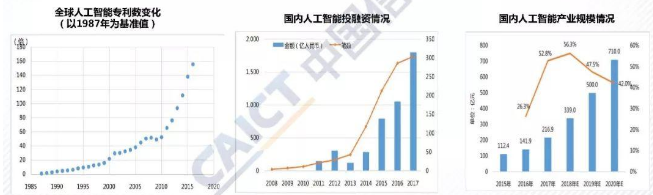
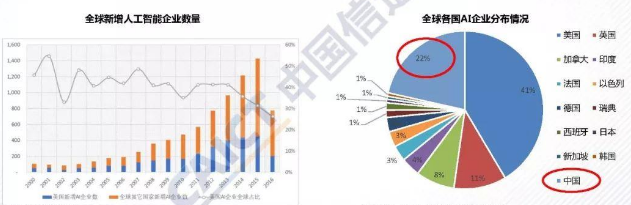
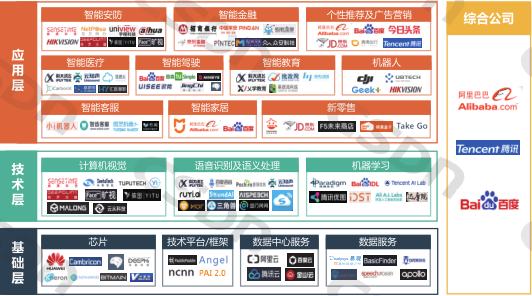
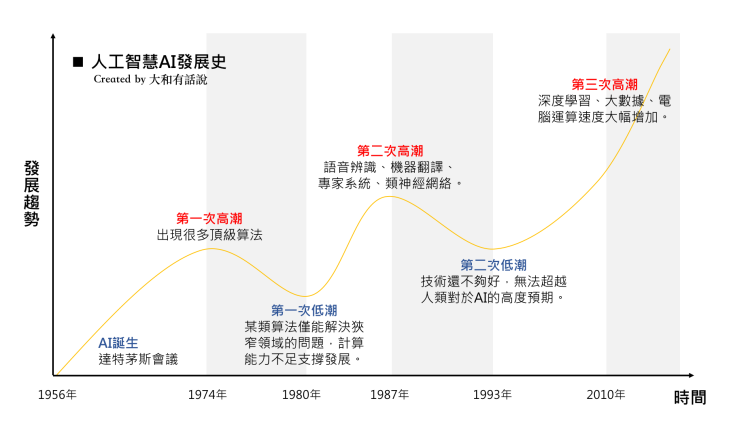
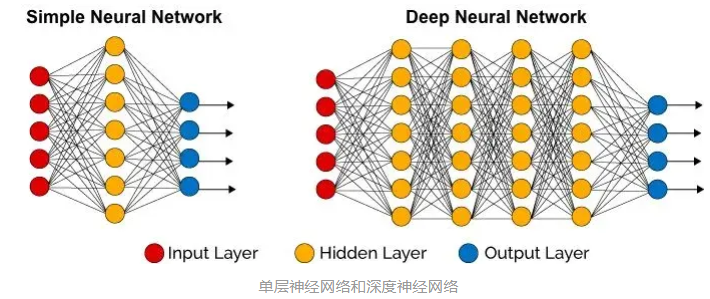
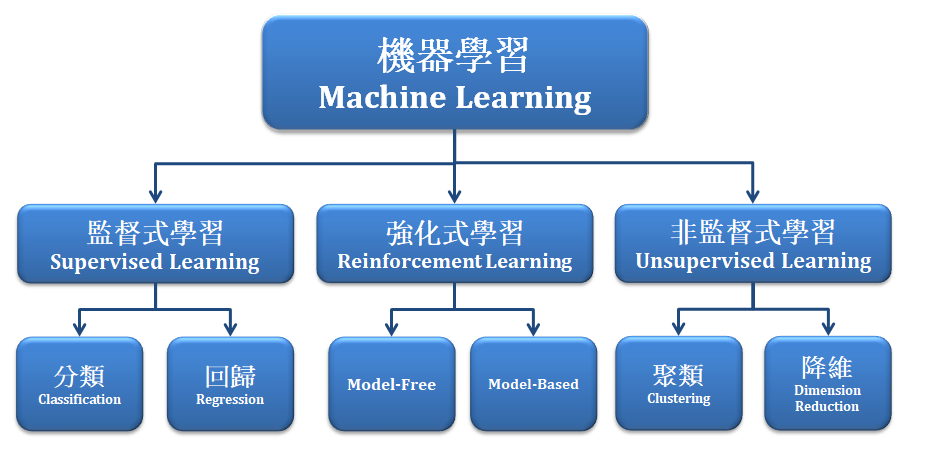
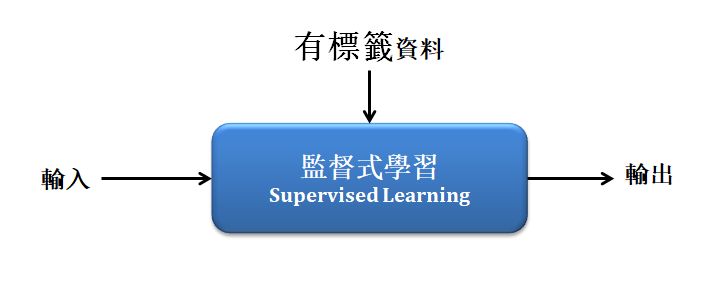
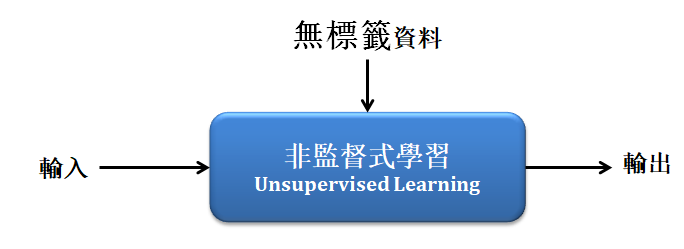
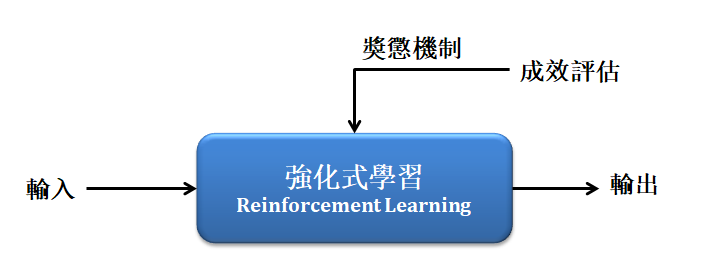
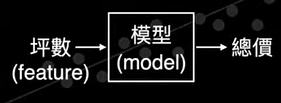
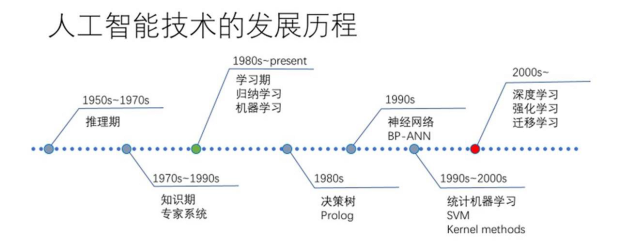
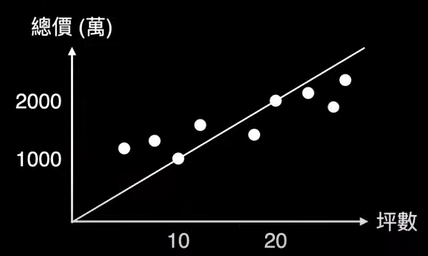
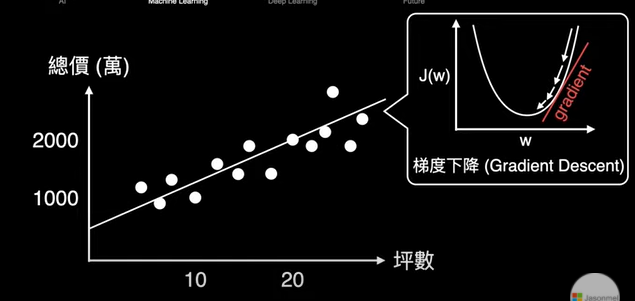
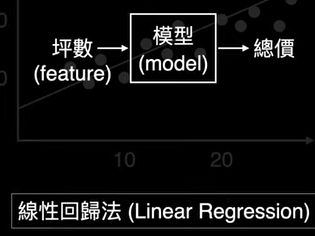
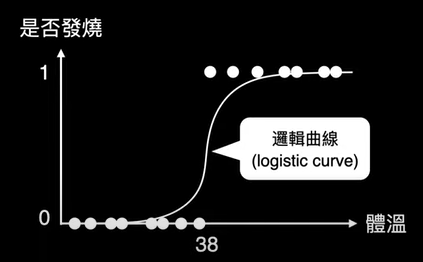
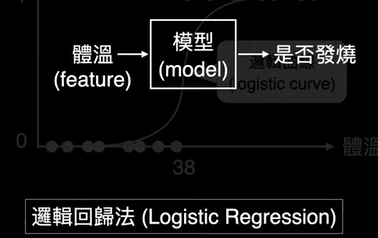
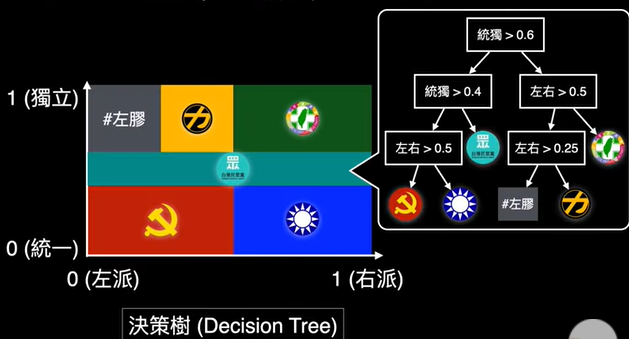
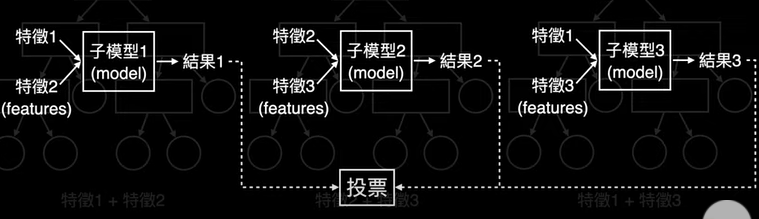
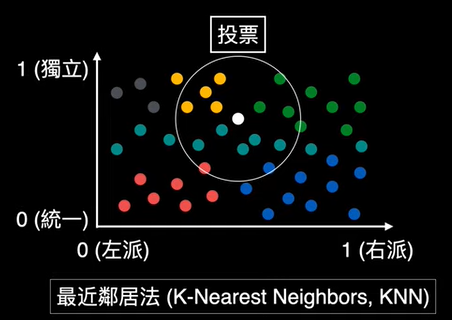
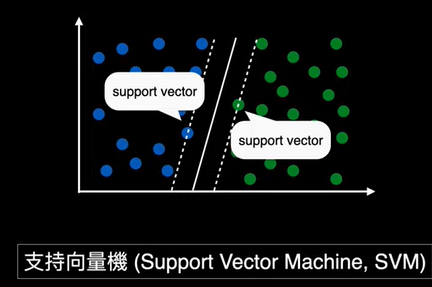
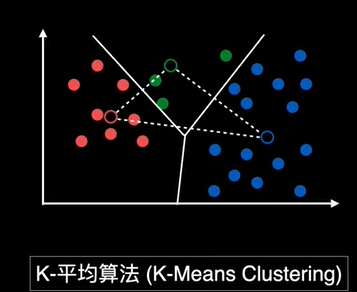
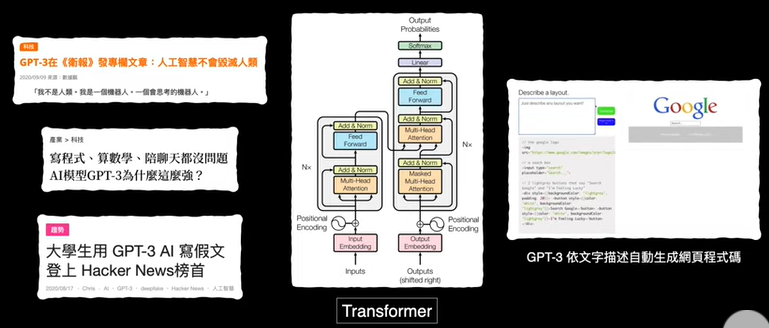
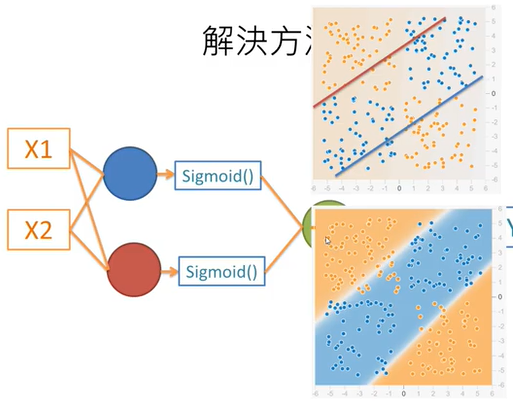
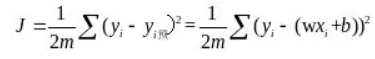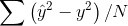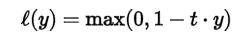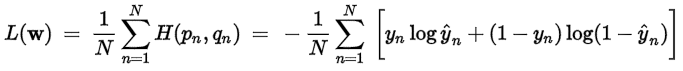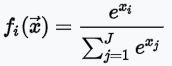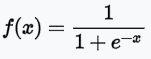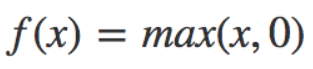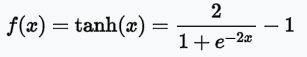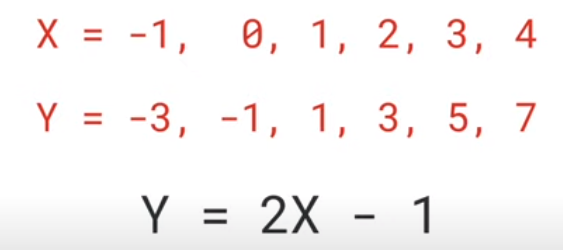chp8. keras簡介
目錄
1.keras簡介 2.Keras的神經網路訓練步驟 3.Keras每一步驟的指令與程式碼 4.keras提供三種快速搭建網路的方式
5.Sequential model 6.Functional API model 7.Model Subclassing 8.keras損失函數(Loss Function)的種類
9.Keras 激勵函數(Activation Function)的種類 10.Keras 優化函數(Optimizer)的種類
1
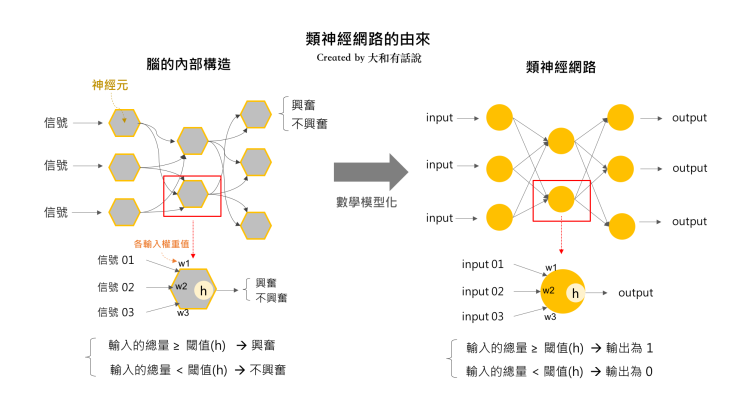
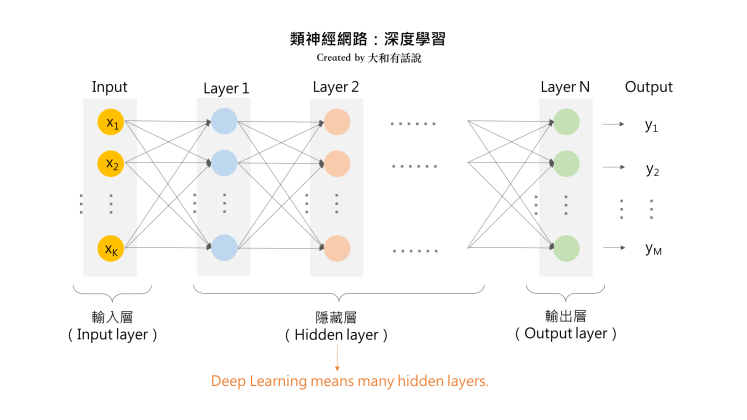
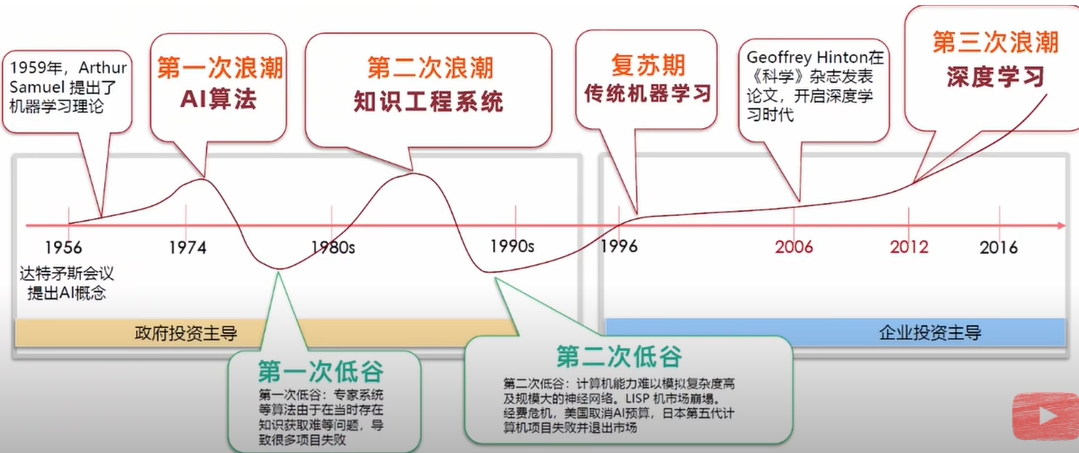
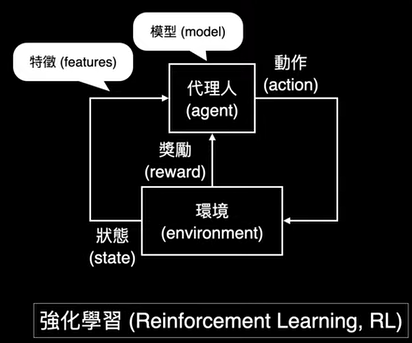
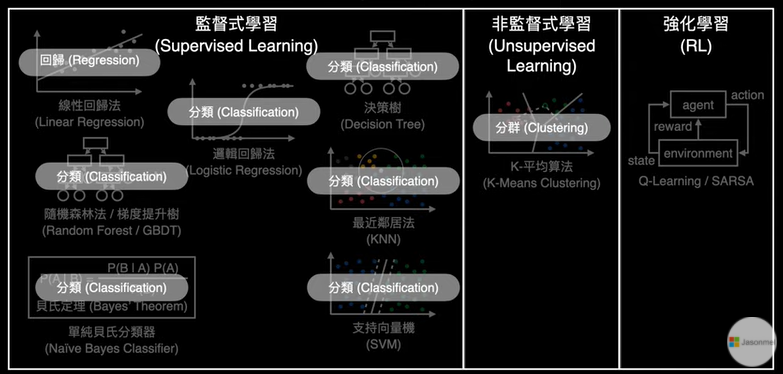
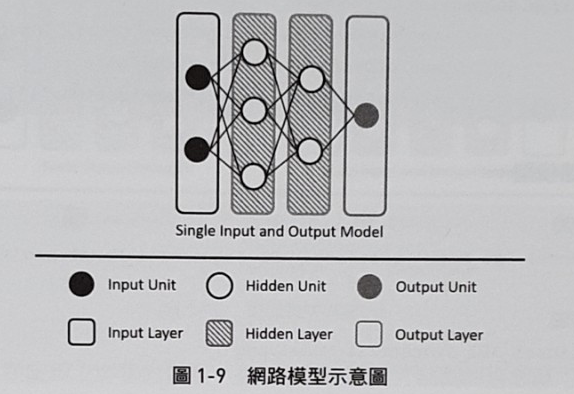
1.keras簡介
2
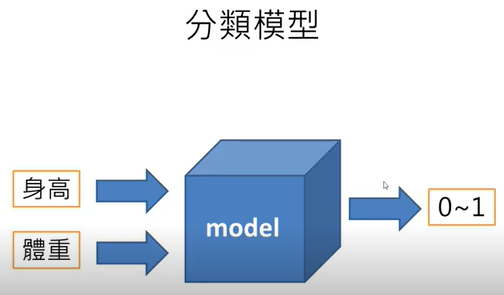
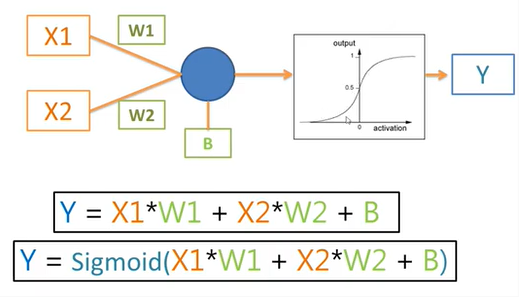
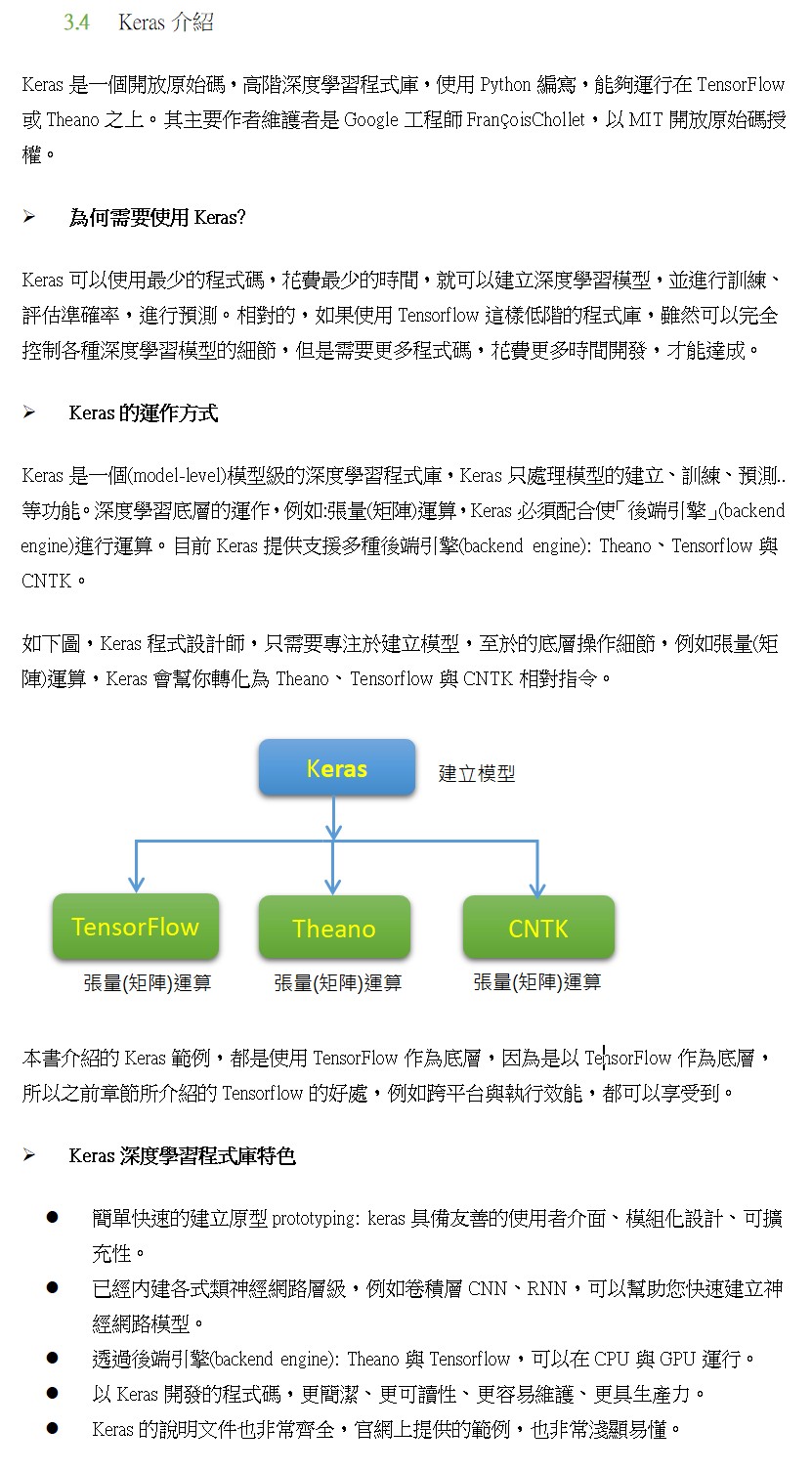
1.Keras 是一個用來降低機器學習程式設計門檻的專案,Keras 也整合許多符合商業和研究需求的高階API。透過這些API只需要幾行程式碼就能建構和執行非常複雜的神經網路
3.Keras每一步驟的指令與程式碼:
# 建立簡單的線性執行的模型
# 編譯: 選擇損失函數、優化方法及成效衡量方式
# 進行訓練, 訓練過程會存在 train_history 變數中
# 顯示訓練成果(分數)
# 預測(prediction) (參考來源文章)
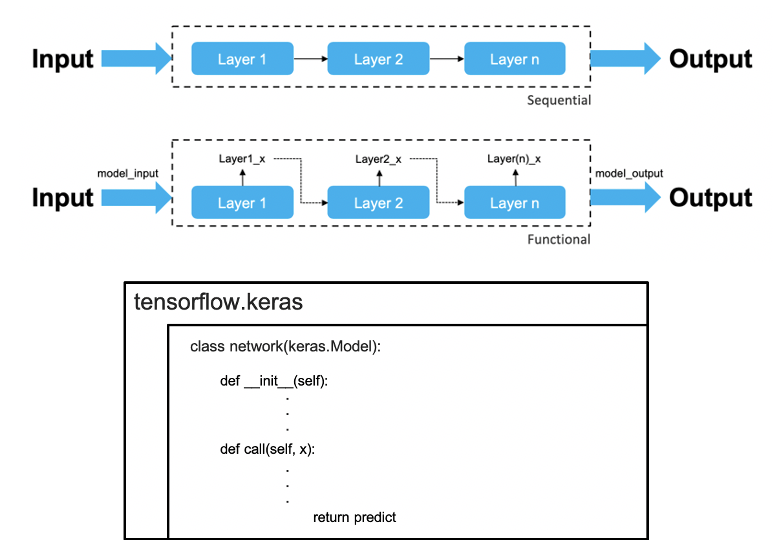
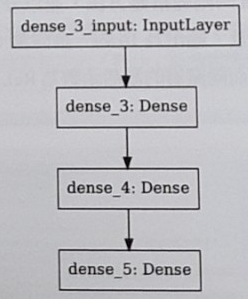
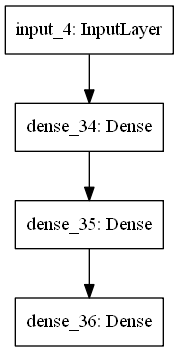
4.Keras的模型結構有三種方法
5.Sequential ModelSequential model教學範例 ,
6.Functional API model:
7.Model Subclassing:
8.Keras 損失函數(Loss Function)的種類:(參考來源文章)
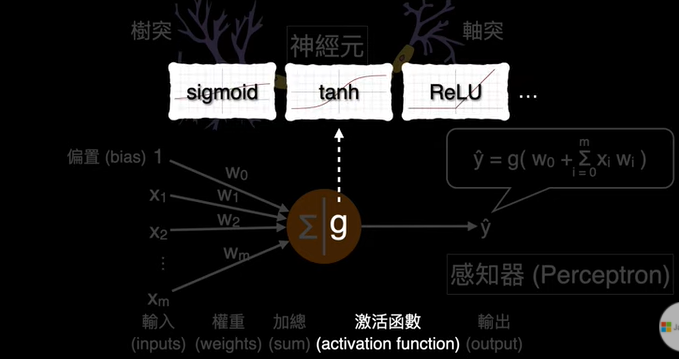
9.Keras 激勵函數(Activation Function)的種類:(參考來源文章)
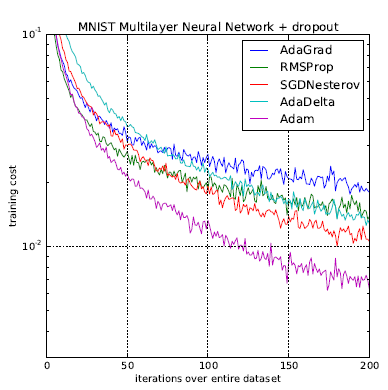
10.Keras 優化函數(Optimizer)的種類:(3-4)自適應學習率(Adagrad,Adadelta,RMSprop,Adam,AdaMax,Nadam) (3-4-d)Adam(**建議使用這個): 如果數據是稀疏的, 建議選用『自適應方法』:即Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta, Adam ☎整體來講,Adam 是最好的選擇。 如果需要更快的收斂,或者是訓練更深更複雜的神經網絡,建議選用『自適應的學習率』的方法。 (參考來源文章1) ,
(參考來源文章2)
chp9. 由keras的4個範例(簡易版)來認識人工智慧
目錄
1.TensorFlow官網的教學範例1:用1層神經網絡來做迴歸分析 2.TensorFlow官網的教學範例2:基本神經網絡深度學習模型 3.TensorFlow官網的教學範例3:卷積神經網絡模型 4.TensorFlow官網的教學範例4:識別剪刀石頭布Rock,Paper,Scissors
1.從一個範例來認識人工智慧(TensorFlow官網的教學範例1):用1層神經網絡來做迴歸分析教學影片 (中文)教學影片(英文) TensorFlow官網的教學範例1:找出數據的趨勢線
(9-1-1)練習範例(1):學習線性趨勢線(直線),預測x=10的y值?
數據點:成果圖片 程式碼 專案成果檔案.py ,
專案成果檔案.ipynb
(9-1-2)練習範例(2):學習線性趨勢線(直線),畫出數據點與預測點
數據點:AI的7步驟流程 ,
程式碼解答
(9-1-3)練習範例(3):學習非線性趨勢線(雙曲線),預測x=1.0的y值,畫出數據點與預測點
數據點:AI的7步驟流程 ,
程式碼解答
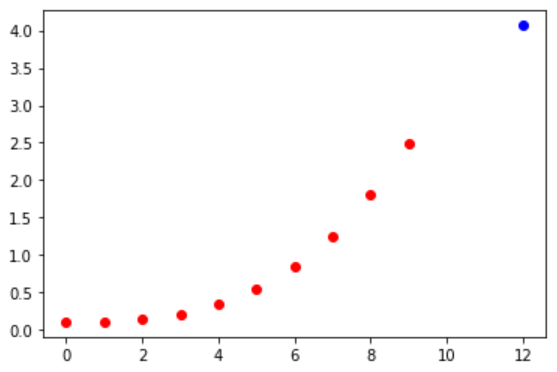
(9-1-4)練習範例(4):學習非線性趨勢線(拋物線),預測x=12的y值,畫出數據點與預測點
數據點:AI的7步驟流程 ,
程式碼解答
2.TensorFlow官網的教學範例2:基本神經網絡深度學習模型教學影片(中文) 教學影片(英文) TensorFlow官網的教學範例2:識別鞋子 官網教學: Classify images of clothing 成果圖片 ,
成果圖片 程式碼 專案成果檔案.py ,
專案成果檔案.ipynb
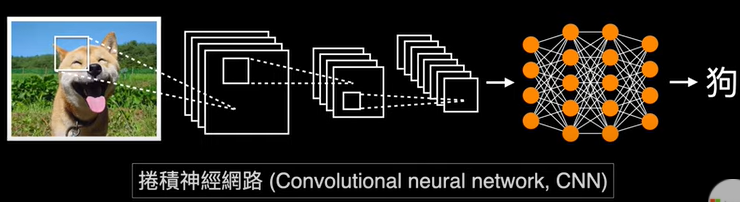
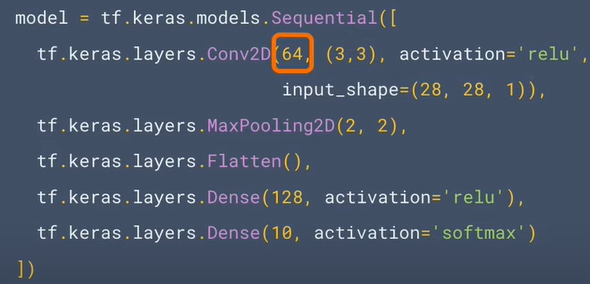
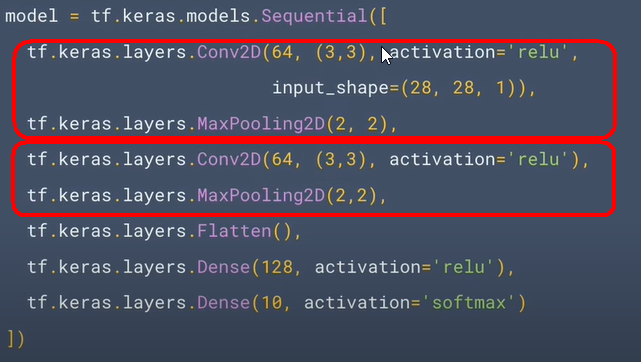
3.TensorFlow官網的教學範例3:卷積神經網絡模型的簡介(Introduction to Convolutions)教學影片 (中文)教學影片(英文) TensorFlow官網的教學範例2:識別鞋子 (1).How Convolutional Neural Networks work
VIDEO
model = tf.keras.models.Sequential([
model = tf.keras.models.Sequential([ 程式碼 專案成果檔案.py ,
專案成果檔案.ipynb
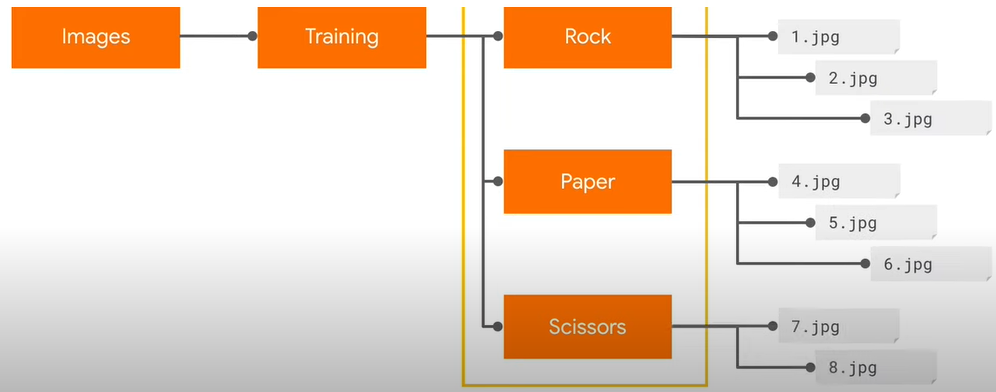
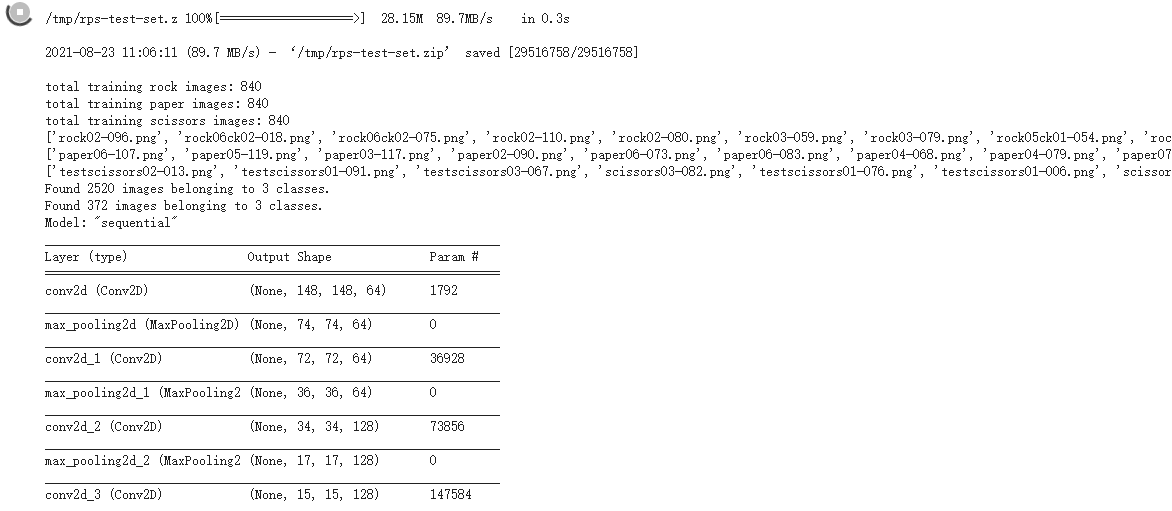
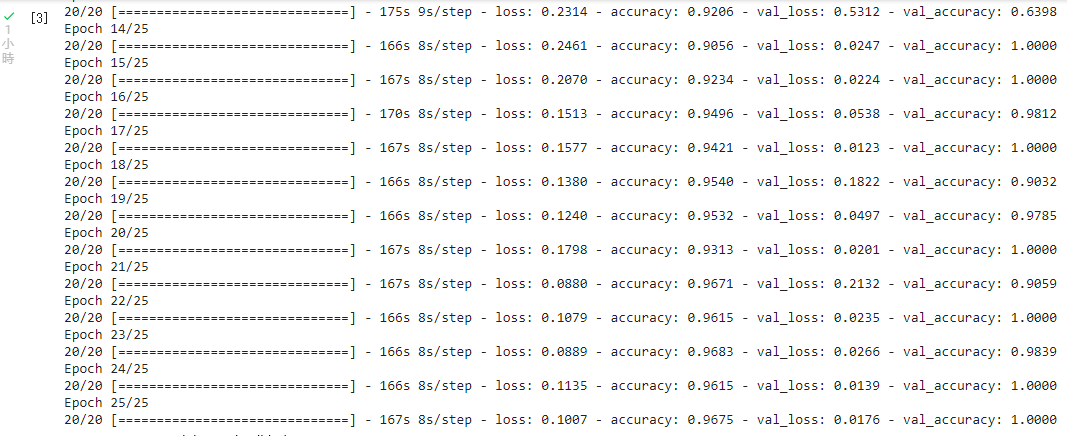
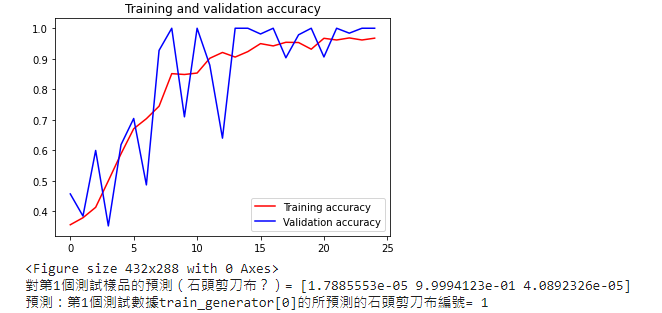
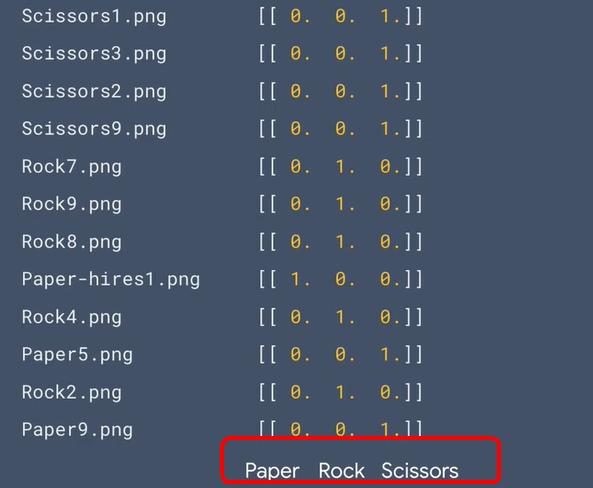
4.TensorFlow官網的教學範例4:識別剪刀石頭布Rock,Paper,Scissors教學影片 (中文)教學影片(英文) TensorFlow官網的教學範例4:識別剪刀石頭布Rock,Paper,Scissors Build convolutional neural networks (CNNs) to enhance computer vision 下載『剪刀石頭布』的資料集(Rock, paper, scissors dataset )
!wget --no-check-certificate \
import os
☎解壓縮產生的目錄:images-Training-Rock, Paper, Scissors
model = tf.keras.models.Sequential([
import numpy as np
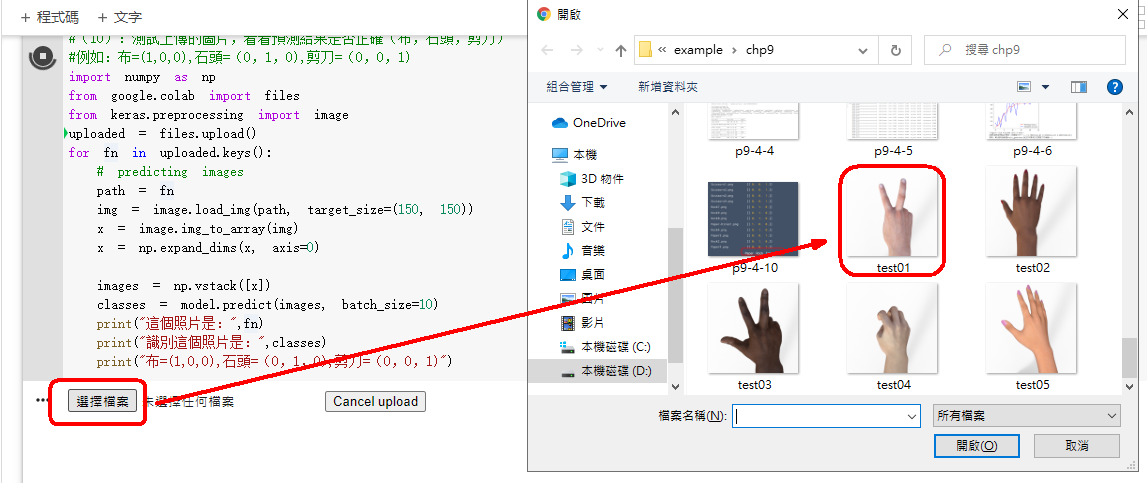
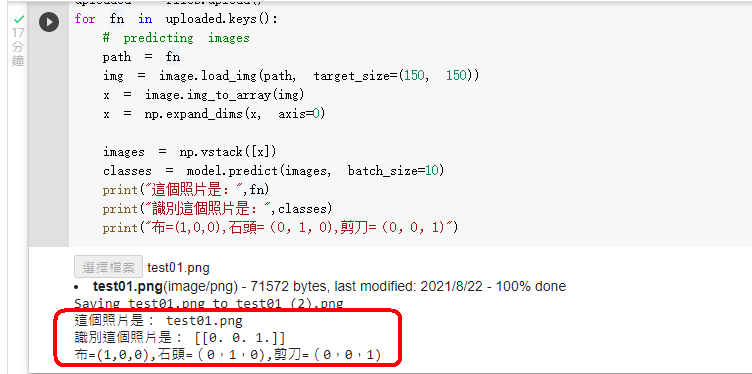
下載測試用的布石頭剪刀的圖片 卷積神經網絡程式碼 ,
上傳圖片程式碼 專案成果檔案.py ,
專案成果檔案.ipynb
chp10. keras多層感知器(MLP)
目錄
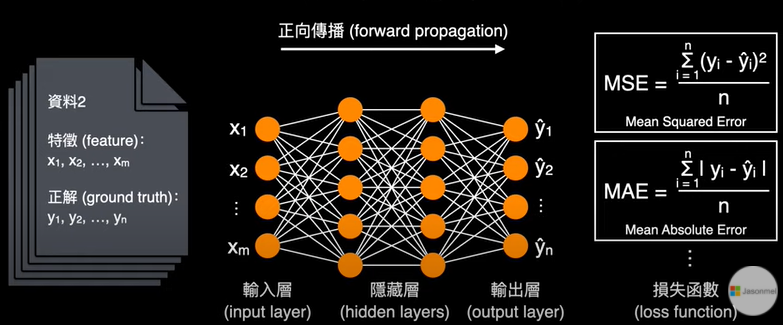
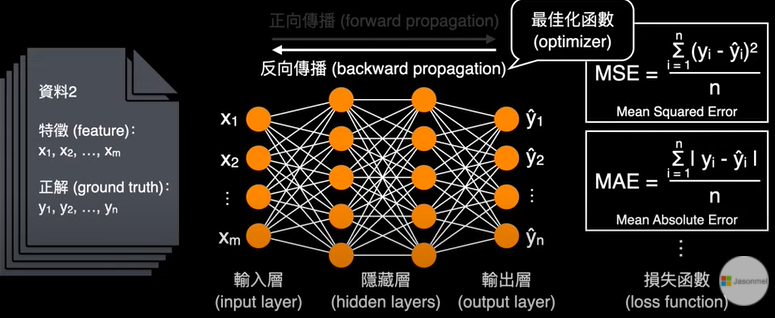
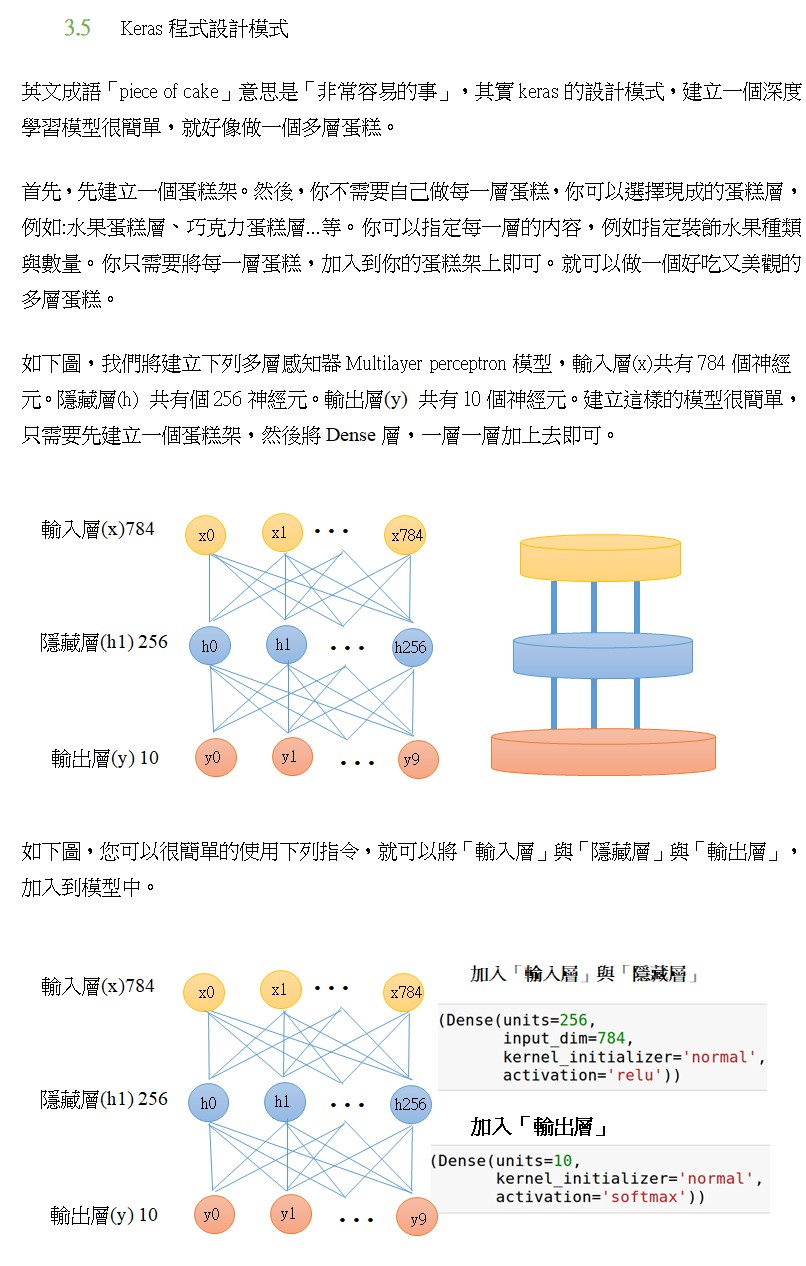
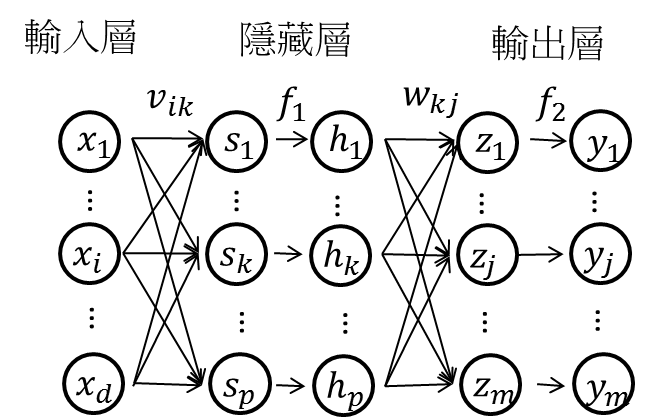
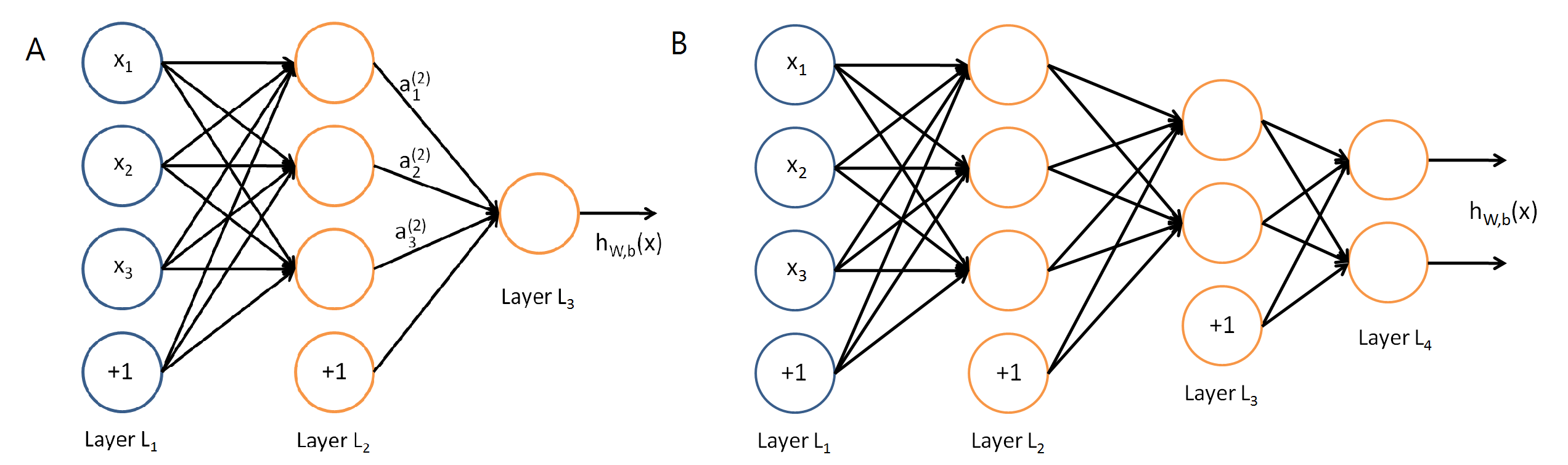
1.什麼是多層感知機 Multilayer perceptron, MLP 2.神經網絡隱藏層的神經元要設定多少 3.深度學習神經網絡的運作核心原理:找出最佳的參數(權重值w) 4.神經網絡的訓練每次迴圈的三步驟:前向傳遞,評估損失,反向傳遞
5.訓練迴圈是否越多越好:過度擬合/低度擬合(Overfit/underfit) 6.為什麼深度學習的神經元要用激勵函數/啟動函數/Activation 7.該使用哪一種激勵函數/Activation function? 8.該使用哪一種損失函數/Loss function?
9.樣本與標籤(samples/labels) 10.樣本要做哪些預處理 11.樣本的正規化與標準化(Normalization/Standardization) 12.樣本要切割成三份:『訓練用,驗證用,測試用』樣本
13.迴圈的設定:訓練週期Epochs,批次Batch,批次尺寸Batch Size,迭代數Iterations 14.Keras常用的2種深度學習模型models 15.常用的3種神經網絡類型types:MLP,CNN,RNN 範例10-1:基本圖片分類:Basic classification: Classify images of clothing
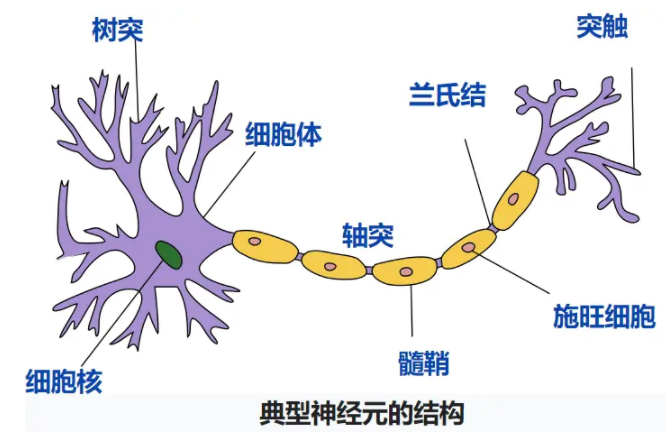
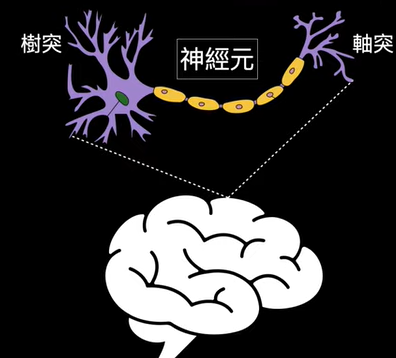
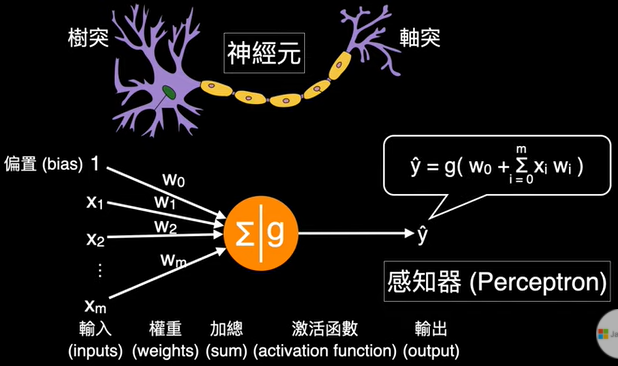
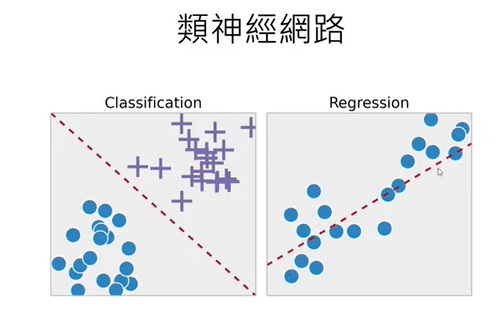
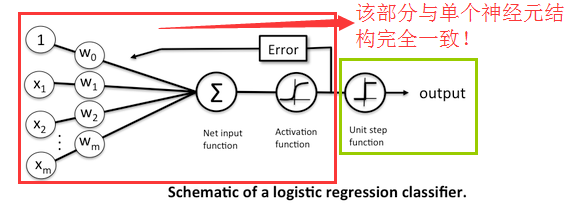
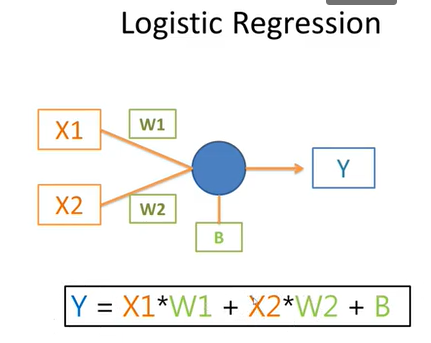
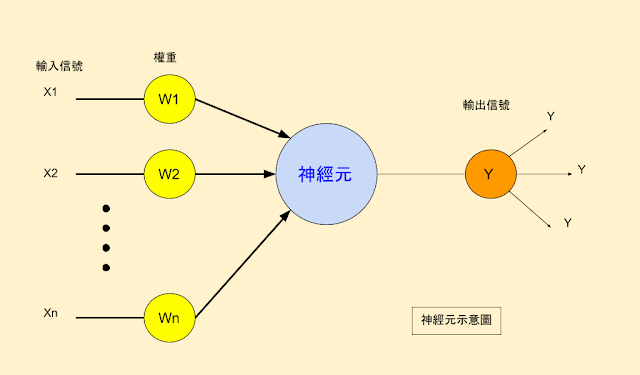
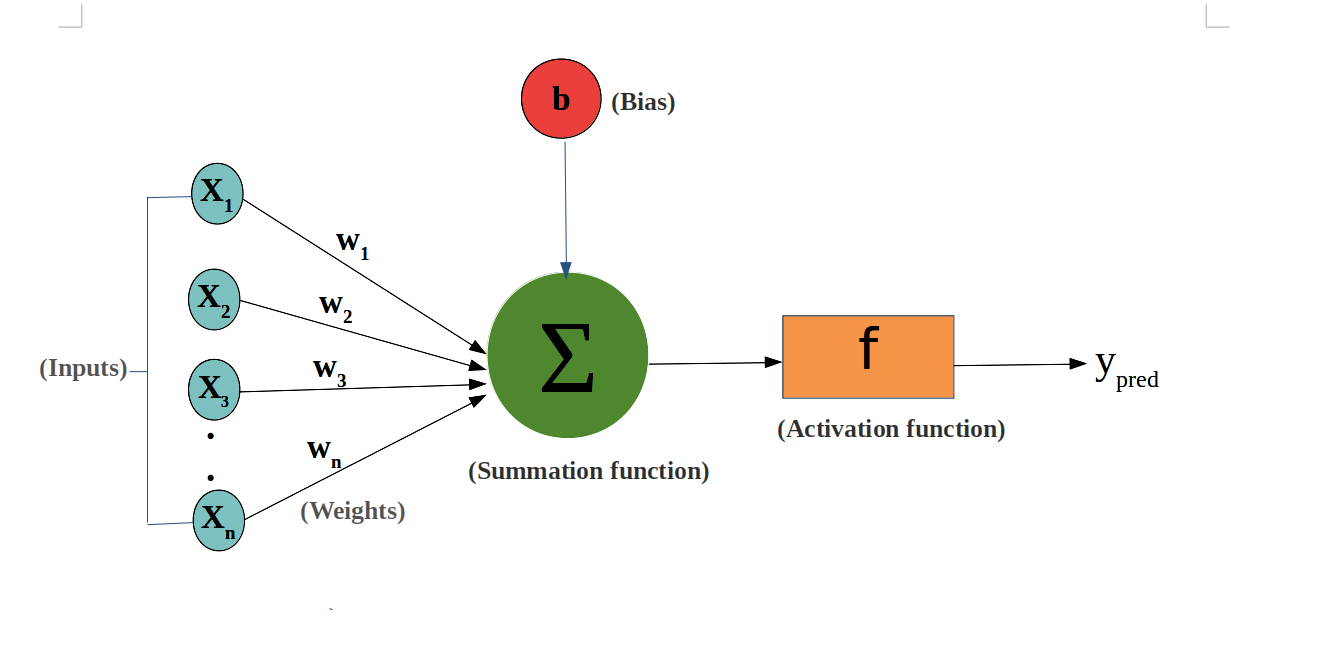
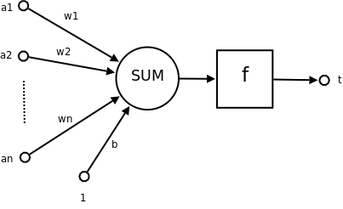
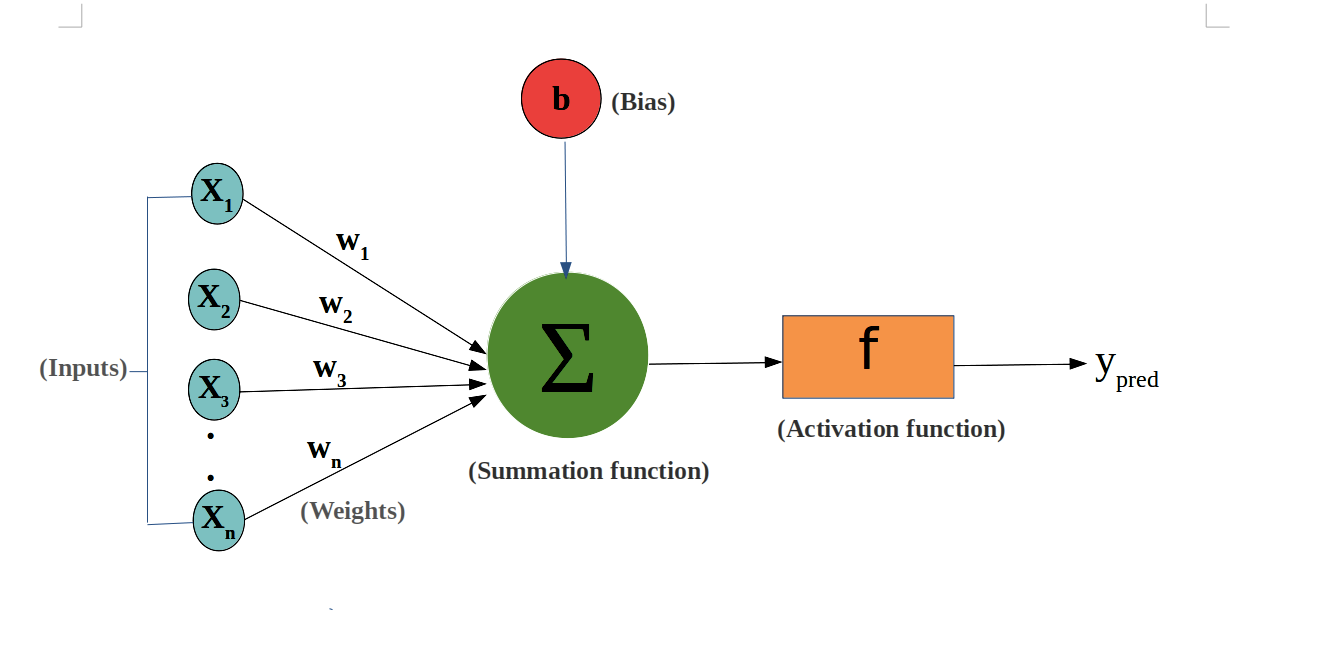
1.感知器(perceptron):就是神經元(neuron)
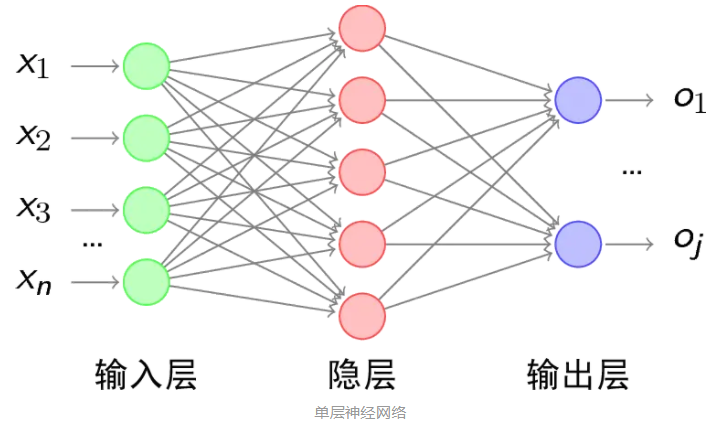
5.多層感知機MLP,就是類神經網絡模型(深度學習)的基本款
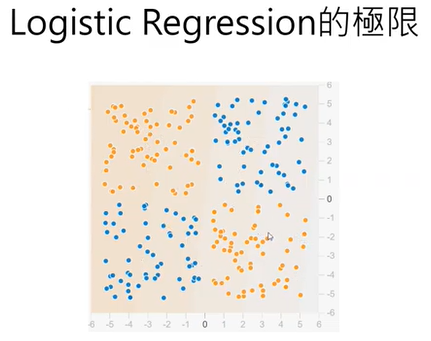
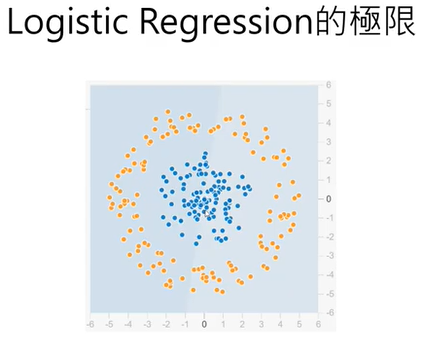
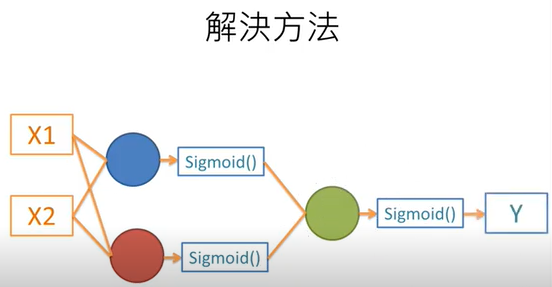
6.建構神經網絡的一個重要問題:隱藏層的神經元要設定多少?
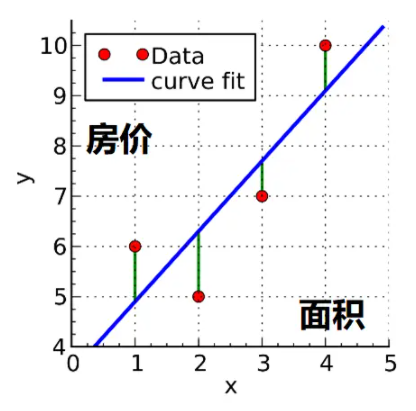
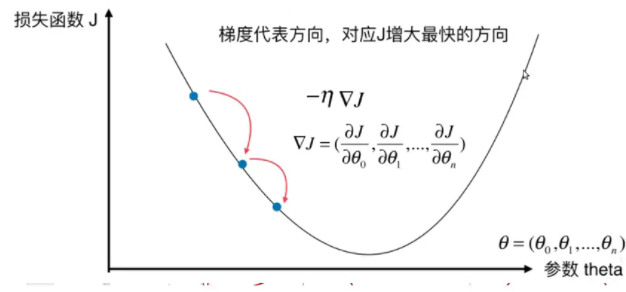
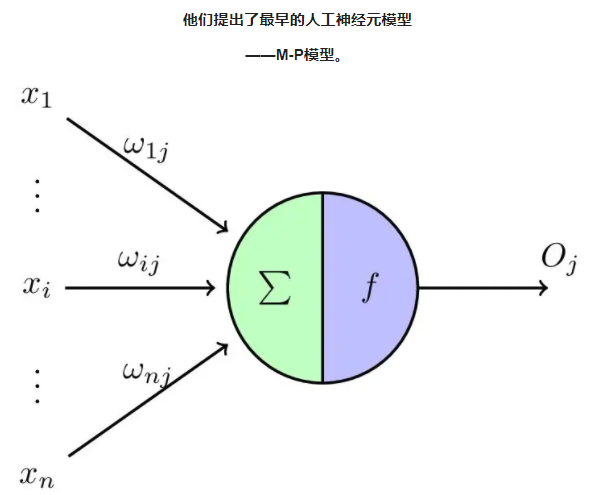
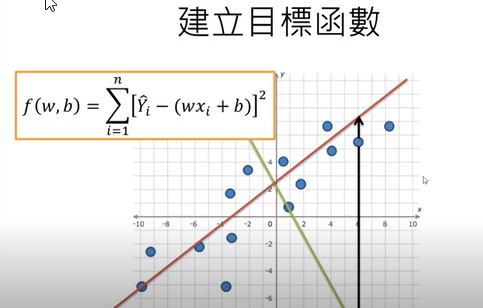
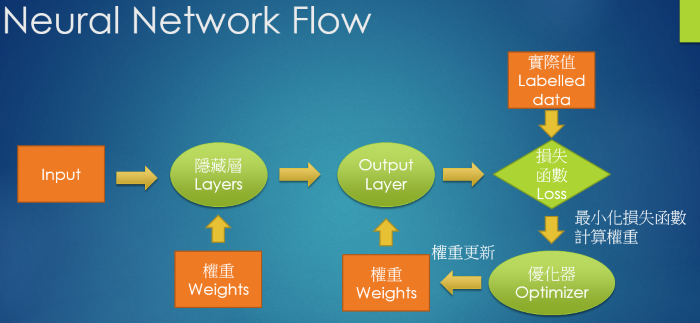
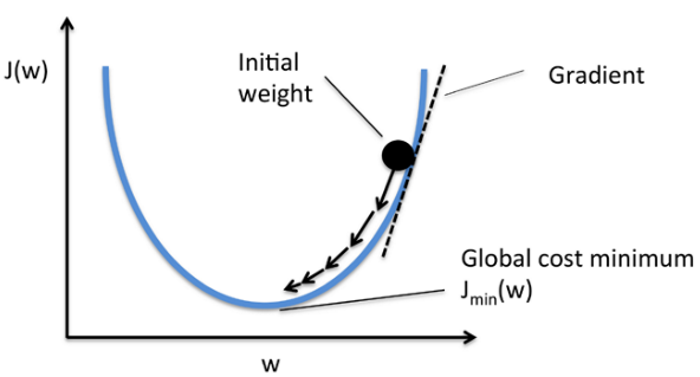
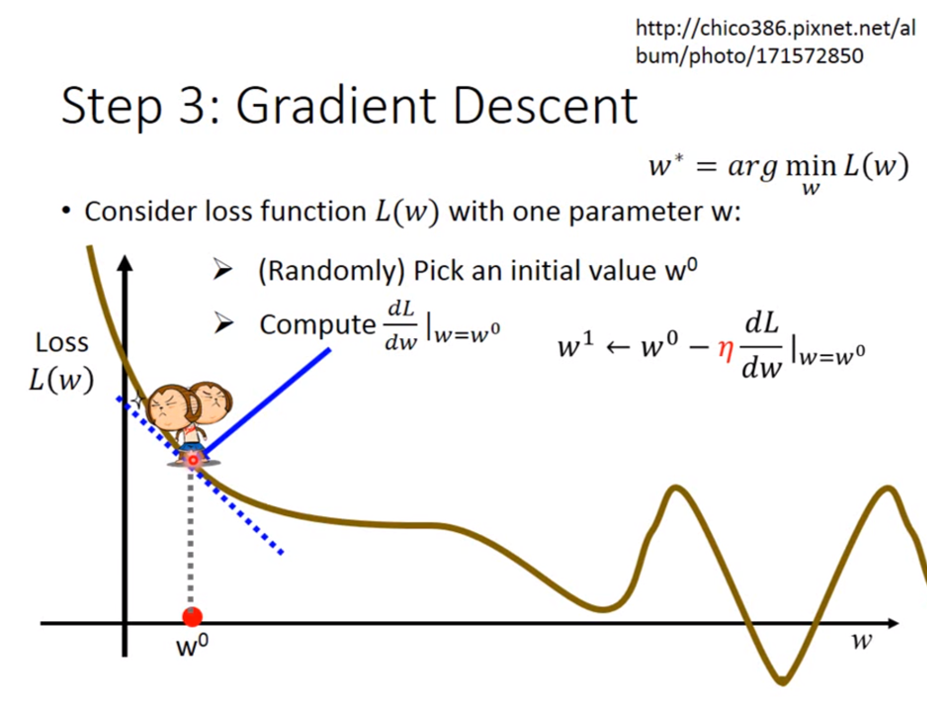
8.深度學習神經網絡的運作核心原理:找出最佳的參數(權重值w)
(1)深度學習,是在學習什麼呢?
影片教學:深度学习基础课程07 - 神经网络的损失函数 loss function
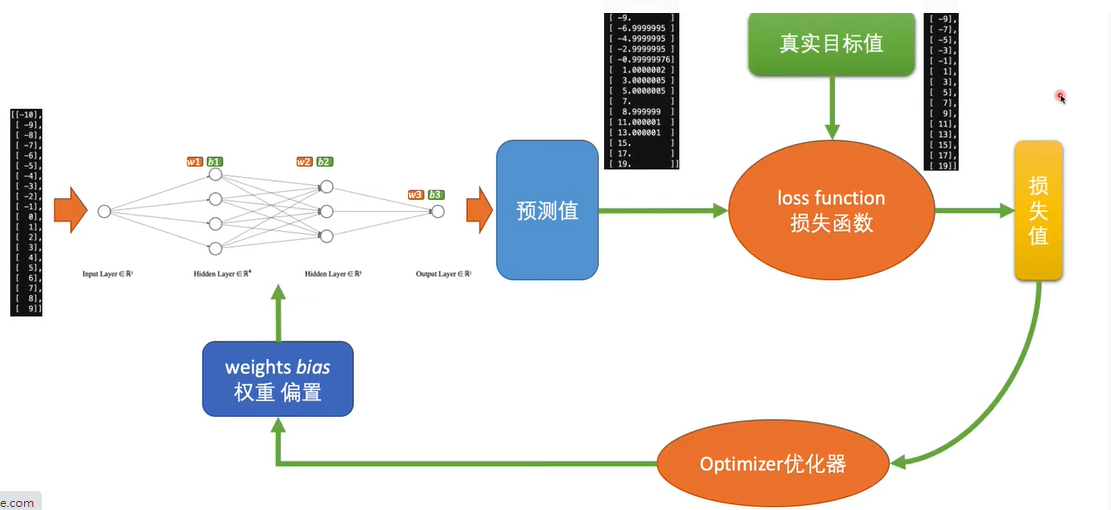
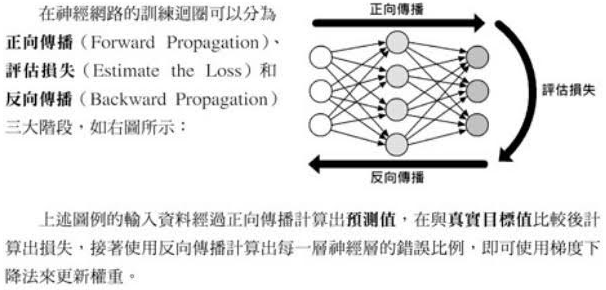
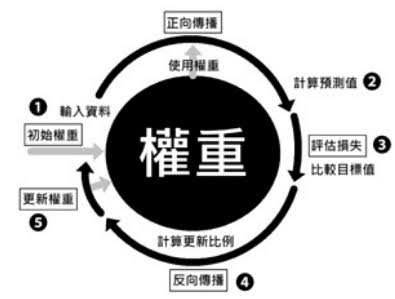
10.神經網絡的訓練每次迴圈的三步驟:前向傳遞,評估損失,反向傳遞
☎所以整個神經網絡的訓練學習,都是圍繞著調整『權重值w』,這是整個深度學習的關鍵核心探討主題所在
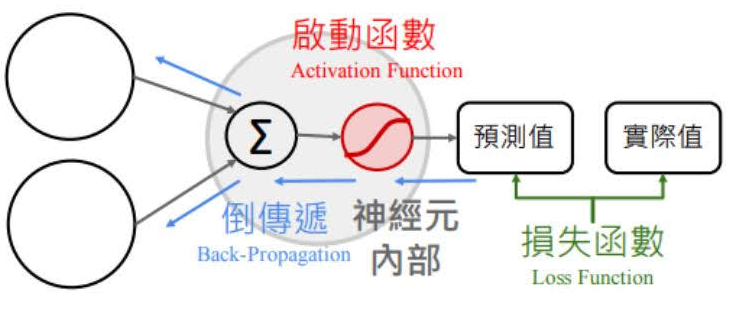
☎前向傳遞 (Forward propagation):輸入層到隱藏層
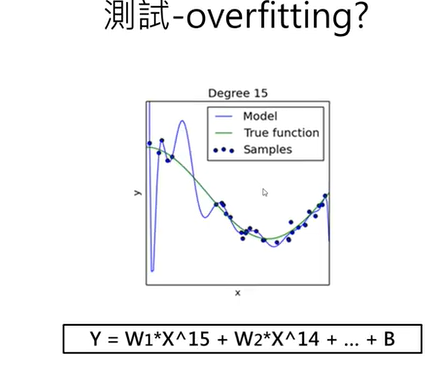
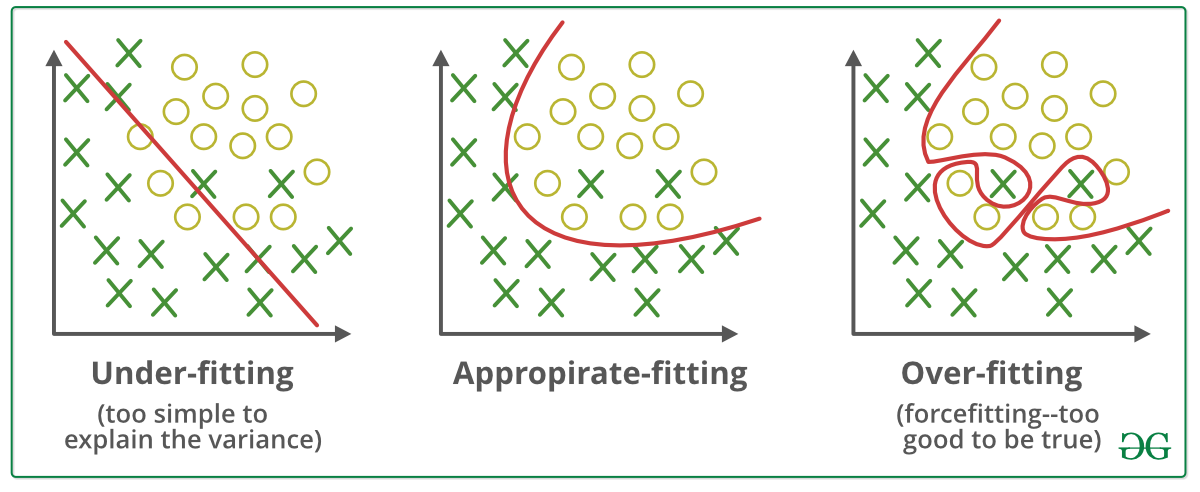
11.訓練迴圈次數是否越多越好:過度擬合/低度擬合(Overfit/underfit)
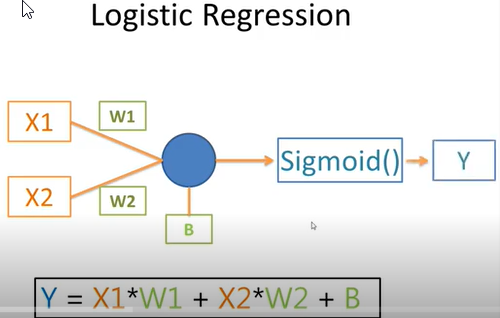
12.為什麼深度學習的神經元要用激勵函數/啟動函數/Activation
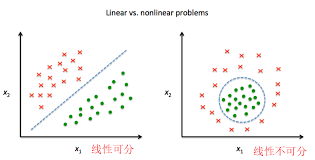
☎使用激勵函數的目的:讓神經網絡模型可以處理『非線性的資料轉換』
13.該使用哪一種:激勵函數/Activation function?
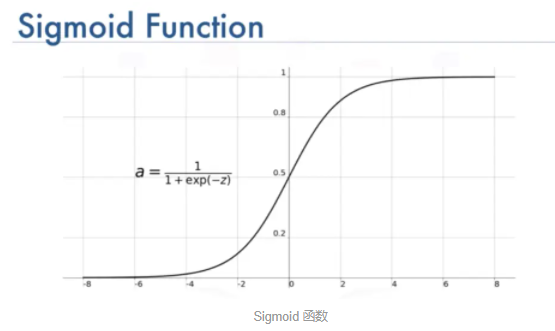
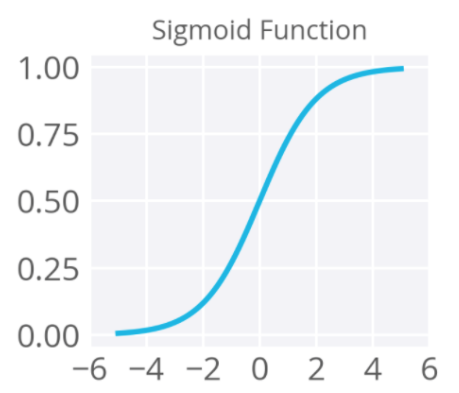
(2)現代『MLP,深度學習神經網絡』使用的激勵函數/Activation function是什麼
☎sigmoid的缺點:sigmoid函數的微分,會讓在反向傳播過程,只需要3~5層的summation後,就讓梯度=0,造成梯度消失問題。
☎範例:model.add(Dense(units=10, kernel_initializer='normal', activation='sigmoid'))
☎tanh函數的優點:雙曲函數是一種三角函數,對於神經網絡模型而言,它的優點是若有處理負值。
☎範例:model.add(Dense(units=10, kernel_initializer='normal', activation='tanh'))
☎ReLU的重要性:深度學習能夠重新被重視,重新引領風潮,就是因為當初AlexNet神經網絡,使用ReLU函數取代sigmoid函數,讓模型對圖片的識別率提高了15%。
☎範例:model.add(Dense(units=10, kernel_initializer='normal', activation='Relu'))
13.該使用哪一種損失函數/Loss function?
(13-2)該使用哪一種損失函數/Loss function?
14.什麼是樣本與標籤(samples/labels)
(13-2)該使用哪一種損失函數/Loss function?
15.樣本要做哪些預處理:
(15-1)樣本要做哪些預處理?
(15-2)為什麼要做『特徵標準化』?
(15-3)『特徵標準化』的兩種可行方法:
16.『特徵標準化』的兩種可行方法:正規化/Normalization,標準化/Standardization
(16-1)『特徵標準化』的兩種可行方法:
(16-2)正規化/Normalization:
(16-3)標準化/Standardization:
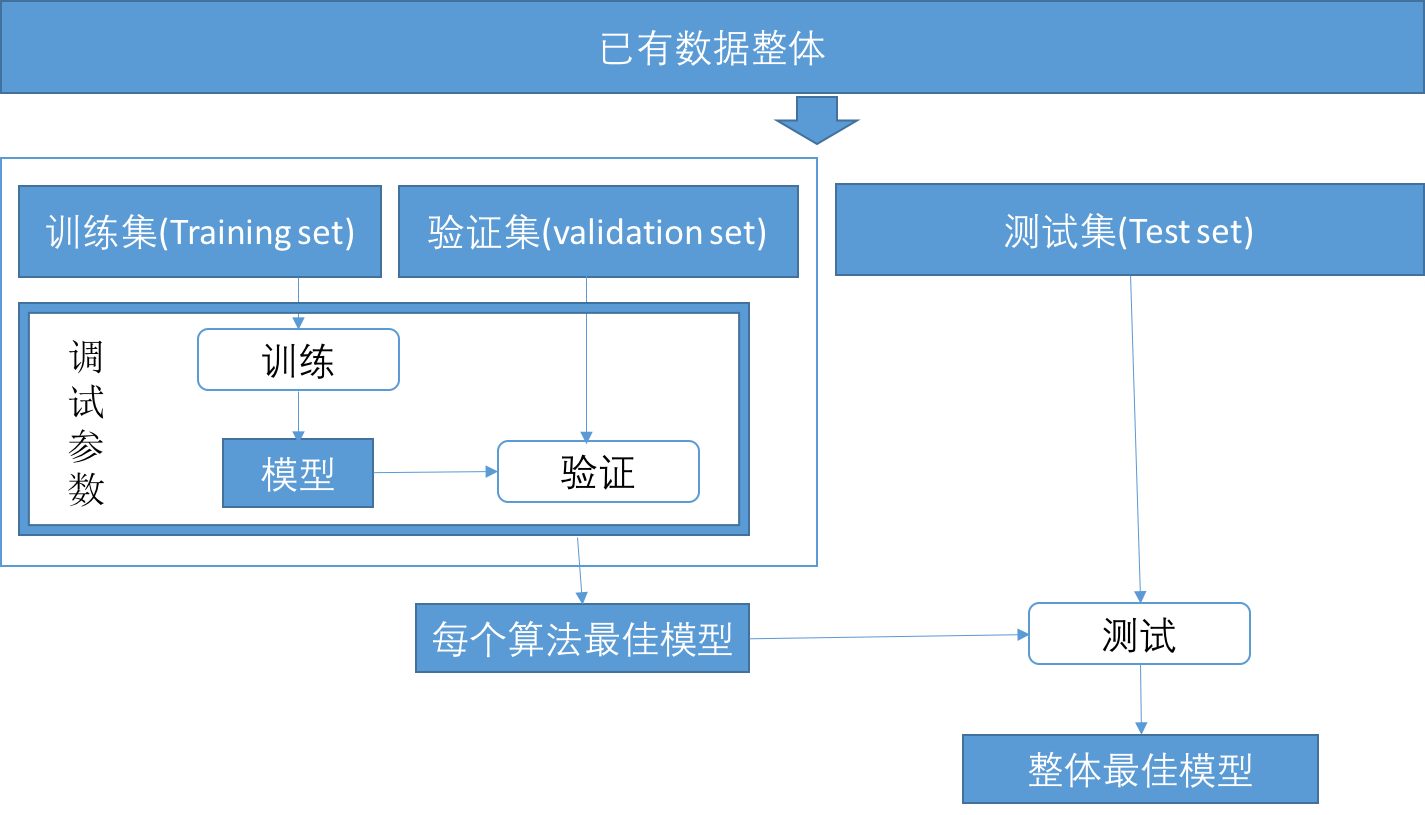
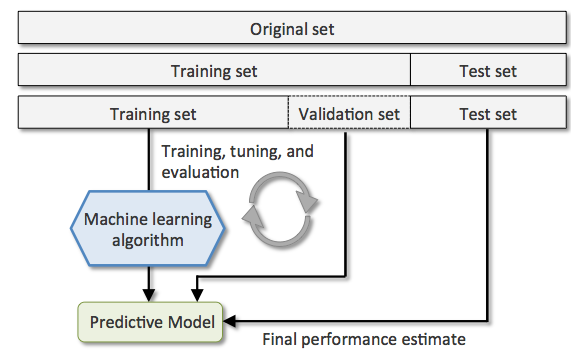
17.樣本要切割成三份:『訓練用,驗證用,測試用』樣本
(17-2)樣本切割成三份的比例:
18.迴圈的設定:訓練週期Epochs,批次Batch,批次尺寸Batch Size,迭代數Iterations
19.Keras常用的2種深度學習模型models
20.常用的3種神經網絡類型types:MLP,CNN,RNN
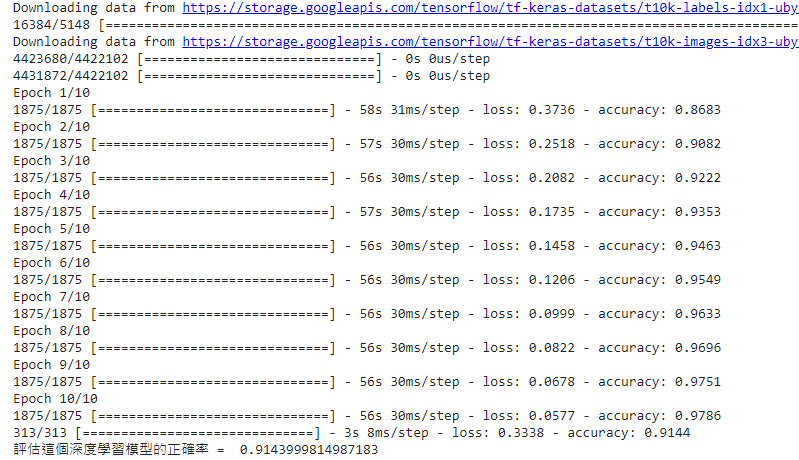
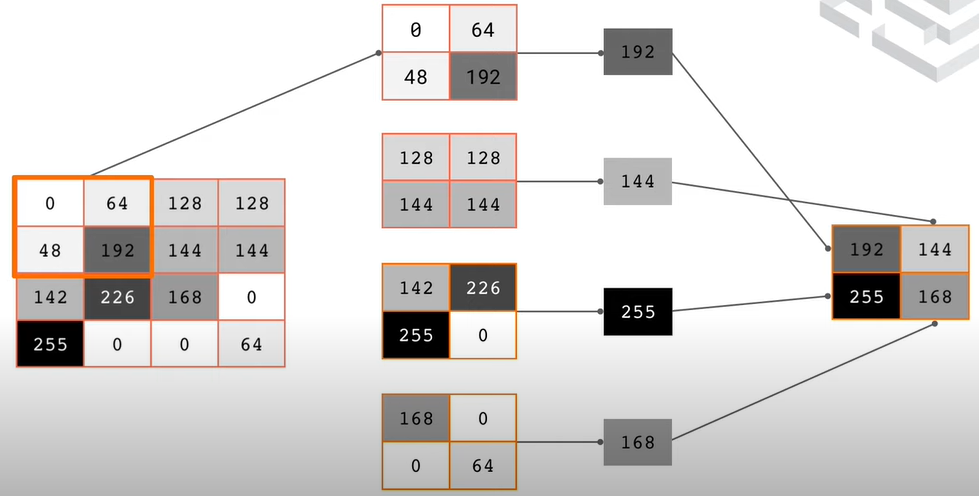
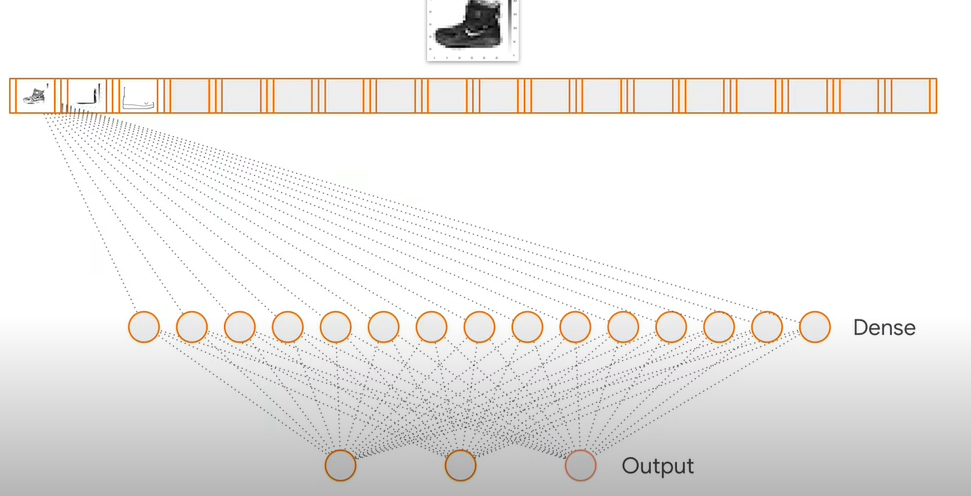
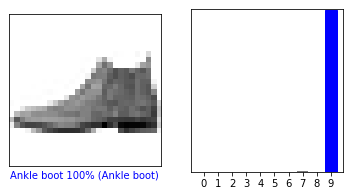
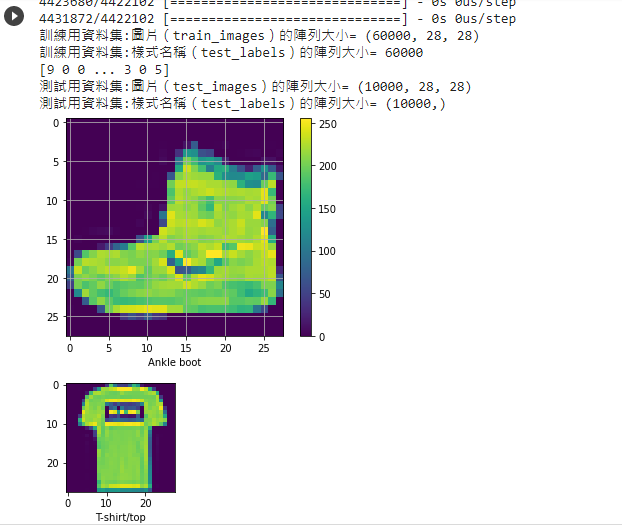
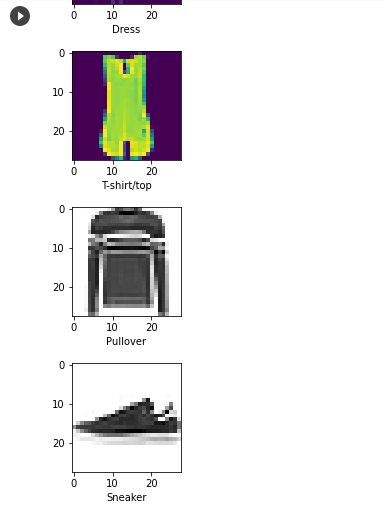
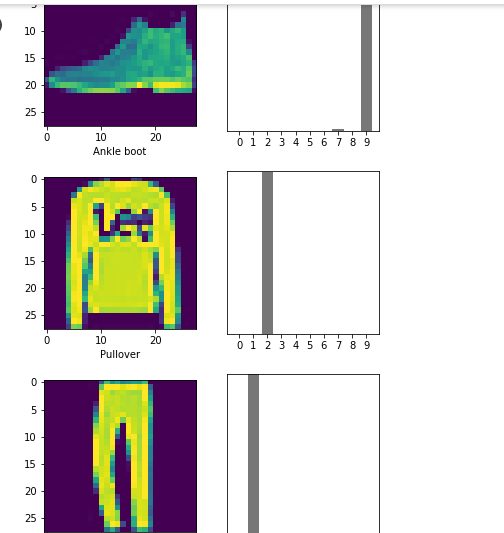
1.基本圖片分類:Basic classification: Classify images of clothing官網的教學範例:基本圖片分類:Basic classification: Classify images of clothing
model = tf.keras.Sequential(
model.fit(train_images, train_labels, epochs=10)
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
pred_classifications = model.predict(test_images)
☎take a look at the first prediction:
echo predictions[0];
array([2.9212106e-07, 1.6208847e-10, 1.3363140e-08, 2.7341349e-09,
5.5379962e-10, 4.5457238e-04, 4.2226111e-06, 4.4925120e-03,
5.8868943e-07, 9.9504781e-01], dtype=float32)
i = 0
程式碼 專案成果檔案.py ,
專案成果檔案.ipynb
chp11. keras多層感知器(MLP)的各種範例
目錄
範例11-1-a:糖尿病的識別與預測:讀入資料集檔案 範例11-1-b:建立糖尿病的神經網絡模型 範例11-1-c:把訓練資料先進行特徵標準化Standardization 範例11-1-d:在神經層使用權重初始器initializer
範例11-1-e:輸出向量改成2個(yes,no) 範例11-1-f:使用adam優化器optimizer試看看可否提高準確率 範例11-1-g:若樣本數不多,可縮小神經網絡尺寸,以提高準確率 範例11-1-h:把資料集分割成訓練資料集,測試資料集
範例11-1-i:如何找到最佳訓練週期epochs(看驗證資料的history圖) 範例11-1-j:使用validation_split=0.2參數,來自動分割驗證用資料集 範例11-1-k:顯示模型的預測值
目錄
範例11-2-a:預測波士頓房價Boston Housing price regression:讀入csv資料集 範例11-2-b:建立模型來訓練波士頓房價資料集 範例11-2-c:使用定義函數來『建立模型+編譯模型』:model=def bulid_mode() 範例11-2-d:當資料集數目少時可用k-摺疊交叉驗證法(k fold cross validation)
範例11-2-e:使用四層神經網絡,來降低誤差 範例11-2-f:由『驗證資料集』找出避免overfitting的『最佳週期』後,就只用『訓練資料集,測試資料集』重新訓練模型 範例11-2-g:同時一次儲存已經訓練好的模型『結構,權重』 範例11-2-h:一次讀入已經訓練好的模型『結構,權重』
範例11-2-i:分開儲存已經訓練好的模型『結構,權重』 範例11-2-j:分開讀入已經訓練好的模型『結構,權重』
目錄
範例11-3-a:鳶尾花資料集(The iris dataset)的多元分類:讀入csv資料集 範例11-3-b:繪圖(散佈圖,seabron繪圖庫):鳶尾花資料集 範例11-3-c:建立鳶尾花資料集(The iris dataset)的神經網絡模型
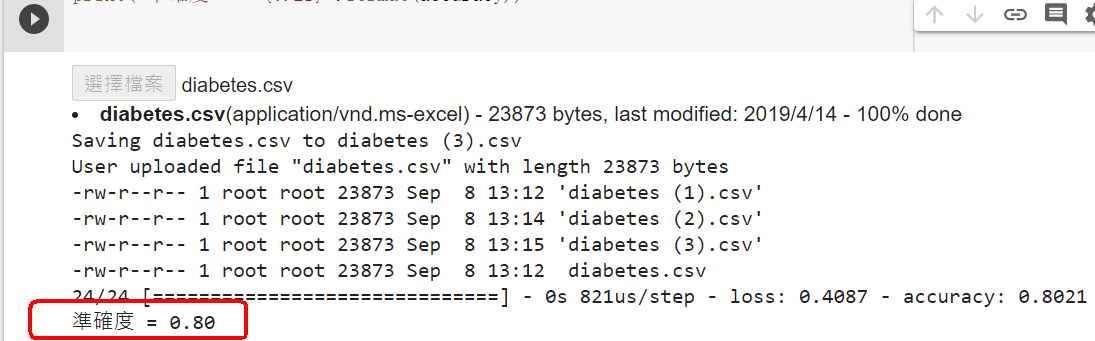
範例11-2-a:糖尿病的識別與預測:讀入資料集檔案利用python機器學習庫進行Kaggle皮馬印第安人糖尿病預測分析 Your First Deep Learning Project in Python with Keras Step-By-Step Using a Keras based neural network to predict diabetes Practical Deep Neural Network in Keras on PIMA Diabetes Data set [ML] 用 Keras 預測糖尿病
import pandas as pd
df = pd.read_csv("./diabetes.csv")
☎程式碼:程式碼(使用anaconda讀入資料集)
from google.colab import drive
☎程式碼:程式碼(在colaboratory的python讀入google drive裡的資料集)
#上傳diabetes.csv
☎程式碼:程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集) 下載pima印第安人糖尿病資料集 1.程式碼(使用anaconda讀入資料集) 2.程式碼(在colaboratory的python讀入google drive裡的資料集) 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-b:建立糖尿病的神經網絡模型利用python機器學習庫進行Kaggle皮馬印第安人糖尿病預測分析 Your First Deep Learning Project in Python with Keras Step-By-Step Using a Keras based neural network to predict diabetes Practical Deep Neural Network in Keras on PIMA Diabetes Data set [ML] 用 Keras 預測糖尿病
import tensorflow as tf
from tensorflow.keras.models import Sequential
1.程式碼(使用anaconda讀入資料集) 2.程式碼(在colaboratory的python讀入google drive裡的資料集) 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-c:把訓練資料先進行特徵標準化Standardization
X -= X.mean(axis=0)
import tensorflow as tf
from tensorflow.keras.models import Sequential
1.程式碼(使用anaconda讀入資料集) 2.程式碼(在colaboratory的python讀入google drive裡的資料集) 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-d:在神經層使用權重初始器initializer
model = tf.keras.models.Sequential()
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-e:輸出向量改成2個(yes,no)
model.add(tf.keras.layers.Dense(units=1, kernel_initializer="random_uniform",
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
# One-hot編碼
或是
# One-hot編碼
☎準則:
model.add(tf.keras.layers.Dense(units=2, kernel_initializer="random_uniform",
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-f:使用adam優化器optimizer試看看可否提高準確率如果數據是稀疏的, 建議選用『自適應方法』:即Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta, Adam 整體來講,Adam 是最好的選擇。 如果使用循環神經網絡模型RNN,
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-g:若樣本數不多,可縮小神經網絡尺寸,以提高準確率
model = tf.keras.models.Sequential()
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-h:把資料集分割成訓練資料集,測試資料集
#前690筆,是訓練用資料
#12.訓練模型(用X_train, Y_train來做訓練)
loss, accuracy = model.evaluate(X_train, Y_train)
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
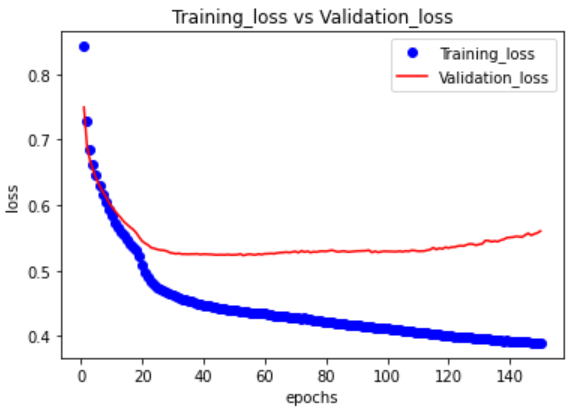
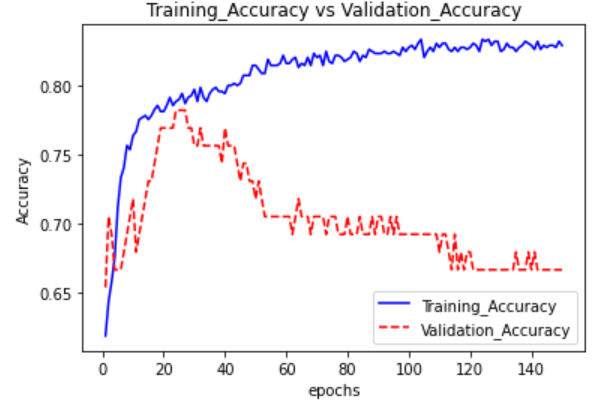
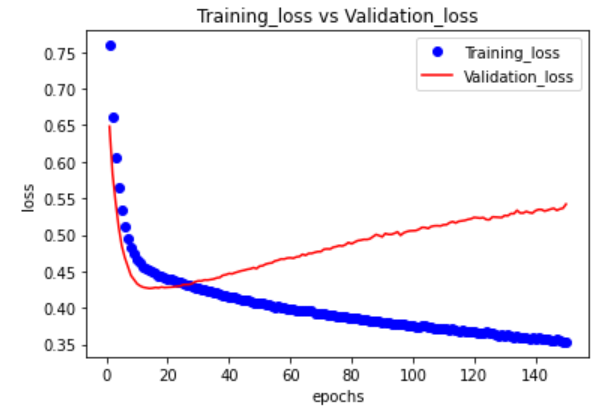
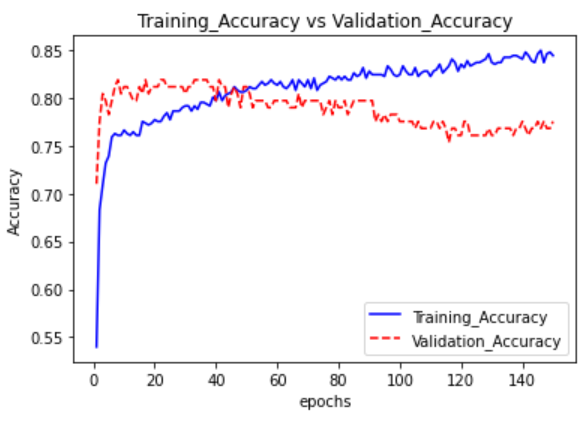
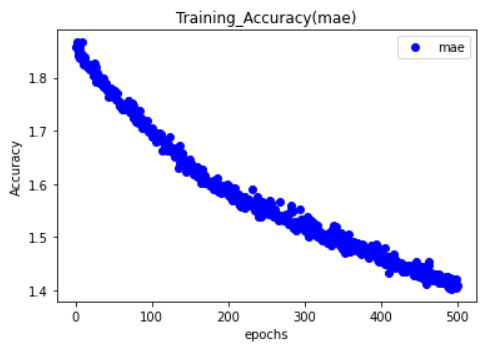
範例11-1-i:如何找到最佳訓練週期epochs(看驗證資料的history圖)
(2)為什麼除了『訓練資料集,測試資料集』外,還要有『驗證資料集』?
☎在history = model.fit(參數)裡面,加上參數validation_data=(X_test,Y_test)
#輸出訊息,多了兩個:val_loss驗證資料的損失,val_accuracy驗證資料的準確率
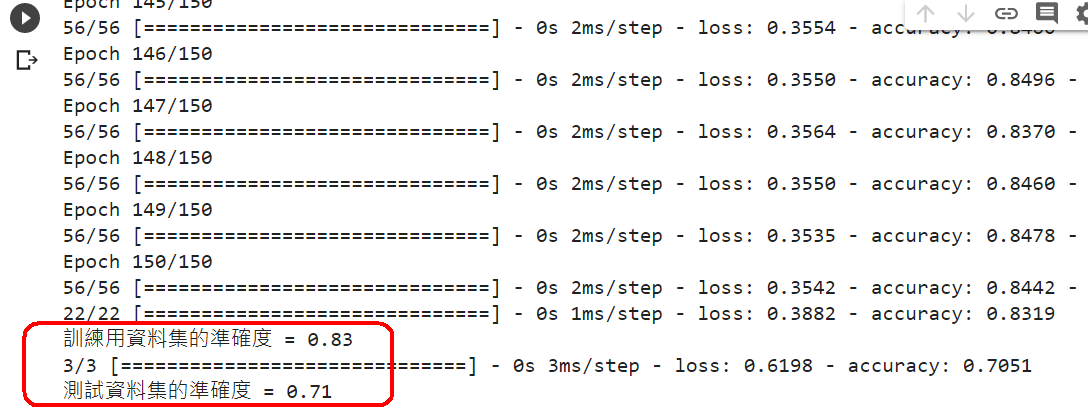
history = model.fit(X_train, Y_train, epochs=150, validation_data=(X_test,Y_test), batch_size=10, verbose=1)
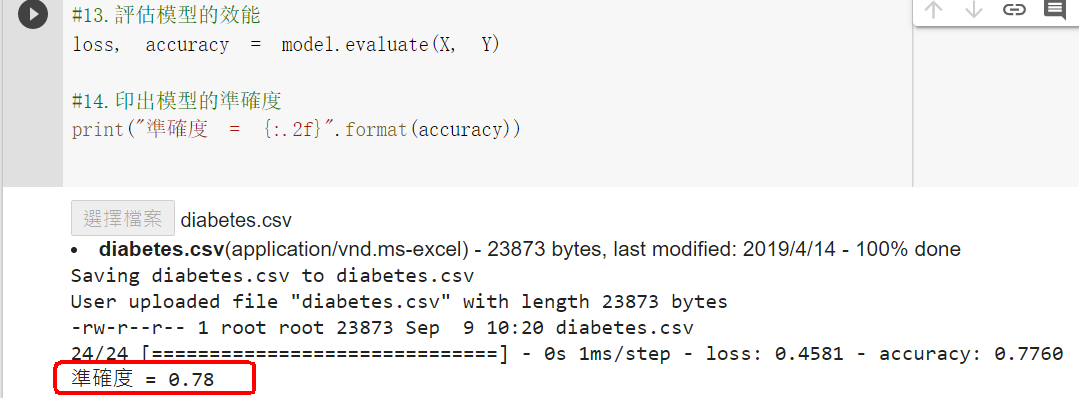
#14.評估模型的效能(比較用『訓練用資料集,測試資料集』的模型準確率)
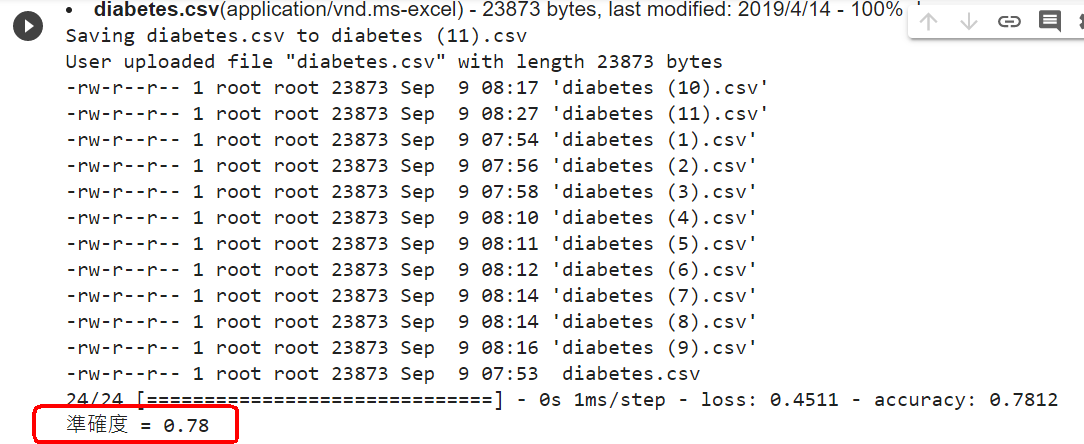
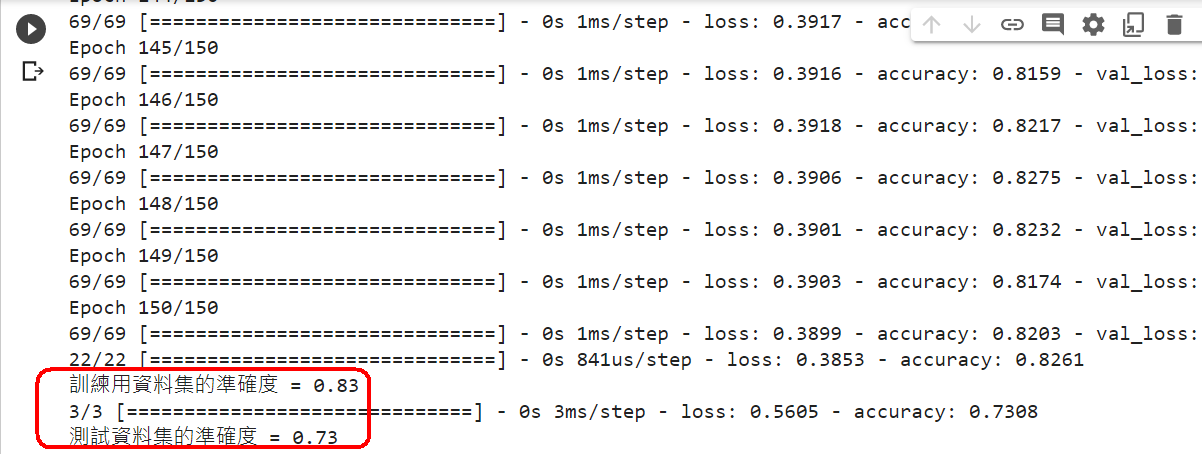
loss, accuracy = model.evaluate(X_train, Y_train)
print("訓練用資料集的準確度 = {:.2f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, Y_test)
print("測試資料集的準確度 = {:.2f}".format(accuracy))
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, "bo", label="Training_loss")
plt.plot(epochs, val_loss, "r", label="Validation_loss")
plt.title("Training_loss vs Validation_loss")
plt.xlabel("epochs")
plt.ylabel("loss")
plt.legend()
plt.show()
loss, accuracy = model.evaluate(X_train, Y_train)
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
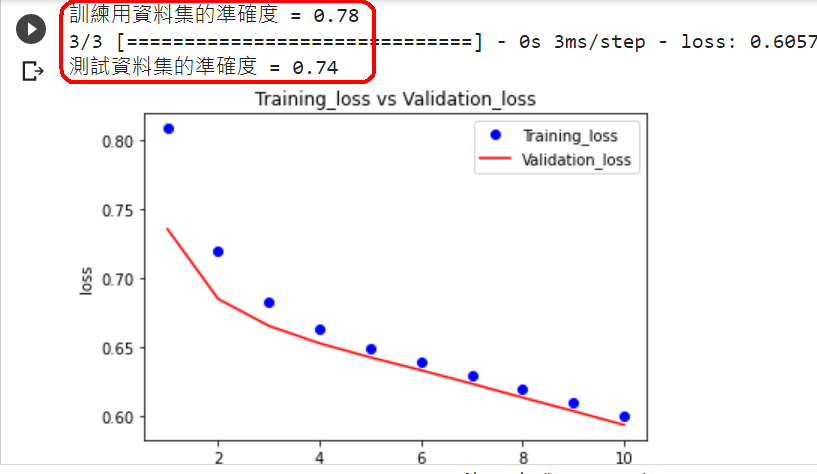
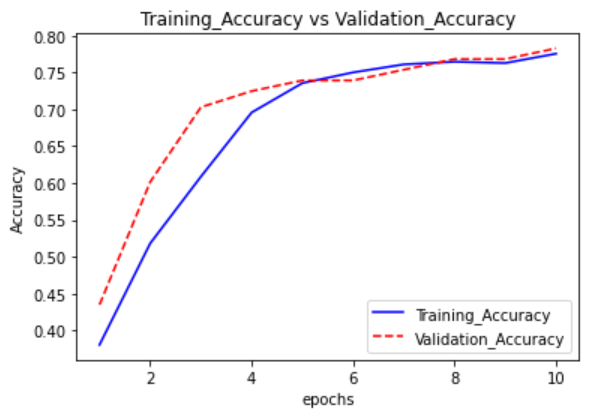
範例11-1-j:使用validation_split=0.2參數,來自動分割驗證用資料集
☎在history = model.fit(參數)裡面,加上參數validation_split=0.2參數,就會把X_train, Y_train訓練資料集中,自動分割出20%當作驗證資料集
#輸出訊息,多了兩個:val_loss驗證資料的損失,val_accuracy驗證資料的準確率
history = model.fit(X_train, Y_train, epochs=150, validation_split=0.2, batch_size=10, verbose=1)
#14.評估模型的效能(比較用『訓練用資料集,測試資料集』的模型準確率)
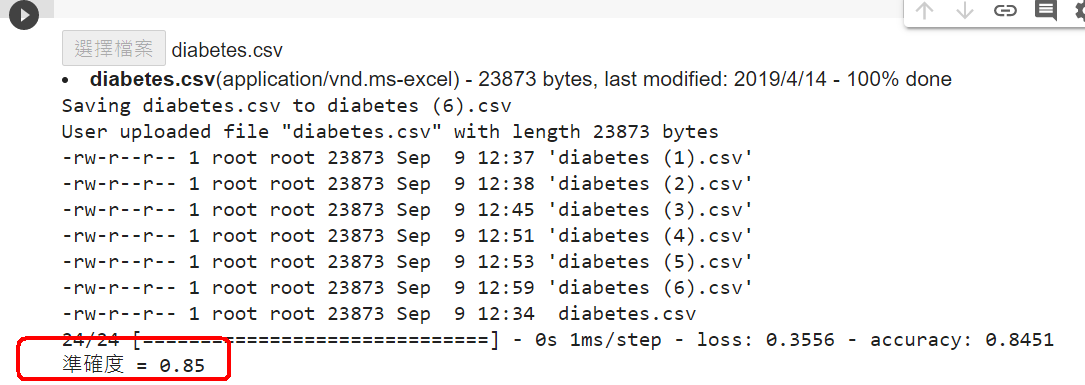
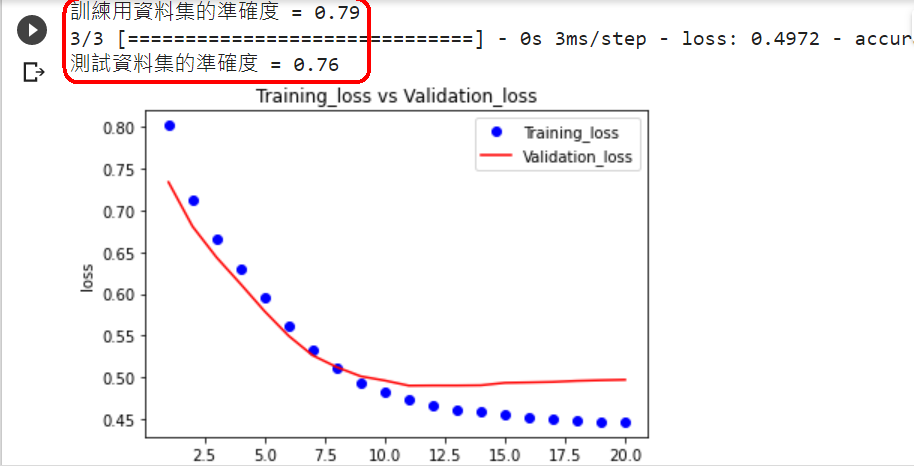
loss, accuracy = model.evaluate(X_train, Y_train)
print("訓練用資料集的準確度 = {:.2f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, Y_test)
print("測試資料集的準確度 = {:.2f}".format(accuracy))
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-1-k:顯示模型的預測值
☎使用X_test,預測Y_pred
#1.將資料分割成輸入的訓練資料X,和標籤資料Y
#1.將資料分割成輸入的訓練資料X,和標籤資料Y
模型預測糖尿病(比較,輸出一個向量,輸出二個向量)的程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集) 模型預測糖尿病(輸出二個向量)的程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
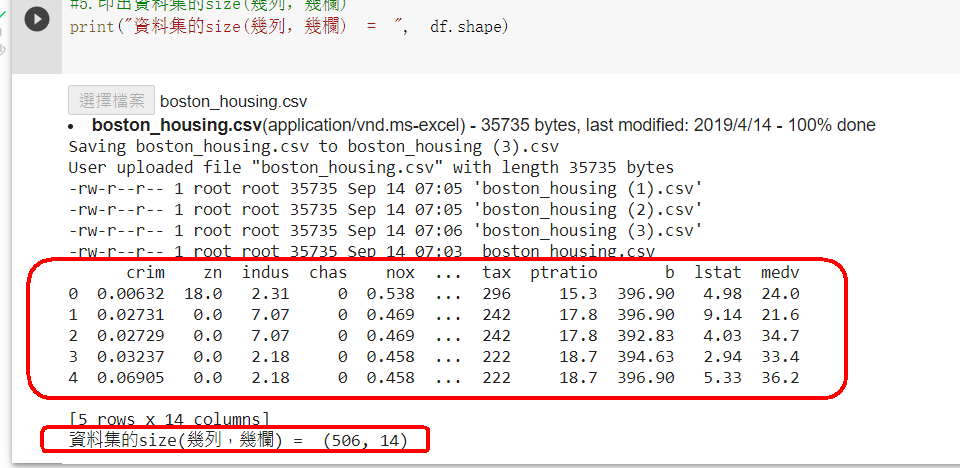
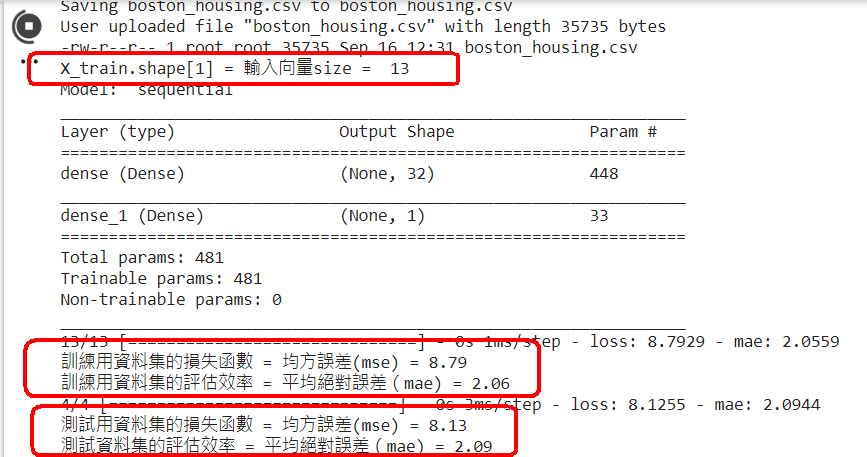
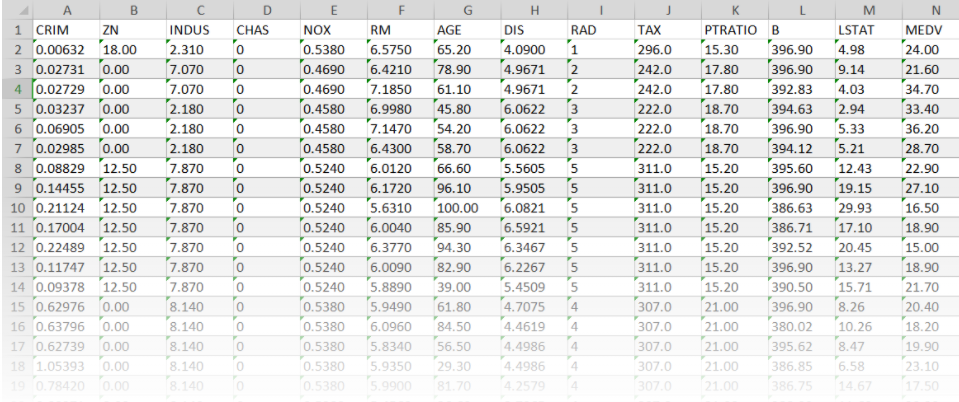
範例11-2-a:預測波士頓房價/Boston Housing price regression:讀入csv資料集Regression with Keras 回归问题(boston_housing数据为例) Tutorial: Basic Regression TENSORFLOW 2 – REGRESSION ON THE BOSTON HOUSING DATASET. PART 2 – KERAS CALLBACKS 浅入浅出用Keras实现波士顿房价预测 【keras實戰】波士頓房價預測 从零开始学keras之预测房价
import pandas as pd
df = pd.read_csv("./diabetes.csv")
from google.colab import drive
#上傳diabetes.csv
下載波士頓房價資料集
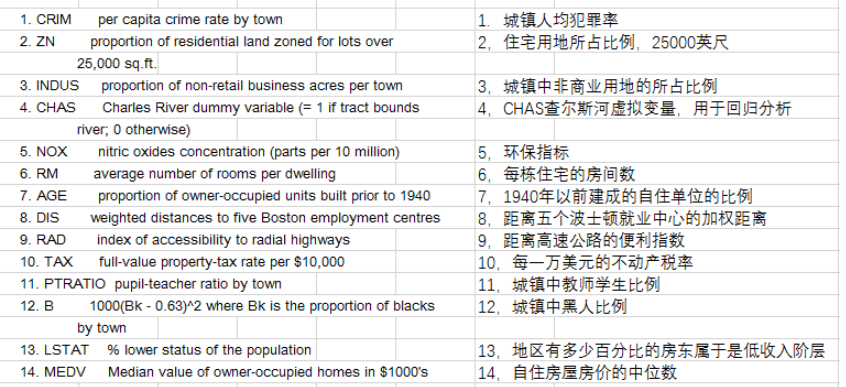
No
属性
数据类型
字段描述
1
CRIM
Float
城镇人均犯罪率
2
ZN
Float
占地面积超过2.5万平方英尺的住宅用地比例
3
INDUS
Float
城镇非零售业务地区的比例
4
CHAS
Integer
查尔斯河虚拟变量 (= 1 如果土地在河边;否则是0)
5
NOX
Float
一氧化氮浓度(每1000万份)
6
RM
Float
平均每居民房数
7
AGE
Float
在1940年之前建成的所有者占用单位的比例
8
DIS
Float
与五个波士顿就业中心的加权距离
9
RAD
Integer
辐射状公路的可达性指数
10
TAX
Float
每10,000美元的全额物业税率
11
PTRATIO
Float
城镇师生比例
12
B
Float
1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例
13
LSTAT
Float
人口中地位较低人群的百分数
14
MEDV
Float
(目标变量/类别属性)以1000美元计算的自有住房的中位数
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
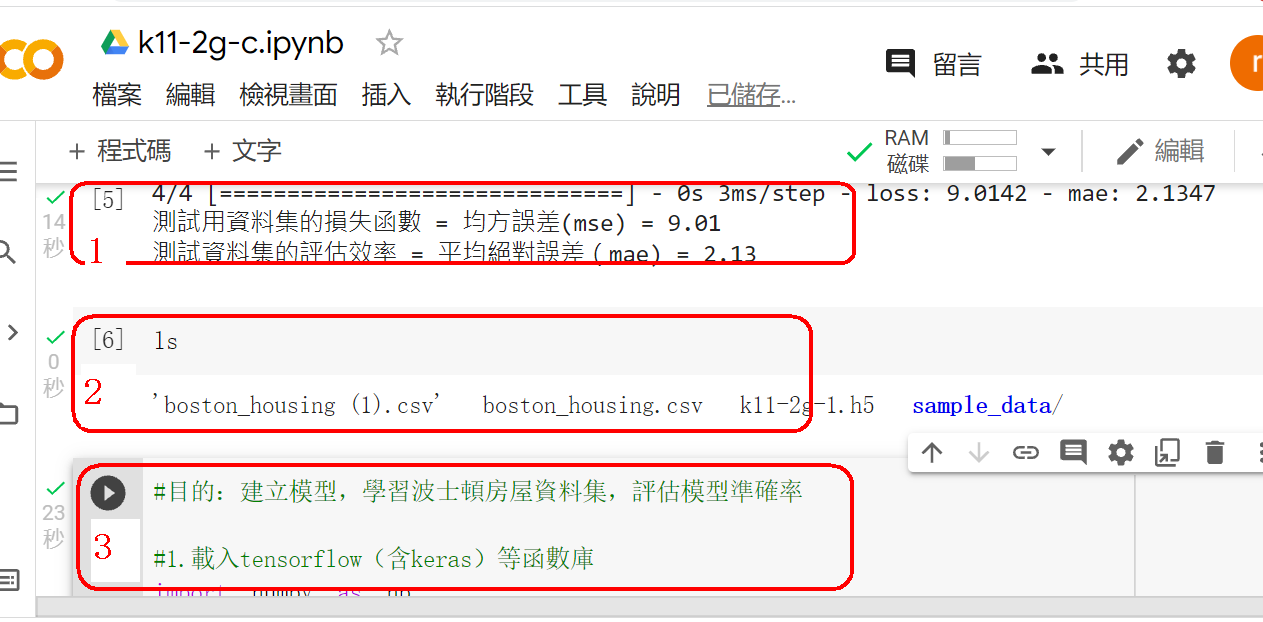
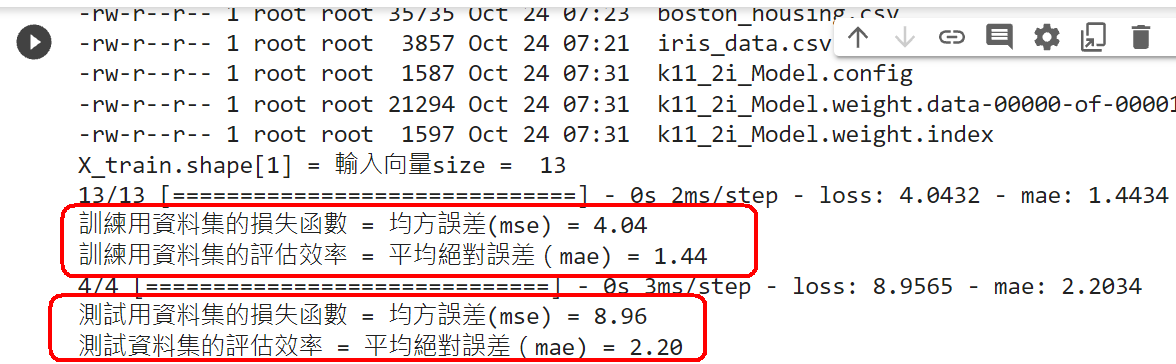
範例11-2-b:建立模型來訓練波士頓房價資料集Regression with Keras 回归问题(boston_housing数据为例) Tutorial: Basic Regression TENSORFLOW 2 – REGRESSION ON THE BOSTON HOUSING DATASET. PART 2 – KERAS CALLBACKS 浅入浅出用Keras实现波士顿房价预测 【keras實戰】波士頓房價預測 从零开始学keras之预测房价 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-2c:使用定義函數來建立模型+編譯模型:model=def bulid_mode()
def build_model():
☎注意:最後要加上『return model』
# 宣告一個模型變數
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
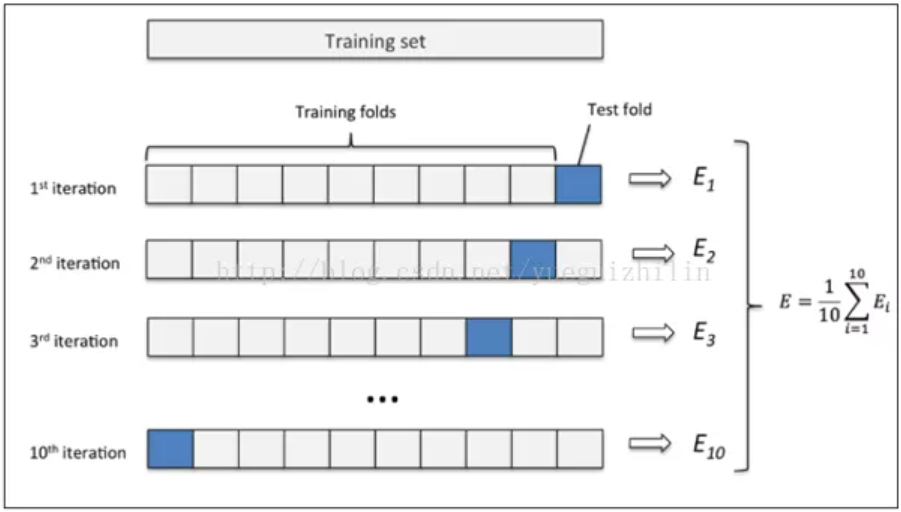
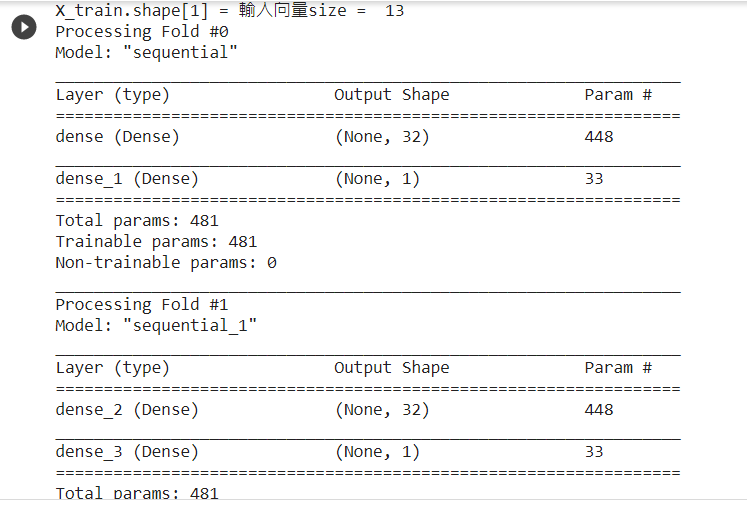
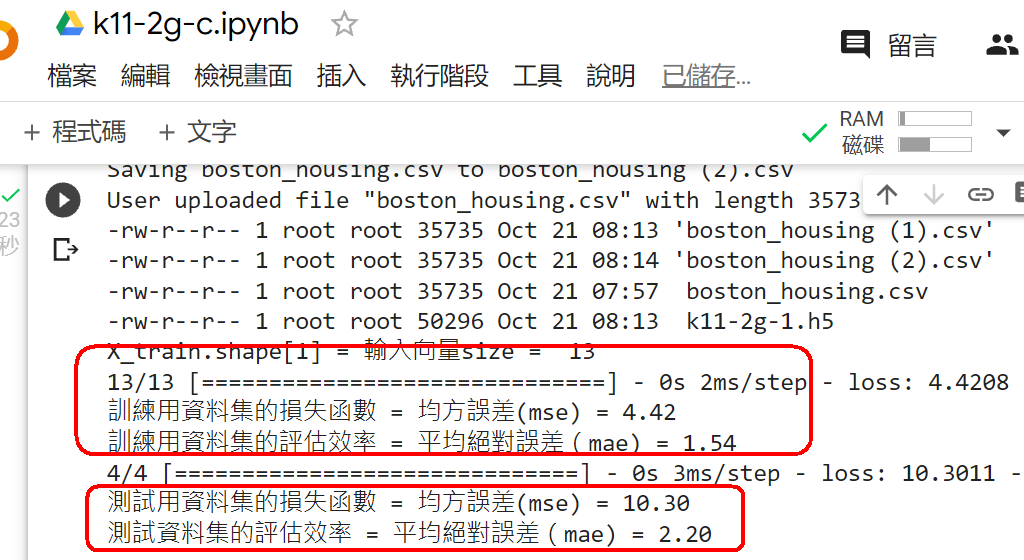
範例11-2-d:當資料集數目少時可用k-摺疊交叉驗證法(k fold cross validation)
(11-2c-1)為什麼除了『訓練資料集,測試資料集』外,還要有『驗證資料集』?
程式碼 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
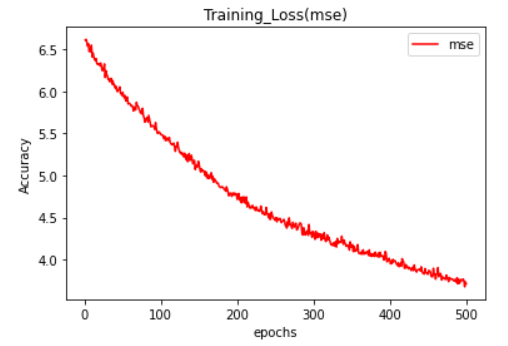
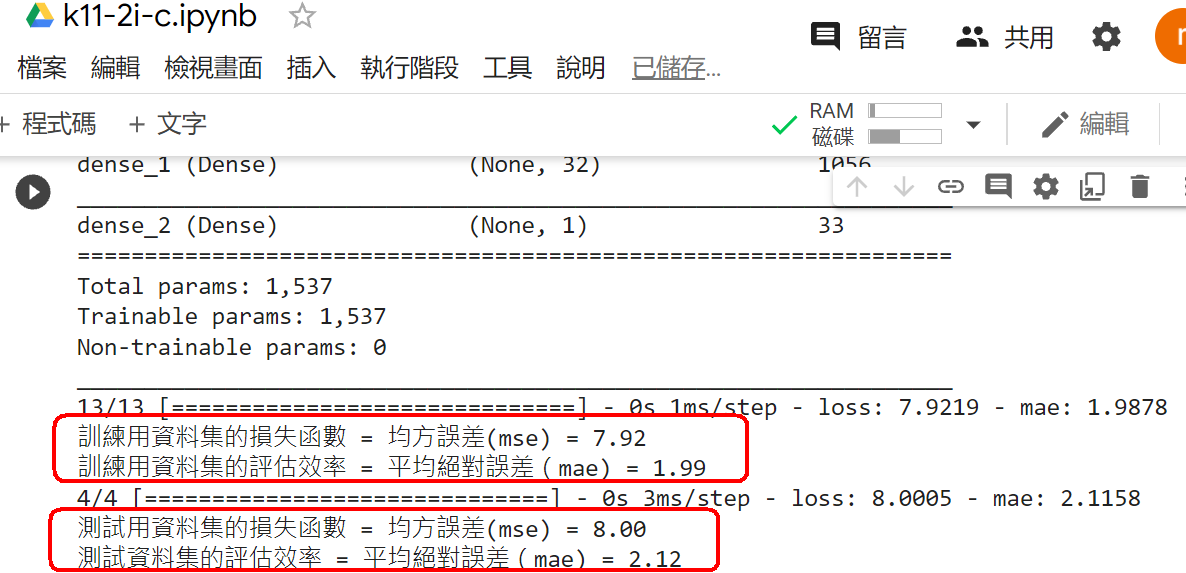
範例11-2-e:使用四層神經網絡,來降低誤差
(11-2c-1)程式碼:
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
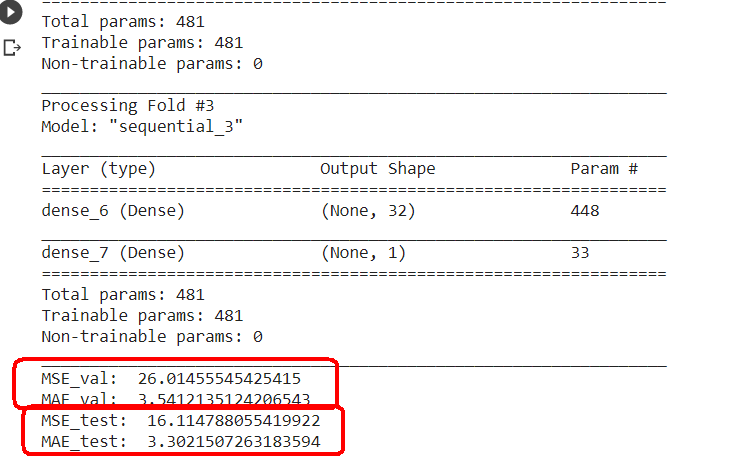
範例11-2-f:由『驗證資料集』找出避免overfitting的『最佳週期』後,就只用『訓練資料集,測試資料集』重新訓練模型
(11-2f-1)為什麼除了『訓練資料集,測試資料集』外,還要有『驗證資料集』?
(11-2f-1)程式碼:
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
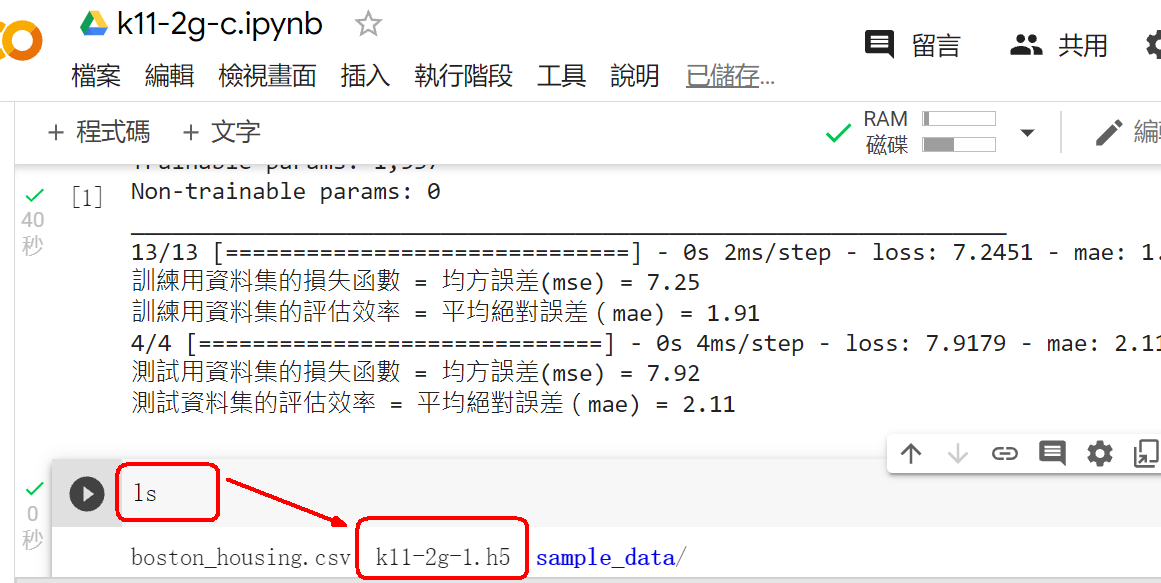
範例11-2-g:同時一次儲存已經訓練好的模型『結構,權重』
(11-2g-1)儲存已經訓練好的模型的『結構,權重』參數,有兩種方法:
☎(1)同時一次儲存模型的『結構,權重』
3.程式碼(anaconda程式碼)
範例11-2-h:一次讀入已經訓練好的模型『結構,權重』
(11-2h-1)儲存已經訓練好的模型的『結構,權重』參數,有兩種方法:
☎(1)同時一次讀入模型的『結構,權重』
3.程式碼(anaconda程式碼)
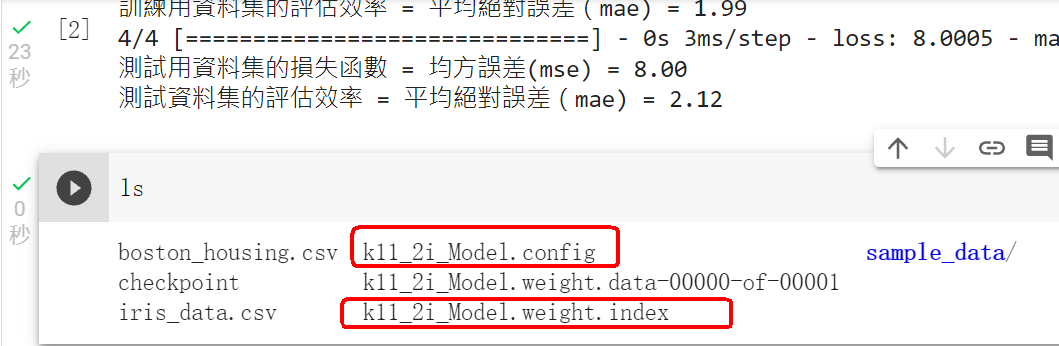
範例11-2-i:分開儲存已經訓練好的模型『結構,權重』
(11-2i-1)儲存已經訓練好的模型的『結構,權重』參數,有兩種方法:
☎(1)同時一次儲存模型的『結構,權重』
3.程式碼(anaconda程式碼)
範例11-2-j:分開讀入已經訓練好的模型『結構,權重』
(11-2j-1)儲存已經訓練好的模型的『結構,權重』參數,有兩種方法:
☎(1)同時一次儲存模型的『結構,權重』
3.程式碼(anaconda程式碼)
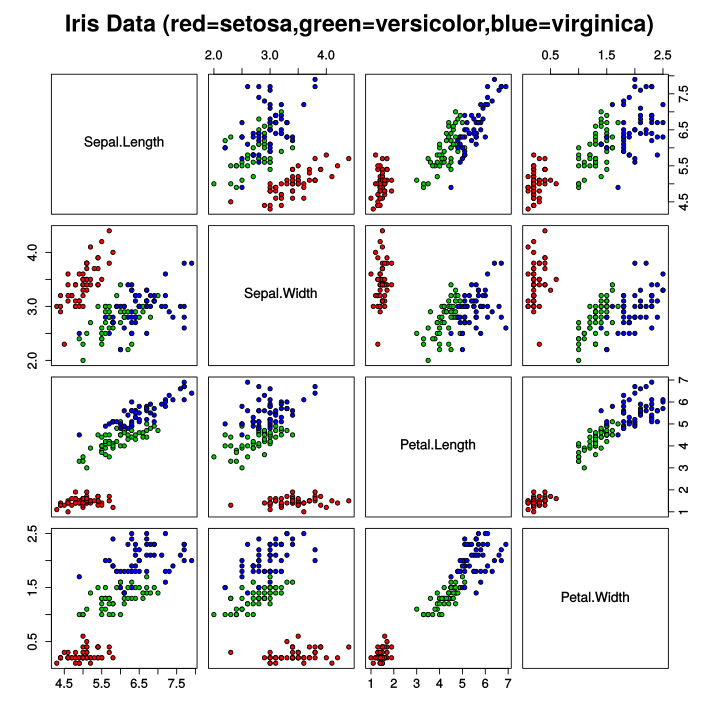
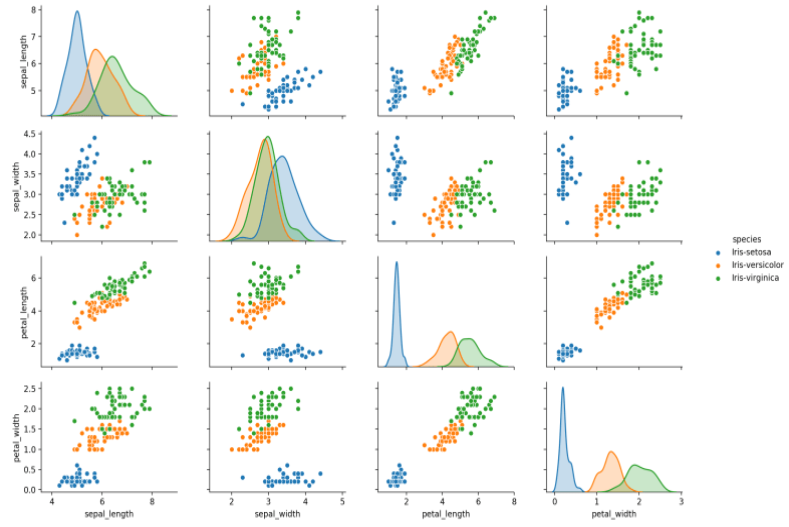
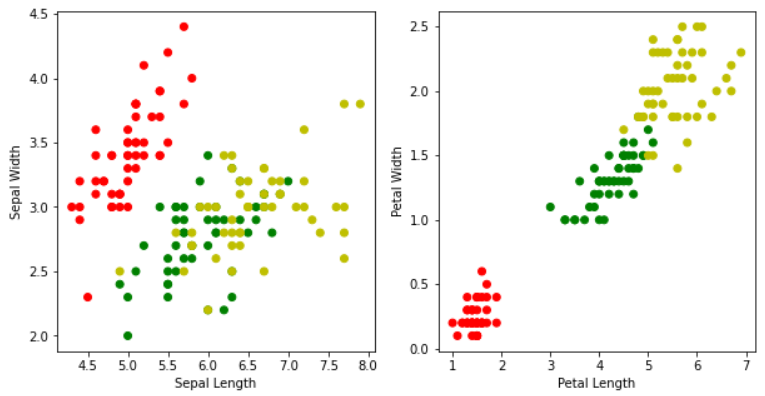
範例11-3-a:鳶尾花資料集(The iris dataset)的多元分類:讀入csv資料集Keras之對鳶尾花識別 Keras多分類例項:鳶尾花 Classifying the Iris Data Set with Keras Deep Learning with Keras on Iris Dataset Keras之對鳶尾花識別
了解數據集
鳶尾花數據集是一個經典的機器學習數據集,非常適合用來入門。下載鳶尾花數據集
花萼長度:sepal_length
花萼寬度:sepal_width
花瓣長度:petal_length
花瓣寬度:petal_width
鳶尾花種類:target(包括:setosa, versicolor, virginica)
該表確定了鳶尾花品種,品種必須是下列任意一種:
山鳶尾 Iris-Setosa(0)
雜色鳶尾 Iris-versicolor(1)
維吉尼亞鳶尾 Iris-virginica(2)
數據集中三類鳶尾花各含有50個樣本,共150各樣本
import pandas as pd
df = pd.read_csv("./diabetes.csv")
from google.colab import drive
#上傳diabetes.csv
下載鳶尾花csv資料集 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
範例11-3-b:繪圖(散佈圖,seabron繪圖庫):鳶尾花資料集Keras之對鳶尾花識別 Keras多分類例項:鳶尾花 Classifying the Iris Data Set with Keras Deep Learning with Keras on Iris Dataset Keras之對鳶尾花識別 3.程式碼
df = pd.read_csv("./iris_data.csv")
教學文件
pip install seaborn
sns.relplot(x="total_bill", y="tip", data=tips)
import seaborn as sns
3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)
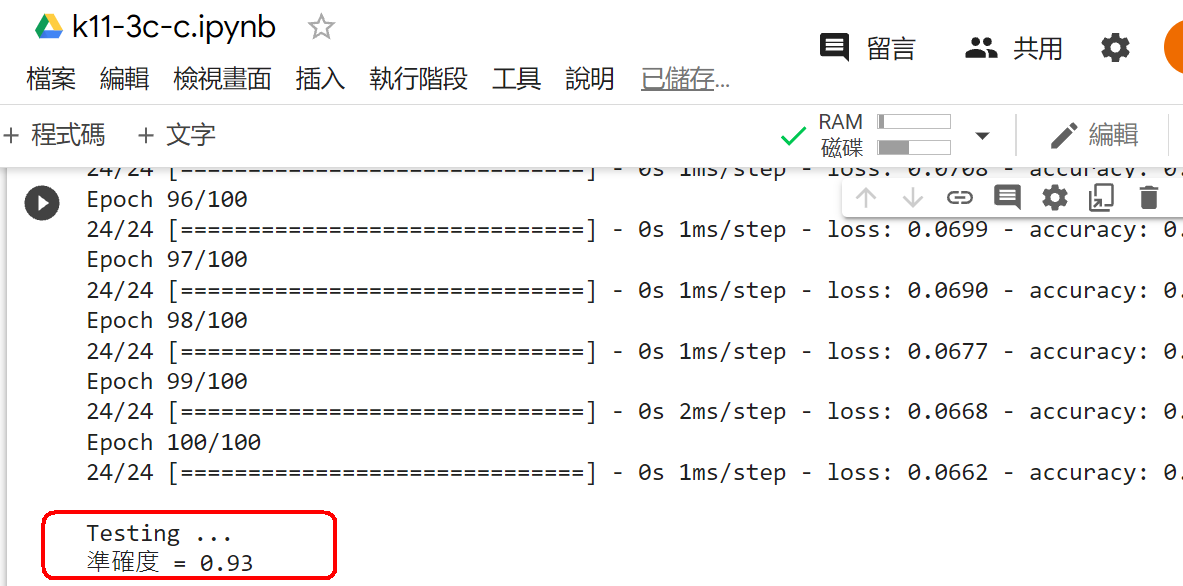
範例11-3-c:建立鳶尾花資料集(The iris dataset)的神經網絡模型,並輸入結構與權重檔案Keras之對鳶尾花識別 Keras多分類例項:鳶尾花 Classifying the Iris Data Set with Keras Deep Learning with Keras on Iris Dataset Keras之對鳶尾花識別 3.程式碼(在colaboratory的python讀入個人電腦硬碟裡的資料集)