # map:只能應用在Series (不會降維) # applymap:只能應用在DataFrames (不會降維) # apply:在DataFrames和Series都可以 (會降維) (D).比較不同2:處理邏輯不同 # map:對每個 Series 元素進行處理 # applymap:對 DataFrames 的每個元素進行處理 # apply:在軸(axis)進行處理(會降維),適用於更複雜的操作和聚合,行為和返回值取決於函數。 (2)指令 # df.apply(func, axis=0, args=(), **kwds) # df.applymap(func, na_action, args=(), **kwds) # Series.map(arg, na_action=None) (3).結論:4種映射計算: (3-1).df[欄位].map(函數) ➜ 處理1維數據,x是儲存格 ➜ 沒有降維不需要指定axis (3-2).df.applymap(函數) ➜ 處理2維數據,x是儲存格 ➜ 沒有降維不需要指定axis (3-3).df.apply(函數, axis=1) ➜ 可以處理2維數據,x是1維的欄/列(降維)➜ 2維數據的降維,要指定axis (3-4).df[欄位].apply(函數) ➜ 也可以處理1維數據,x是儲存格➜ 1維數據的降維,不可以指定axis |
|||||
|
📣chp6-14.表格視覺化(熒光筆標註重點)設定表格樣式style:反白標註highlight_max,漸層標註gradient,柱狀圖標註bar,數字精度set_precision,表格標題,apply/applymap迴圈控制標註 |
|||||
| 上課練習範例 | 6-14-1-標註最低分,最高分,範圍標註,小數點精度,漸層圖標註 | 6-14-2-柱狀圖標註,文字漸層圖,某欄位反白標註,某欄位文字標註 | ☎6-14-3-applymap條件標註某欄位,apply條件標註某欄位,apply條件標註某索引列 | ||
| chp8.數據分析的各種方法: |
|||||
|
📣chp8-1.頻數分析(一維數據) ☎重要性:頻率分析是指對數據集中的數據進行統計分析,計算每個值出現的次數,以便對數據集進行更深入的分析 ☎指令1:用 value_counts() 函數對一維Series進行頻率分析 |
|||||
| 上課練習範例 | 📣8-1-1-一維數據的頻數分析: Series有哪幾種unique, 有幾種nunique, ☎每一種的數目value_counts (重要性:商業數據分析經常會用value_counts查看各參數出現次數) |
📣8-1-2-一維數據的基本計算數目函數 | ☎8-1-3-一維數據統計數目的2種做法(value_counts,groupby().size()),新生入學人數比較圖,地區比較圖 | ||
|
(1)性別有哪幾種?:df['性別'].unique() (2)性別有幾種?:df['性別'].nunique() (3)統計性別的『男,女』,出現的頻率?(統計內容值的出現次數):df['性別'].value_counts() (4)統計性別的『男,女』,出現頻率的百分比?:value_counts(normalize=True) (5)柱狀圖,比較性別的『男,女』,出現的頻率,2種: 次數比較圖 import matplotlib.pyplot as plt sr.value_counts().plot(kind="bar") 百分比比較圖 sr.value_counts(normalize=True).plot(kind='bar') |
|||||
|
📣chp8-2.(分1群)比較分析(一維欄位分群後的統計資料:數目統計,對應第2欄位統計) ☎重要性:Groupby 是Pandas 中的一個很強大的操作方法。它可以將資料「分群/分組」,之後在分群的資料上做運算,然後再將運算的結果組合起來 ☎指令1:用 df.groupby("性別").size() 對性別欄位進行分群,並統計數量 ☎指令2:用 df.groupby("性別")['數學'].mean() 對性別欄位進行分群,並計算對應數學的平均分數 |
|||||
| 上課練習範例 | 📣8-2-1-建立性別欄位的分群groupby(),統計數量.size(),取出子群get_group('男') | ☎8-2-2-一維數據統計數目的2種做法(value_counts,groupby().size()),新生入學人數比較圖,地區比較圖 | ☎8-2-3-男女數學比較柱狀圖,男女數學分佈比較 | 📣8-2-4-男女數學平均,男女最高分,男女最高分是誰 | |
| 上課練習範例 | 📣8-2-5-數學最高最低,中文最高最低,英文最高最低 | ☎8-2-6-分群groupby(性別)後,新增欄位『數學平均』.agg(平均 = ('數學','mean') | 8-2-7-印出性別分群後的前2筆,男女的第1筆,男女數學排序後(低到高)前2筆,男女數學最高分資料,男女數學基本統計資料 | 📣8-2-8-(進階題)分群groupby...applys使用自訂函數來分群計算 | |
|
(1)重點1:Groupby的特色: (A).Groupby 是Pandas 中的一個很強大的操作方法。它可以將資料「分群/分組」,之後在分群的資料上做運算,然後再將運算的結果組合起來: (B).pandas 其中一個最重要的功能,就是groupby,是一個很強大的操作方法。 (C).它可以將資料「分群」,之後在分群的資料上做運算,然後再將運算的結果組合起來。 (D).例如1:老師想看一年級中,不同班級的「數學」以及「英文」成績的平均值 (依班級分群,在分群中做平均值運算)。 (D).例如2:國家想統計不同都市中收入的中位數 (依都市分群,在分組中取中位數), 都可以使用 groupby 運算達成。 (E).規律原則:如果資料中有「類別變數」出現,那通常就會有 groupby 的需求。 例如:性別(男/女),班級(1A/1B/1C),等級(A/B/C),洲(亞洲/非洲/美洲),膚色(黑/白/黃)…等 (2)groupby分解與重組示意圖: 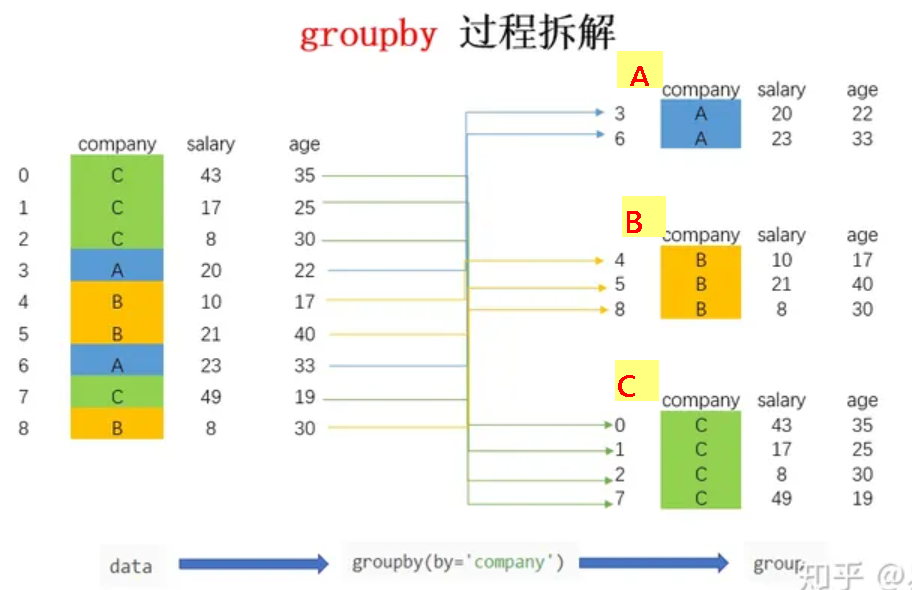 groupby結構示意圖2 groupby結構示意圖3 groupby結構示意圖4 groupby結構示意圖5 (3)分群後的統計數量,統計圖: 正解:統計分群數量(series): df.groupby('性別').size() 柱狀圖:df.groupby('性別').size().plot(kind="bar") (不是首選)統計分群數量(df): df.groupby('gender').count() (4)性別分群後,統計(男生)的數量,有2種方法: df.groupby('性別').count()['男']) df.groupby('性別').get_group('男') (5)性別分群後,統計(男生數學)的最大值,有2種方法: (A).逆法:用['數學]取得最高分後,再逆取['男']子群 df.groupby('性別')['數學'].max()['男'] (B).順法:用get_group('男'),順取男生子群,然後取數學['數學'].max()最高分 df.groupby('性別').get_group('男')['數學'].max() (6)一維series分群的方法,有4種: #第1種: df['性別'].value_counts() :相同數值的數目(Series) #第2種: df['性別'].unique() :相同的幾類資料(Series) #第3種: df['性別'].nunique() :m數值,種類數目(number) #第4種: df.groupby('性別') |
|||||
|
📣chp8-4.(分2群)多層分群,多層索引鍵分析的2種方法
☎重要性:多層分群是『交叉分析,樞紐分析』的基礎 ☎解法:多層索引鍵分析,有2種方法 ☎方法1:用groupby(["分群1","分群2"]) ☎方法2:先設定2層索引鍵,再用df.xs("社會組",level="選組")跨層級查詢 |
|||||
| (1).多層分群方法1:用groupby(["分群1","分群2"]) | |||||
| 上課練習範例 | 8-4-1-二個層級的分析,三個層級的分析 | 8-4-2-多層級分析,比較2個方法:df.groupby vs df.xs() | |||
| (1).多層分群方法2:先設定2層索引鍵,再用df.xs("社會組",level="選組")跨層級查詢 | |||||
| 上課練習範例 | 8-4-3-設定2層列索引鍵,查男生+社會組的資料,查男生+社會組的數學分數 | 8-4-4-把『外層,內層列索引鍵』對調,以外層列索引鍵排序,取消設定列索引鍵 | 8-4-5-跨層級的資料索引,直接查詢內層列索引鍵:查社會組+數學分數 | ||
|
☎chp8-5.(分2群)交叉分析表,樞紐分析表
☎重要性:商業數據分析,一個重要的目的:就是要分析不同參數之間的彼此關係 ☎方法:必須先建立『樞紐分析表』(交叉分析表),然後再繪圖這個樞紐分析表,就可以達成分析目的 ☎指令1:用groupby...unstack法 ☎指令2:pivot_table法 |
|||||
| ☎(1)樞紐分析表的必要指令:展開unstack(把列索引鍵調換成欄索引),堆疊收合stack(把欄索引鍵調換成列索引) | |||||
| 上課練習範例 | 8-5-1-樞紐分析表的必要指令unstack:把列索引鍵調換成欄索引 | ||||
| ☎(2)建立樞紐分析表的2種方法:groupby...unstack法,pivot_table法 | |||||
| 上課練習範例 | 8-5-2-建立樞紐分析表方法1:groupby...unstack法 | 8-5-3-建立樞紐分析表方法2:pivot_table法 | |||
|
☎chp8-6.Groupby分群分析的5種題型 # ☎Groupby分群數據分析的五種型態:y=f(x,y) (1)型態1:(1個分群,1組統計次數)的頻數分析【1變數x: size=f(x)】 (2)型態2:(2個分群,1組對應統計次數)的樞紐分析表,交叉分析圖【2變數x,y: size=f(x,y)】 (3)型態3:(2個分群,1組對應)之樞紐分析表,交叉分析圖【3變數x,y,z: z=f(x,y)】 (4)型態4:(1個分群,2組對應)之分析表/圖【3變數x,y1,y2: y1=f1(x), y2=f2(x),y1y2不同群組不同刻度】 (5)型態5:(1個分群,3xn組對應新增欄位(mean,max,min))之對應分析表/圖【4變數x,y1,y2,y3: y1=mean(x), y2=max(x), y3=min(x),y1y2y3不同群組不同刻度】 |
|||||
| ☎(1)型態1:(1個分群,1組統計次數)的頻數分析【1變數x: size=f(x)】 |
|||||
| 型態1:3種方法: 方法1:dfnew = df['入學年份'].value_counts() 方法2:dfnew = df.groupby('入學年份')[欄位].size() 方法3:df.groupby('入學年份').agg({"欄位":"size"}) |
|||||
| 上課練習範例 | 8-6-1-分析不同『入學年份,性別』的人數統計 | ||||
| ☎(2)型態2:(2個分群,1組對應統計次數)的樞紐分析表,交叉分析圖【2變數x,y: size=f(x,y)】 |
|||||
| 型態2:2種方法: 方法1:dfnew =df.groupby(['入學年份','性別']).size().unstack(level='性別') 方法2:df.pivot_table(index='入學年份', columns='性別', values='名字', aggfunc=len) #分群: dfnew = df.groupby(['入學年份','性別']).size() #樞紐分析表: dfnew = df.groupby(['入學年份','性別']).size().unstack(level='性別') #交叉分析圖: df.groupby(['入學年份','性別']).size().unstack(level='性別').plot(kind='bar') |
|||||
| 上課練習範例 | 8-6-2.型態2:分析不同入學年份,男女的人數統計:groupby...unstack法 | 8-6-3-型態2:分析不同入學年份,男女的人數統計:pivot_table法 | |||
| ☎(3)型態3:(2個分群,1組對應)之樞紐分析表,交叉分析圖【3變數x,y,z: z=f(x,y)】 |
|||||
| 型態3: #分群: dfnew = df.groupby(['業務單位','銷售產品'])['銷售金額'].sum() #樞紐分析表: dfnew = df.groupby(['業務單位','銷售產品'])['銷售金額'].sum().unstack(level='銷售產品') #交叉分析圖: df.groupby(['業務單位','銷售產品'])['銷售金額'].sum().unstack(level='銷售產品').plot(kind='bar') |
|||||
| 上課練習範例 | 8-6-4-型態3:顯示總和的樞紐分析表,交叉分析圖【3變數x,y,z: z=f(x,y)】 | ||||
| ☎(4)型態4:1個分群,2組對應分析表/圖【3變數x,y1,y2: y1=f1(x), y2=f2(x),y1y2不同類別不同刻度】 |
|||||
| 型態4: #同時設定左邊y軸,右邊y軸 ax1=df.groupby("業務單位").agg({"銷售金額":"sum","銷售數量":"sum"})\ .plot(kind="bar", legend=True, rot=0,secondary_y="銷售數量",title="Fig.1:不同業務單位的銷售金額與數量") ax1.set_xlabel("業務單位") ax1.set_ylabel('銷售金額') ax1.right_ax.set_ylabel('銷售數量') |
|||||
| 上課練習範例 | 8-6-5-型態4:不同業務單位的『銷售數量總和,銷售金額總和』對應表格與圖 | ||||
| ☎(5)型態5:(1個分群,3xn組對應新增欄位(mean,max,min))之對應分析表/圖【4變數x,y1,y2,y3: y1=mean(x), y2=max(x), y3=min(x),y1y2y3不同群組不同刻度】 |
|||||
| 型態5:2種方法 #方法1:dfnew = df.groupby('業務單位')[['銷售數量','銷售金額']].agg(['max','min','mean','sum']) #方法2:dfnew = df.groupby('業務單位').agg({"銷售數量":['max','min','mean','sum'],"銷售金額":['max','min','mean','sum']}) |
|||||
| 上課練習範例 | 8-6-6-顯示不同業務單位在銷售數量和銷售金額的min,max,mean,sum(用agg新增欄位) | ||||
|
☎☎☎chp8-7.樞紐分析表,交叉分析圖的花式變化與進階技巧 (1)型態1:計算總和+3種百分比表格➜可說出數據背後的3種物理意義,與定量比對 (2)型態2:分群『年,季,月,星期幾』➜看出時間效應,季節效應,月份效應,星期效應 (3)型態3:樞紐分析表的排序➜強項分析,弱項分析(最強的前3名,最弱的3名) (4)型態4:用apply熒光筆標註,樞紐分析表的顏色➜標註強項,弱項 (5)型態5:其它(數字千分位,上下圖,堆疊圖) |
|||||
| 上課練習範例 | 8-7-1-型態1:計算總和+3種百分比表格➜可說出數據背後的3種物理意義,與定量比對 | 8-7-2-型態2:分群『年,季,月,星期幾』➜看出時間效應,季節效應,月份效應,星期效應 | 8-7-3-型態3:樞紐分析表的排序➜強項分析,弱項分析 | 8-7-4-型態4:用apply熒光筆標註,樞紐分析表的顏色➜標註強項,弱項 | |
| 8-7-5.其它(數字千分位,上下圖,堆疊圖) | |||||
| chp9.各種資料清理方法:字串處理,正規表達式,日期處理,電話處理,Email處理,分割字串(常用於資料清理) | |||||
| chp9-1.字串處理:取第1字,最後2字,字串取代,關鍵字查詢,查詢有數字資料,文字長度 | |||||
| 上課練習範例 | 9-1-1-字串處理:取第1字,最後2字,字串取代,關鍵字查詢,查詢有數字資料,文字長度 | ||||
| chp9-2.正規表達式,Regular Expression | |||||
| 上課練習範例 | 9-2-1-應用1:正規表達式:取代名字裡的數字,印出姓,印出姓+稱呼(王先生) | ||||
|
(1)功能:能夠方便做『資料的清理:例如:字串處理,數字處理,日期處理,Email處理,電話處理』 各種格式的代表符號: (2)數字: 1個數字:\d 3個數字:\d\d\d 3個數字:\d{3} 很多個數字:\d+ (3)文字(含數字): 1個文字:\w 2個文字:\w\w,或\w{2} 很多個文字:\w* (4)文字(不含數字): 1個文字:[a-zA-Z] (5)出現特殊符號: 出現- : [-] 出現% : [%] 範例: 表示2023-10-15格式 : (\d+)-(\d+)-(\d+) (6){3}代表出現3次: 3個數字:\d{3} 3個文字:\w{3} (7) r,要求原始字串: 範例:df['name'].str.replace(r'\d', '') 這是因為正規表示式,會用到許多符號,可能會與 Python 內建的功能相衝突, 所以會在你需要的格式前面加上 r ,代表原始字串 raw (8) ():代表群組,可以取出,對照到逗點的輸出\1 對照:前面的第1個群組() ==> 取出後變成\1 對照:前面的第2個群組() ==> 取出後變成\2 範例:df['name'].str.replace(r'\w*(\d)', '\1') (把數字鍵,取出) 這是因為正規表示式,會用到許多符號,可能會與 Python 內建的功能相衝突, 所以會在你需要的格式前面加上 r ,代表原始字串 raw (9)正規表達式常常配合2個函數 (a).取代函數:df.str.replace(r'', r'') (b).截取函數:df.str.extract(r'') (10)extract函數: 功能:會根據()幾個群組,就自動分成幾個欄位 範例:df2 = df['birth'].astype(str).str.extract(r'(\d+)-(\d+)-(\d+)') 分析:因為有3個(\d+),所以extract,會根據()3個群組,就自動分成3個欄位 (11)replace函數: 使用正規表達式,前面3個() () ()群組,對應後面的3個\1 \2 \3 【正確做法】:df2 = df['birth'].astype(str).str.replace(r'(\d+)-(\d+)-(\d+)', r'\1年\2月\3日') 【原理】:df['birth']的日期型態是datetime資料,所以要先轉成文字資料:astype(str) 注意:取代replace()函數,是建立在文字的格式上才能取代(df[].str.replace('','') (12)把dataFrame的資料形態,轉換的函數: 轉成str格式:df['birth'].astype(str) 參考網頁 (13)特別注意:讀取日期欄位後,其資料型態是datatime,不是Object,也不是str: 方法:轉成str格式:df['日期'].astype(str) 結論:讀取日期後,一定要轉成str |
|||||
| chp9-3.截取日期,取代函數.str.replace(r'',r''),截取函數.str.extract(r'') | |||||
| 上課練習範例 | 9-3-1-截取日期:三種方法把【birth】格式改成2002年5月19日 | 9-3-2-截取日期:str.extract函數截取【birth】,成為年月日三個欄位 | |||
| chp9-4.截取電話 | |||||
| 上課練習範例 | 9-4-1-截取電話:正規式取出區號,正規式取出電話號碼(沒有區碼),正規式取出區碼+電話號碼(刪除()-符號) | 9-4-2-截取電話:replace正規式取出:[03]:2355-2391 | |||
| chp9-5.截取Email | |||||
| 上課練習範例 | 9-5-1-修改gamil改回gmail,關鍵字查全部gmail,刪除Email方法1(replace),刪除Email方法2(extract) | ||||
| chp9-6.分析興趣(split分割函數)( | |||||
| 上課練習範例 | 9-6-1-str.split分割函數:使用參數expand=True,將各種興趣hobby分割出來 | ||||
|
chp13.需要寫SQL語法的連線mySQL:pymysql --- SQL語法與Pandas的指令對照 |
|||||
| 摘要 | 1.SQL語法與Pandas對照 | 2.SQL語法摘要 | |||
| 下載 | 1.架站安裝mySQL:Wamp | 2.架站安裝mySQL:Xampp | 下載ch09資料庫,安裝到mySQL上 | ||
| 建立mySQL資料庫 | 1.將ch09.sql轉成ch09資料庫 | 2.將有欄位名稱Excel檔案轉成mySQL資料庫 | 3.將無欄位名稱Excel檔案轉成mySQL資料庫 | ||
| 上課練習範例(colab) | 13-1-用sqlalchemy連資料庫,新增1資料表 | 13-2-讀取資料庫ch09, 讀取books全部資料 | 13-3-查詢,新增查詢的欄位(sum, mean, max, min) | 13-4-查詢姓名='麥克'的資料 | |
| 13-5-查詢有缺值的資料 | 13-6-排序,依照數學分數排序 | 13-7-印出前3筆,後3筆,印出全部資料 | 13-8-關鍵字查詢 | ||
| 13-9-查詢性別同類的數量groupby,查詢性別有幾種distinct | 13-10-計算男女的數學平均:groupby-agg | ||||
| 上課練習範例(anaconda spyder) | 13-1-用sqlalchemy連資料庫,新增1資料表 | 13-2-讀取資料庫ch09, 讀取books全部資料 | 13-3-查詢,新增查詢的欄位(sum, mean, max, min) | 13-4-查詢姓名='麥克'的資料 | |
| 13-5-查詢有缺值的資料 | 13-6-排序,依照數學分數排序 | 13-7-印出前3筆,後3筆,印出全部資料 | 13-8-關鍵字查詢 | ||
| 13-9-查詢性別同類的數量groupby,查詢性別有幾種distinct | 13-10-計算男女的數學平均:groupby-agg | ||||
| 1.建立第一個mySQL資料庫 | 1.建立第一個mySQL資料庫: |
||||
| 13-2.將有欄位名稱Excel檔案轉成mySQL資料庫 | 13-2.將Excel檔案轉成mySQL資料庫: |
||||
| 13-3.將無欄位名稱Excel檔案轉成mySQL資料庫 | 13-3.將無欄位名稱Excel檔案轉成mySQL資料庫 |
||||
|
|||||
| chp14.不需要寫SQL語法的連線mySQL:sqlalchemy | |||||
| 摘要 | 1.SQL語法與Pandas對照 | 2.SQL語法摘要 | |||
| 下載 | 1.架站安裝mySQL:Wamp | 2.架站安裝mySQL:Xampp | 下載ch09資料庫 | ||
| 建立mySQL資料庫 | 1.將ch09.sql轉成ch09資料庫 | 2.將有欄位名稱Excel檔案轉成mySQL資料庫 | 3.將無欄位名稱Excel檔案轉成mySQL資料庫 | ||
| 上課練習範例 | 14-1-用sqlalchemy連資料庫,新增1資料表 | 14-2-修改資料表(改約翰數學為59) | 14-3-刪除約翰的資料 | 14-4-新增1個欄位(歷史分數) | |
| 上課練習範例 | 14-5-新增1筆資料(新增amy的資料) | 14-6-SQLAlchemy查詢全部資料(不使用SQL語法,直接指定資料表) | |||
| 1.建立第一個mySQL資料庫 | 1.建立第一個mySQL資料庫: |
||||
| 14-2.將有欄位名稱Excel檔案轉成mySQL資料庫 | 14-2.將Excel檔案轉成mySQL資料庫: |
||||
| 14-3.將無欄位名稱Excel檔案轉成mySQL資料庫 | 14-3.將無欄位名稱Excel檔案轉成mySQL資料庫 |
||||
|
|||||
| chp22.實例:系所生源分析 | |||||
| chp22-1.實例:系所生源分析 | |||||
| 資料下載 | 1.範例資料庫:student.xls | ||||
| 1-將三組excel資料放在同一DataFrame | 22-1-成果圖 | 22-1-程式碼 | |||
| 2-入學年份人數統計表 | 22-2-成果圖 | 22-2-程式碼 | |||
| 3-入學年份人數統計圖 | 22-3-成果圖 | 22-3-程式碼 | |||
| 4-不同入學年份的男女人數統計表 | 22-4-成果圖 | 22-4-程式碼 | |||
| 5-不同入學年份的男女人數統計圖 | 22-5-成果圖 | 22-5-程式碼 | |||
| 6-不同畢業學校的人數統計表 | 22-6-成果圖 | 22-6-程式碼 | |||
| 7-不同畢業學校的人數統計圖 | 22-7-成果圖 | 22-7-程式碼 | |||
| 8-不同入學管道的人數統計表 | 22-8-成果圖 | 22-8-程式碼 | |||
| 9-不同入學管道的人數統計圖 | 22-9-成果圖 | 22-9-程式碼 | |||
| 10-不同入學年份,不同入學管道的人數比較表(1) | 22-10-成果圖 | 22-10-程式碼 | |||
| 11-不同入學年份,不同入學管道的人數比較表(2) | 22-11-成果圖 | 22-11-程式碼 | |||
| 12-不同入學年份,不同入學管道的人數比較圖 | 22-12-成果圖 | 22-12-程式碼 | |||
| 13-讀取學校地區表 | 22-13-成果圖 | 22-13-程式碼 | |||
| 14-入學資料加上註明地區的欄位 | 22-14-成果圖 | 22-14-程式碼 | |||
| 15-顯示合併後出現缺值的數量 | 22-15-成果圖 | 22-15-程式碼 | |||
| 16-統計入學新生所在縣市 | 22-16-成果圖 | 22-16-程式碼 | |||
| 17-統計入學新生所在縣市圖(排序,高到低,前10) | 22-17-成果圖 | 22-17-程式碼 | |||
| 18-統計入學新生所在地區的人數表 | 22-18-成果圖 | 22-18-程式碼 | |||
| 19-入學新生所在地區的人數比較圖 | 22-19-成果圖 | 22-19-程式碼 | |||
| 20-不同地區,不同縣市的人數比較圖 | 22-20-成果圖 | 22-20-程式碼 | |||
| 21-不同入學年份,不同地區的人數比較表 | 22-21-成果圖 | 22-21-程式碼 | |||
| 22-不同入學年份,不同地區的人數比較圖 | 22-22-成果圖 | 22-22-程式碼 | |||
| 23-不同地區,不同入學年份的人數比較圖 | 22-23-成果圖 | 22-23-程式碼 | |||
| chp23.實例:業務銷售分析 | |||||
| chp23-1.實例:業務銷售分析 | |||||
| 資料下載 | 1.範例資料庫:sales.csv | ||||
| 1-顯示前5筆 | 23-1-成果圖 | 23-1-程式碼 | |||
| 2-顯示業務單位有幾個? | 23-2-成果圖 | 23-2-程式碼 | |||
| 3-比較不同業務單位的銷售金額(總和) | 23-3-成果圖 | 23-3-程式碼 | |||
| 4-比較不同業務單位的銷售數量(總和),銷售金額(總和) | 23-4-成果圖 | 23-4-程式碼 | |||
| 5-比較不同業務單位的銷售數量(總和),銷售金額(總和),反白標註最大值 | 23-5-成果圖 | 23-5-程式碼 | |||
| 6-比較不同業務單位的銷售數量(總和),銷售金額(總和),反白標註最小值 | 23-6-成果圖 | 23-6-程式碼 | |||
| 7-比較不同業務單位的銷售數量(總和),銷售金額(總和),紅色標註金額的最大值 | 23-7-成果圖 | 23-7-程式碼 | |||
| 8-比較不同業務單位的銷售數量(總和),銷售金額(總和),反白標註全部的銷售金額 | 23-8-成果圖 | 23-8-程式碼 | |||
| 9-圖形比較不同業務單位的銷售數量(總和),銷售金額(總和) | 23-9-成果圖 | 23-9-程式碼 | |||
| 10-圖形比較不同業務單位的銷售數量(總和),銷售金額(總和),左右2個y軸 | 23-10-成果圖 | 23-10-程式碼 | |||
| 11-2個子圖比較不同業務單位的銷售數量(總和),銷售金額(總和) | 23-11-成果圖 | 23-11-程式碼 | |||
| 12-不同業務單位,不同業務員的銷售金額(總和)比較 | 23-12-成果圖 | 23-12-程式碼 | |||
| 13-【難】輸出到excel,依據不同業務單位,建立4個sheet | 23-13-成果圖 | 23-13-程式碼 | |||
| 14-【難】輸出到excel,並繪製圖形 | 23-14-成果圖 | 23-14-程式碼 | |||
| 15-不同業務員的銷售金額比較(由高到低) | 23-15-成果圖 | 23-15-程式碼 | |||
| 16-【難】不同業務單位下,每一個業務員的銷售金額比較(由高到低) | 23-16-成果圖 | 23-16-程式碼 | |||
| 17-【難】排序業務單位(低到高),再排序每一個業務員的銷售金額(由高到低) | 23-17-成果圖 | 23-17-程式碼 | |||
| 18-找出每個業務單位,業務員的最高銷售金額 | 23-18-成果圖 | 23-18-程式碼 | |||
| 19-找出每個業務單位,業務員的最高銷售金額(顯示業務員姓名) | 23-19-成果圖 | 23-19-程式碼 | |||
| 20-找出每個業務單位,業務員的Top 2銷售金額(顯示業務員姓名) | 23-20-成果圖 | 23-20-程式碼 | |||
| 21-找出每個業務單位,業務員的最低銷售金額(顯示業務員姓名) | 23-21-成果圖 | 23-21-程式碼 | |||
| 22-【難】找出每個業務單位,業務員的最高銷售金額(顯示業務員姓名) | 23-22-成果圖 | 23-22-程式碼 | |||
| 23-【難】列出每個業務單位,每個業務員的銷售金額(反白標註最高金額) | 23-23-成果圖 | 23-23-程式碼 | |||
| 24-列出不同業務單位,不同銷售產品的銷售金額比較表 | 23-24-成果圖 | 23-24-程式碼 | |||
| 25-列出不同業務單位,不同銷售產品的銷售金額比較表(pivot_table) | 23-25-成果圖 | 23-25-程式碼 | |||
| 26-【難】列出不同業務單位,不同銷售產品的銷售金額比較表(數字加上千分位) | 23-26-成果圖 | 23-26-程式碼 | |||
| 27-繪圖出不同業務單位,不同銷售產品的銷售金額比較 | 23-27-成果圖 | 23-27-程式碼 | |||
| 28-【難】輸出表格到excel,並繪圖出不同業務單位,不同銷售產品的銷售金額比較 | 23-28-成果圖 | 23-28-程式碼 | |||
| 29-繪圖出不同業務單位,不同銷售產品的銷售金額(堆疊圖比較) | 23-29-成果圖 | 23-29-程式碼 | |||
| 30-列出不同業務單位,不同銷售產品的銷售金額比較表,加上總和欄位,累計每個產品的總和(方法1:pivot_table) | 23-30-成果圖 | 23-30-程式碼 | |||
| 31-列出不同業務單位,不同銷售產品的銷售金額比較表,加上業務銷售總和欄位+累計每個產品的總和(方法2:用axis=1) | 23-31-成果圖 | 23-31-程式碼 | |||
| 32-列出不同業務單位,不同銷售產品的銷售金額比較表,加上銷售產品總和index(方法3:用axis=0) | 23-32-成果圖 | 23-32-程式碼 | |||
| 33-【難】列出不同業務單位,不同銷售產品的銷售金額%百分比比較表(全部的銷售單位的所有銷售產品總和為100%) | 23-33-成果圖 | 23-33-程式碼 | |||
| 34-【難】列出不同業務單位,不同銷售產品的銷售金額%百分比比較表(全部的銷售單位的所有銷售產品總和為100%) | 23-34-成果圖 | 23-34-程式碼 | |||
| 35-【難】列出不同業務單位,不同銷售產品的銷售金額%百分比比較表(每一樣銷售產品總和為100%) | 23-35-成果圖 | 23-35-程式碼 | |||
| 36-【難】列出不同業務單位,不同銷售產品的銷售金額%百分比比較表(每一個的銷售單位的總和為100%) | 23-36-成果圖 | 23-36-程式碼 | |||
| 37-列出不同業務單位,不同人員,對不同銷售產品的銷售金額比較表 | 23-37-成果圖 | 23-37-程式碼 | |||
| 38-列出不同業務單位,不同人員,對不同銷售產品的銷售金額比較表(pivot_table) | 23-38-成果圖 | 23-38-程式碼 | |||
| 39-列出不同業務單位,不同產品,的不同『銷售數量,銷售金額』比較表(pivot_table) | 23-39-成果圖 | 23-39-程式碼 | |||
| 40-列出不同業務單位,其銷售數量的max/min/mean/sum,銷售金額的max/min/mean/sum | 23-40-成果圖 | 23-40-程式碼 | |||
| 41-列出不同業務單位,其銷售數量的mean,銷售金額的sum | 23-41-成果圖 | 23-41-程式碼 | |||
| 42-新增欄位『年』 | 23-42-成果圖 | 23-42-程式碼 | |||
| 43-新增欄位『月』 | 23-43-成果圖 | 23-43-程式碼 | |||
| 44-新增欄位『季』 | 23-44-成果圖 | 23-44-程式碼 | |||
| 45-新增欄位『星期幾』 | 23-45-成果圖 | 23-45-程式碼 | |||
| 46-顯示每一年的銷售總金額 | 23-46-成果圖 | 23-46-程式碼 | |||
| 47-顯示每一年的銷售總金額(方法2) | 23-47-成果圖 | 23-47-程式碼 | |||
| 48-繪圖每一年的銷售總金額 | 23-48-成果圖 | 23-48-程式碼 | |||
| 49-不同月的銷售總金額 | 23-49-成果圖 | 23-49-程式碼 | |||
| 50-每一年的不同產品的銷售總金額比較 | 23-50-成果圖 | 23-50-程式碼 | |||
| 51-每一年的不同產品的銷售總金額繪圖比較 | 23-51-成果圖 | 23-51-程式碼 | |||
| 52-不同『季』的銷售總金額 | 23-52-成果圖 | 23-52-程式碼 | |||
| 53-不同『年的四季』銷售總金額比較 | 23-53-成果圖 | 23-53-程式碼 | |||
| 54-比較『2015,2016』年的銷售次數比較 | 23-54-成果圖 | 23-54-程式碼 | |||
| 55-【難】比較『2015,2016』年四季,不同業務單位的銷售金額比較 | 23-55-成果圖 | 23-55-程式碼 | |||
| 56-比較『2015,2016』年四季,業務單位1的銷售金額柱狀圖 | 23-56-成果圖 | 23-56-程式碼 | |||
| 57-比較『季報』2015,2016年,業務單位1的銷售金額總量 | 23-57-成果圖 | 23-57-程式碼 | |||
| 58-繪圖比較『季報』2015,2016年,業務單位1的銷售金額總量 | 23-58-成果圖 | 23-58-程式碼 | |||
| chp24.實例:股票市場分析 | |||||
| chp24-1.實例:台積電,聯發科的股票線型 | |||||
| 資料下載 | 1.範例資料庫:stock.xlsx | ||||
| 上課練習範例 | |||||
| chp25.實例:問卷資料分析 | |||||
| chp25-1.實例:問卷資料分析 | |||||
| 資料下載 | 1.範例資料庫:ma_res.xlsx | ||||
| 上課練習範例 | |||||
| chp30.電商數據分析:淘寶服飾店3年數據 | |||||
| 下載 | 下載淘寶電商的營業數據 | ||||
| 上課練習範例 | 30-1 | ||||
|
|||||
| chp31.市場分析:市場佔有率分析(3年驅蟲劑市場分析) | |||||
| 下載 | 下載3年驅蟲劑市場數據 | ||||
| 上課練習範例 | 31-1-市場佔有率分析(3年驅蟲劑市場分析) | ||||
|
|||||
| chp32.市場分析:市場趨勢分析(3年驅蟲劑市場數據) | |||||
| 下載 | 下載3年驅蟲劑市場數據 | ||||
| 上課練習範例 | 32-1-市場趨勢分析 | ||||
|
|||||
| chp33.市場分析:市場細分分析(滅鼠殺蟲劑細分市場數據) | |||||
| 下載 | 下載3年滅鼠殺蟲劑細分市場數據 | ||||
| 上課練習範例 | 33-1-市場細分分析 | ||||
|
|||||
| chp34.市場分析:消費者需求分析 | |||||
| 下載 | 下載3年滅鼠殺蟲劑細分市場數據 | ||||
| 上課練習範例 | 34-1-消費者需求分析 | ||||
|
|||||
| chp35.運營分析:店鋪數據化運營的SEO關鍵字詞根與統計 | |||||
| 下載 | 下載淘寶服飾店的流量數據 | ||||
| 上課練習範例 | 35-1-淘寶服飾店流量的SEO關鍵字詞根與統計分析 | ||||
|
|||||
| chp36.運營分析:商品推廣方案分析 | |||||
| 下載 | |||||
| 上課練習範例 | 36-1-商品推廣方案分析 | ||||
|
|||||
| chp37.運營分析:競品分析(追踪競爭對手的SKU庫存價格) | |||||
| 下載 | 下載:對手的單品SKU價格 | 下載:對手的單品價格 | |||
| 上課練習範例 | 37-1-採集競爭對手網頁的庫存資料 | 37-2-競品調價預警 | |||
|
|||||